前言
RNN擅长解决的问题是连续的序列,且序列的长短不一,比如基于时间的序列:一段段连续的语音等。这些序列比较长,且长度不一,比较难直接拆分成一个个独立的样本通过DNN/CNN进行训练。
而RNN由于其独有的结构和优势,能够处理DNN/CNN所不能及的问题。
RNN的5种不同架构
声明:下列图中的方块或者圆圈都代表一个向量。
one2one:
一个输入对应一个输出。
one2many:
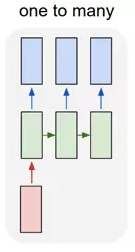


一个输入对应多个输出,这个架构多用于图片的对象识别,即输入一个图片,输出一个文本序列(来阐述这个图片)。
many2one:


多个输入对应一个输出,多用于文本分类或视频分类,即输入一段文本或视频片段,输出类别。
N2N
这是最经典的RNN结构


从这里可以看出,它要求序列的输入输出是等长的。
N2M / Encoder-Decoder / Seq2Seq:
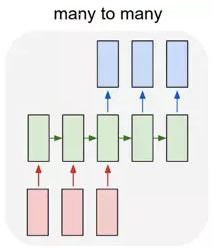

这种结构是RNN最重要的一个变种,广泛用于机器翻译,输入一个文本,输出另一种语言的文本。文本摘要,输入一段文本序列,输出这段文本序列的摘要序列。阅读理解,将输入的文章以及答案分别进行编码,最后再对其进行解码得到答案。语音识别,输入语音信号,输出的是文字序列。这里已经没有N2N序列等长的要求,在后面会进一步对该种模型进行阐述。
RNN模型与前向传播
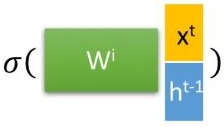
RNN是基于序列的,它对应的输入为对应的样本序列中的时间步t对应的
。而
代表t位置的隐藏状态,由
和t-1位置的隐藏状态
决定。
主流模型如下图
这些循环使RNN可以被看做同一个网络在不同时间步的多次循环,每个神经元会把更新的结果传递到下一个时间步。这就是RNN的正向传播,依次按照时间的顺序计算一次即可。
和
分别代表序列时间步t-1和t+1时训练样本的输入。
对任意一个序列时间步t,隐藏状态由
和
得到:
.................................... (0)
为激活函数,这里一般为tanh或者Relu,b为偏置。这个公式就可以理解为
,现有的输入+过去的记忆,也正是由于这个,使RNN具有了记忆能力。
这里处采用Pascanu等人的论文On the difficulty of training Recurrent Neural Networks中的定义,即认为
........................................ (1)
这两种方法其实是等价的,只是前一种表述把隐层状态定义成激活后的值,后一种表述把隐层定义成激活前的值,这里采用后一种方式是因为它稍微好算一点。
U:输入层到隐藏层直接的权重
W:隐藏层到隐藏层的权重
V:隐藏层到输出层的权重
U,W,V这三个矩阵是模型的线性关系参数,在整个RNN网络的每一步中是共享的,也正是因为共享,才体现了RNN模型的“循环反馈”的思想。
输出的表达式比较简单:
最终在时间步t时我们预测输出为:
通常RNN是分类模型,所以这里的激活函数一般是softmax/sigmoid。
误差函数可以量化模型当前损失,比如交叉熵损失函数或平方误差,即
和
的差距。
这个公式的理由是,总的误差等于每一步的误差加起来。
RNN与反向传播(BPTT :Back Propagation Trough Time)
我们希望通过反向传播来更新和优化RNN的权重,而RNN的权重分布在U、W、V三个矩阵中。
所以问题在于如何求解各个权重的梯度,即
这几个公式的理由是,对一元函数来说,和的导数等于导数的和。根据多元函数偏导数的定义,很容易推广到多元函数上,进而推广到矩阵求导上。

用表示
与
之间的转移矩阵
,则由前述的等价变换公式(1)可得
..................................(2)
这里需要明确指出,RNN中同样的权重在各个时间步共享,最终的梯度等于各个时间步的梯度的和;而MLP/CNN中不同层有不同的参数,各是各的梯度。
想要计算损失函数对隐层的导数,先计算
................................................(3)
根据多次复合的向量求导法则,可以得到任意时刻的偏导
...................................................(4)
再将其代入到(2)中,就能得到最终结果
.....................................................................(5)
同理,根据(1)还可以得到,
,都可根据类似(2)得到结果。
RNN的缺陷 :梯度爆炸与梯度消失
RNN的一个核心思想是将以前的信息连接到当前的任务中来,比如考虑一个语言模型,我们想通过前面的单词预测接下来的单词,如果我们想预测句子“the clouds are in the sky”中的最后一个单词,不需要更多的上下文信息——很明显下一个单词应该是sky。当前位置与相关信息所在位置之间的距离相对较小,RNN可以被训练来使用这样的信息。

但是随着距离的增大,比如说预测一个很长的句子“I grew up in France… I speak fluent French”中的最后一个单词,一般来说,上述图中的每个X都代表的是一个词的向量,比如X0代表“I”的词向量,X1代表“X1”的词向量,这个向量可以通过词袋模型的one-hot编码来表征,也可以通过经过语料训练的词向量来表示。由于“French”需要“France”这个位置更远的上下文信息,实际上,相关信息和需要该信息的位置之间的距离可能非常远。
随着距离的增大,RNN对于如何将这样的信息连接起来成为了一个严重的问题。

如何将这个事实通过公式来反映本质呢?
我们通过将公式(2)(3)(4)结合来看,若想计算的导数,我们将注意力集中到公式(3)的这一部分
........................................(6)
也就是当距离越大时,有越多这样的乘子相乘,而这样的乘子是一个什么东西呢?
在前面已经提到,为激活函数,这里一般为tanh。(后来人们做了改进使用了ReLU等激活函数)
让我们看一下tanh以及它的导数

可以看到,对于训练的大多数情况下,很少会使(0)或(1)的值为0。如果
也是一个大于0小于1的数,则当距离越远时,(3)(6)就会越来越趋近于0,这就是梯度消失;如果
很大时,就会趋近于无穷,这就是梯度爆炸。
从(5)中可以看出,在t较大的情况下,会有越多的乘子相乘,越有可能出现梯度消失的情况,所以最终的梯度和,会被较近距离的梯度(也就是较小的t)主导,这导致模型很难学到远距离的依赖关系。
LSTM : Long Short Term Memory Networks
LSTM,长短时记忆网络,是一种特殊的RNN,能够学习到长期依赖关系。
回忆一下式子(0)
在RNN模型里,我们使用的激活函数为tanh。简化来看,其结构为

图中可以很清晰看到由
和
得到。得到
后用于当前层的模型损失计算,同时用于计算下一层的
。
而LSTM的结构为

直观来看,RNN类似于一种“串联”的结构,而LSTM类似于一种“并联”的结构,造成这一点怪异的感觉是因为除了这个隐藏状态,还多了一个细胞状态(Cell State),记为
。也就是最上面一根类似于“总线”的东西

通过这条总线来传递细胞状态,使其与
均到达下一层,并对下一层进行处理。除了“总线”外,LSTM中包含了很多门控结构,这些门和总线一并构成了LSTM的特殊结构,这样就能够解决RNN的梯度消失与爆炸问题。
遗忘门

这里的[]为concat的意思,上面的公式可以理解为
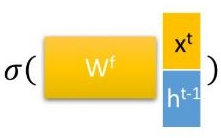 ,这里省略了偏置。
,这里省略了偏置。
其中为sigmoid函数,
,
,
可以理解为该线上的系数,后面的门也类似。
代表遗忘门的系数,由于sigmoid函数的作用,范围在0-1之间,维度与
相同,其将与
进行hadamard乘积(元素对应相乘),其中1代表完全保留该位的细胞状态,0代表完全舍弃该位的细胞状态。这就是“遗忘门”名称的由来。
输入门

输入门由两部分构成,分别为两种激活函数,最后再将两部分的结果做hadamard乘积得到输入门的结果。其实在LSTM中,类似下面两个式子的公式经常出现,只要涉及到激活函数,就会出现类似的公式。

输入门得到的结果将与发生化学反应。
细胞状态更新

这里就是将刚才的输入门的结果,与遗忘门与旧细胞状态的hadamard乘积,加起来,就得到了新的细胞状态
。该公式可以理解为,左边为决定遗忘什么,右边为决定加入什么新信息,而这两部分互相独立。
输出门

隐藏状态的更新由两部分构成,第一部分为
(注意这里的
并不指的是输出output),这与之前所有涉及到激活函数所获得的结果类似,另一部分由更新过的细胞状态
与tanh激活函数构成。

得到后,就可以类似RNN一样顺理成章地得到
了。
LSTM缓解梯度消失/梯度爆炸问题
严谨地来说,LSTM并没有解决RNN的梯度消失和梯度爆炸的问题,而只是缓解了这个情况。
LSTM在刚提出时没有遗忘门,或者说,这时
直接与
相连,所以
可以直接连接到
上(想象一下链式求导,中间
由于
且后面看做常数,也等于1了)。从而这条路径的梯度畅通无阻,不会消失。
但其他路径LSTM和普通RNN的区别并不大,仍然爆炸或者消失。但由于总的远距离梯度等于各条路径的远距离梯度之和。所以即使其他路径消失了,只要保证刚刚那条路径的梯度不消失,总的远距离梯度就不会消失。因此LSTM通过改善这条路径拯救了总体的远距离梯度。
但是道理也类似,由于最终都是求和,如果在其他路径梯度爆炸,最终的远距离梯度仍然可能会爆炸。但是由于LSTM路径崎岖,相比RNN经过了更多的激活函数(导数小于1),所以发生梯度爆炸的概率比过去更低了。
正如前面所说,后来的LSTM进化出了遗忘门,而此时分了两种情况:一是初始化的时候为了使,会故意把偏置设置为较大的正数,让遗忘门饱和;二是使
,这个其实是故意阻断梯度流,可以理解为一个特征。例如在情感分析中遇到“A,但是B”,读到“但是”就会将
设置为0,在细胞更新状态遗忘掉过去的A,这符合逻辑。剩下还有
的情况,这时也仅仅是改善了梯度消失的情况。
到目前为止,都是非常正式的LSTM,但并不是所有LSTM都是同样的,事实上所有涉及了LSTM的paper都对模型结构作了些微改动。
Keras中的LSTM
关于LSTM在keras中的搭建,这里就不多加赘述了,可以参考Manfestein写的Keras中的LSTM。
LSTM变种(包含GRU)
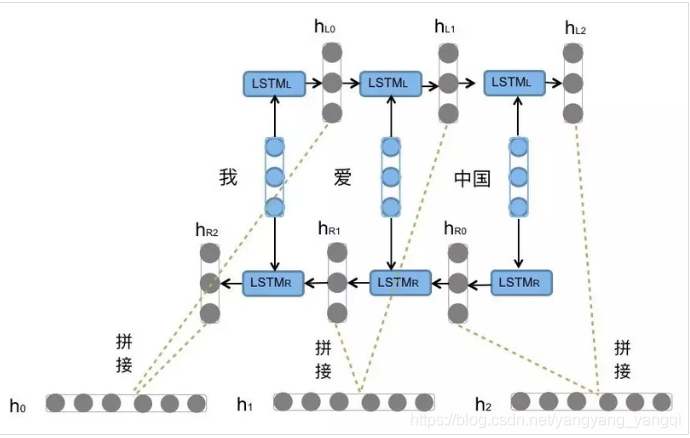
BiLSTM
BiLSTM是binary LSTM的简称,从名称中可以看出来是由两个LSTM构建而成。分别是前向的LSTM和后向的LSTM,举个例子,在读一句话时,正序读就是前向LSTM,倒序读就是后向的LSTM。通过一张图可以更容易理解。
窥视孔连接:peephole connections
在Gers & Schmidhuber (2000)中加入了窥视孔连接这样的操作。

可以看到,增加了两根连接“主线”细胞状态的线,这使我们可以通过门来观测细胞状态。
成对的遗忘门和输入门

从这里我们可以看出,是“细胞状态更新”发生了变化。使用取代了之前的
,也就取消了原来细胞状态更新的那个sigmoid门。通过这样,将遗忘系数“传递”到了细胞更新区域,这样就取代了原来互相独立的两个部分,强行使它们共同做决定。再深入理解
与
,我们就可以发现它的含义是当我们决定遗忘A部分时,我们在A部分加入新信息;当我们决定在B部分加入新信息时,我们决定遗忘B部分。
GRU:Gated Recurrent Unit
GRU,门控循环单元,是LSTM的一种变体,在Cho, et al. (2014)中首次提出。

单从结构上已经很难看明白和前面LSTM的联系了,不过这里很明显已经取消了细胞状态,每一层间传递的信息仅限于
。我们可以从结构中看到
以及其传递的信息被循环利用,并结合该层输入
,最终得到了
,这也就是其取名为“循环”的原因所在。它融合了遗忘门与输入门,精简了模型结构,使得训练的参数大大减少,是目前最受欢迎的模型之一。
Seq2Seq
在前面提到了N2M。这种结构也称为Encoder-Decoder或者Seq2Seq。由于很多应用场景存在着序列不等长的问题,比如在机器翻译中,源语言与目标语言并没有相等的长度,例如德语翻译为中文。
为此,Encoder-Decoder先将输入数据编码为一个上下文向量

得到c后,就用另一个RNN网络对其进行解码,这部分RNN称为Decoder,具体做法就是将c当做之前初始状态的h0输入到Decoder中:

另外一种做法是将c作为每一步的输入:

注意力机制 Attention Model
注意力机制,在我们日常生活中,涉及到注意力这个词的场景,比如说看一幅图片,我们会有重点注意的地方,读一段文字,我们也会有重点侧重的地方,而这样的思想迁移到了深度学习中,就变成了注意力机制。比如我们输入一幅图片,想要生成一段文字来阐述,通过注意力机制,加强它带有更重要特点的地方,能够使我们的效果更佳

同样道理,假设对文本进行提取摘要,也通过注意力机制对关键点词汇进行衡量,将重要的语义以及摘要提取出来。
而“衡量”这一点,如何进行量化呢?很容易想到的就是通过权重进行衡量。比如在文本翻译的应用中,假设使用常规的RNN进行,将"Tom chase Jerry"翻译为中文,这很容易让人联想到编码解码结构,Encoder-Decoder结构。我们将英文进行编码,再通过解码将其变为中文。这句话也就翻译为“汤姆追逐杰瑞”。然而,我们在通过分心模型(也就是Seq2Seq中Decoder的第二种方式)将"Jerry"翻译为“杰瑞”的时候,其他所有词对翻译成“杰瑞”的贡献是相同的,而实际上,我们希望Jerry在翻译时起到最大的贡献。所以我们这里可以对三个单词各个分配权重,我们使Jerry的权重在这三者中占到最大。
更进一步的理解,在原始的模型中,我们的英文句子会生成一个固定的语义向量来表示这个句子,也就是前文所述的上下文向量,这个不变的向量导致我们在生成每个中文单词时,每个英文单词的贡献相同;而现在,我们新的模型有了一个可变的语义向量,这个向量是通过生成不同的单词时进行变化的。


所以在文本翻译中,从另一方面来看,注意力机制也可以看做对不同的词分配不同的概率。也就是输入source和输出target之间的对齐概率分布。用下面一幅图举例来进行表述

传统的文本翻译其实有个对齐短语的步骤,这其实和注意力机制起到的作用是一致的。
这里只是对Attention起到了一个简单的阐述,相关更详细的介绍可以参阅机器之心写的这篇关于Attention的前世今生:
还可以阅读张俊林写的非常详细的Attention介绍:
应用
笔者构建了使用Attention机制的古诗生成器模型,详情可参见古诗生成器项目。
