机器学习中,对于离散的数据可以做分类问题,那对于连续的数据就是做回归问题,这里对一元线性回归和多元线性回归做一个简介,帮组理解。
回归分析:从一组样本数据出发,确定变量之间的数学关系式,对这些关系式的可信程度进行各种统计检验,并从影响某一特定变量的诸多变量中找到影响效果显著和不显著的变量,同时利用关系式,根据一个和多个变量来预测或控制另一个特定变量的取值,并给出预测的精准程度。
变量之间的关系有两种:一种是确定性关系,能直接给出y = f(x),确定唯一的y,一种是相关关系,变量之间有关系,但是不能用函数表示。但是在平均意义下有一定的变量相关关系。
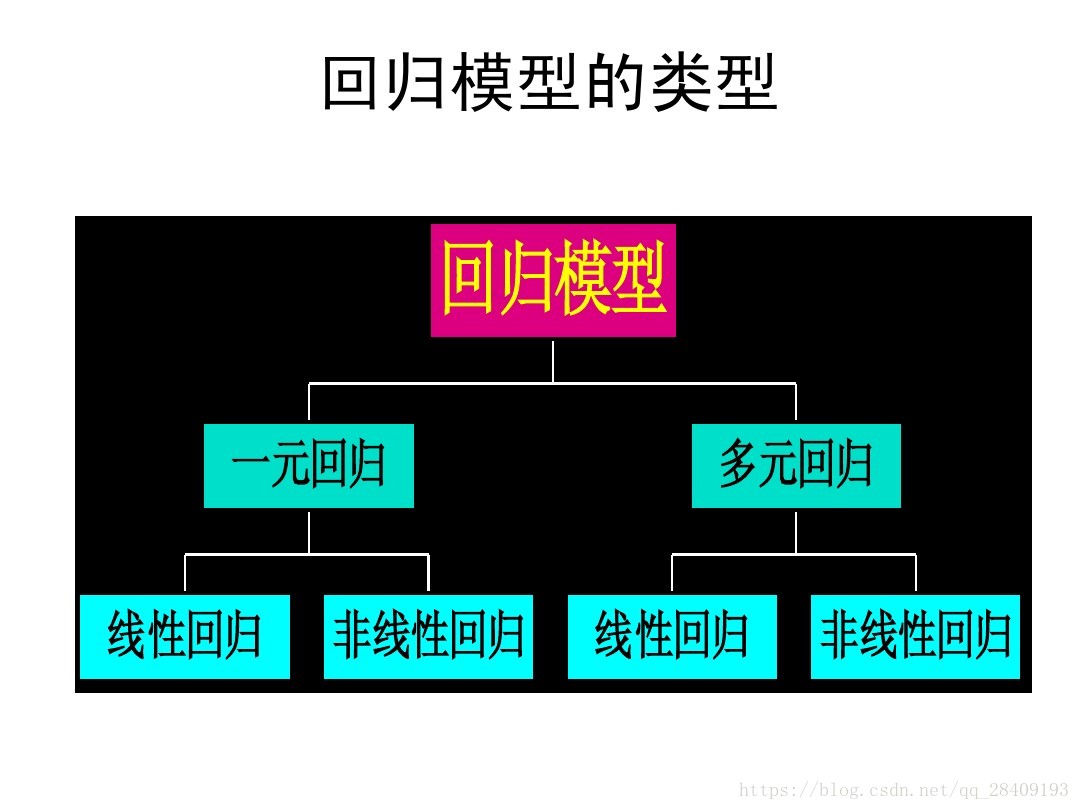
(注:图是参考资料里边的)
一元线性回归模型:描述因变量Y如何依赖自变量X的方程,这是自变量只有一个,称之为一元线性回归模型。
y = w0+w1x
多元线性回归模型 :描述因变量Y如何依赖自变量x1,x2,x3...的方程,此时自变量有多个,称之为多元线性回归模型。
y = w0 +w1x1 + w2x2 +w3x3 +...
w1,w2,w3...称为偏回归系数
回归的目的是预测数值型的目标值。最直接的方法就是依据输入写出一个目标值的计算公式。这就是回归方程,公式为y=wX,其中w是回归系数,求这些回归系数的过程就是回归。这里的回归是多元线性回归,现在的问题是,手里有一些X和对应的y,怎么能找到w呢?一个常用的方法是找出使误差最小的w。这里的误差指的是预测值和真实值之间的差值,使用误差的简单累加使得该误差的简单累加将使得正差值和负差值相互抵消,所以我们采用平方误差。
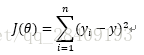

求解线性回归分为两类:一类是正规方程的求解,一个是基于梯度下降的求解。这里给出的是正规方程的求解过程。
对损失函数求解最小值计算化简为(这里推导过程参考正规方程计算,摘自博客chenlin41204050的博客(链接:https://blog.csdn.net/chenlin41204050/article/details/78220280):
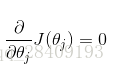
转换为矩阵运算,设有m个训练实例,每个实例有n个特征,则X为:

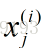
特征参数(回归系数): 输出变量Y:
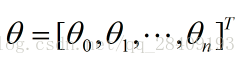
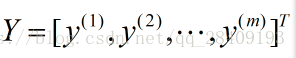
损失函数可以写为:
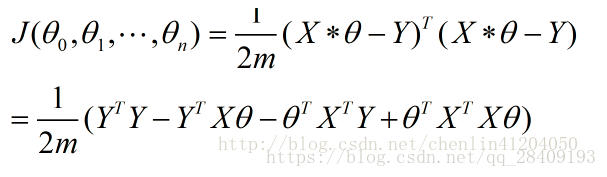
求偏导:


其中第一项结果为0,其他计算:
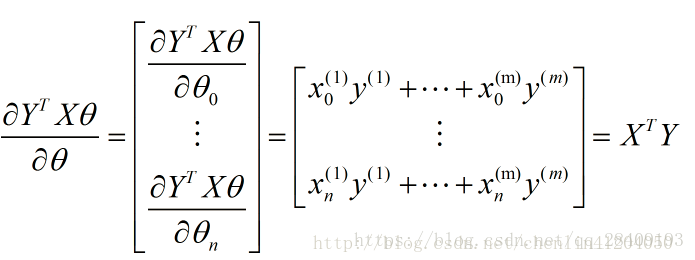
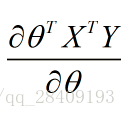
最后一项:

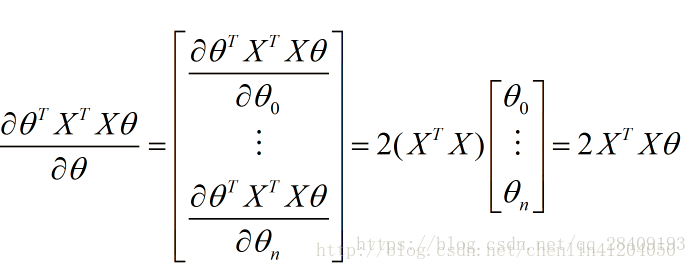
故最后结果为:

这里用的是最小二乘法,也可以用梯度下降实现线性回归。最后的化简式子中,对矩阵的求逆不能为0,即行列式不能为0。如果没有检查行列式是否为0就试图计算矩阵的逆,将会出现错误。之前一直找资料想知道公式的推导过程,终于找到了,鄙人实在不太会用各种数学公式的工具使用,就盗用了他们的图,希望不影响浏览。
最小二乘法
最小二乘法的用途是求未知数据,并使得这些数据与实际数据之间的误差达到最小。另一个方面可以进行曲线拟合。最小二乘法在估计的时候我们可以首先画出散点图看是否有线性关系,在做进一步的分析。
高中我们所学的知道两点求直线就是用到了最小二乘法,方程为y=ax+b,已知有点(x1,y1),(x2,y2)两个点,利用误差最小可知:
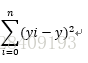
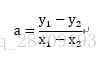

局部加权线性回归
线性回归的一个问题是有可能出现欠拟合的现象,因为它求的是具有最小均方差的无偏估计。显而易见,如果模型欠拟合将不能取得最好的预测效果。所以引入局部加权线性回归,在算法中,我们给预测点附近的每一个点赋予一定的权重,在此方法中,我们使用‘核’来对附近的点赋予更高的权重,常用的是高斯核。
岭回归
如果特征比样本点还多,也就是说输入数据的矩阵x不是满秩矩阵,非满秩矩阵会在求逆时出现问题,所以引入岭回归,简单地说,就是在矩阵加一个常数和单位矩阵,该常数越大,方差越小,偏差越大,通过引入该惩罚项,能够减少不重要的参数,这个技术在统计学中叫做缩减。
在进入岭回归和lsaao回归的时候引入了正则化的概念,其中岭回归用了L2正则化,lasso用了L1正则化,正则化将会在以后讲解。
这里重新引入了一个数据标准化的过程,和归一化是不一样的。目的有一定的相似性。