YOLO 官网:https://pjreddie.com/darknet/yolo/
论文:https://pjreddie.com/media/files/papers/YOLOv3.pdf
一.介绍
由于项目需求,需在树莓派下进行行人检测。树莓派内存较小,计算能力不足。opencv自带的HOG+SVM算法精度不够,而基于回归的深度学习检测算法YOLO精度高,计算要求小。
考虑使用YOLOv3-tiny算法进行行人检测,本文主要包括Ubuntu下的YOLOv3配置,训练自己的行人数据集以及调参总结。
参考了很多博客,亲测实验,如果有误请及时指正。
二.ubuntu下配置
其在Ubuntu下配置基本按照官网提供的步骤即可。
下载源码及CPU下编译:
git clone https://github.com/pjreddie/darknet
cd darknet
make下载tiny权重文件及测试:
wget https://pjreddie.com/media/files/yolov3-tiny.weights
./darknet detect cfg/yolov3-tiny.cfg yolov3-tiny.weights data/dog.jpg其权重文件和测试结果图片都在根目录下。
三.训练行人检测器
相信大家都能跑通官方权重,但其检测器是20个类别,在实际使用中并不需要全部类别,且类别多精度会下降。我们需要单独训练自己的检测器,比如人脸检测,路标检测等,我这里是做行人检测。
3.1标注数据集
我们采用PASCAL VOC格式的数据集,其标注格式较为复杂,幸好有前人写过自动生成的python程序,即labelImg工具,具体使用请转:https://github.com/tzutalin/labelImg
3.2生成训练集的标注文件
i>官网提供了原数据集:
wget https://pjreddie.com/media/files/VOCtrainval_11-May-2012.tar
wget https://pjreddie.com/media/files/VOCtrainval_06-Nov-2007.tar
wget https://pjreddie.com/media/files/VOCtest_06-Nov-2007.tar
tar xf VOCtrainval_11-May-2012.tar
tar xf VOCtrainval_06-Nov-2007.tar
tar xf VOCtest_06-Nov-2007.tarii>我们需要将自己标注的数据放进来。
jpg图像放到/VOCdevkit/VOC2007/JPEGImages/中,xml文件放到/VOCdevkit/VOC2007/Annotations/中。
在/VOCdevkit/VOC2007/ImageSets/Main/person_trainval.txt文件格式如下
000005 -1 #前面代表图片名称,后面-1表示负样本,1表示正样本
000007 -1
000009 1
000012 -1我们需将自己数据集按着这个格式copy到person_trainval.txt文件中。如:
009959 -1
009961 -1
1(1) 1
1(10) 1windows下批量生成该格式,请参考https://zhidao.baidu.com/question/292884446.html
生成txt文件之后,没有1,-1的标志,需手动添加,或者word打开替换功能将“段落标识符”替换为“ 1 段落标识符”(本人使用了word的替换功能)。
iii>生成训练集的标注文件时需要下载:
wget https://pjreddie.com/media/files/voc_label.py但是本文单独训练行人检测器,需修改voc_label.py文件:
import xml.etree.ElementTree as ET
import pickle
import os
from os import listdir, getcwd
from os.path import join
sets=[('2012', 'person_trainval'), ('2007', 'person_trainval')] #只选取含有行人的数据
classes = ["person"] #修改类别,只有person
def convert(size, box):
dw = 1./(size[0])
dh = 1./(size[1])
x = (box[0] + box[1])/2.0 - 1
y = (box[2] + box[3])/2.0 - 1
w = box[1] - box[0]
h = box[3] - box[2]
x = x*dw
w = w*dw
y = y*dh
h = h*dh
return (x,y,w,h)
def convert_annotation(year, image_id):
in_file = open('VOCdevkit/VOC%s/Annotations/%s.xml'%(year, image_id))
out_file = open('VOCdevkit/VOC%s/labels/%s.txt'%(year, image_id), 'w')
tree=ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult)==1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text), float(xmlbox.find('ymax').text))
bb = convert((w,h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
wd = getcwd()
for year, image_set in sets:
if not os.path.exists('VOCdevkit/VOC%s/labels/'%(year)):
os.makedirs('VOCdevkit/VOC%s/labels/'%(year))
image_ids = open('VOCdevkit/VOC%s/ImageSets/Main/%s.txt'%(year, image_set)).read().strip().split()
list_file = open('%s_%s.txt'%(year, image_set), 'w')
for i in range(len(image_ids)):
if image_ids[i]=='1': #我们只训练正样本
list_file.write('%s/VOCdevkit/VOC%s/JPEGImages/%s.jpg\n'%(wd, year, image_ids[i-1]))
convert_annotation(year, image_ids[i-1])
list_file.close()
os.system("cat 2007_person_trainval.txt 2012_person_trainval.txt > train.txt")
os.system("cat 2007_person_trainval.txt 2012_person_trainval.txt > train.all.txt")该行if image_ids[i]=='1':表示只训练正样本:请查看/home/ps/darknet/train/VOCdevkit/VOC2007/ImageSets下的person_trainval.txt文件,后面的'1'代表正样本。
3.3修改配置文件
i>修改data/voc.names文件,只保留person一行,其余行删除。
ii>修改cfg/voc.date文件:
classes= 1
train = /home/ps/darknet/train/train.txt
valid = /home/ps/darknet/train/2007_test.txt
names = data/voc.names
backup = backup
iii>修改cfg/yolov3-tiny.cfg文件:
找到文件中类似代码段(yolo层附件),共2处:
[convolutional]
size=1
stride=1
pad=1
filters=18
activation=linear
[yolo]
mask = 3,4,5
anchors = 10,14, 23,27, 37,58, 81,82, 135,169, 344,319
classes=1
num=6
jitter=.3
ignore_thresh = .7
truth_thresh = 1
random=0
需要改变filters为 3*(classes+1+4),原因为:https://github.com/pjreddie/darknet/issues/582,同时修改下面的classes的种类。
3.4训练
重点之处:需先加载预训练模型,而官网没给tiny版的预训练模型,搜寻半天发现可以在原yolov3-tiny.weights上得到,只需如下指令。参考https://blog.csdn.net/chengyq116/article/details/83213699
./darknet partial ./cfg/yolov3-tiny.cfg ./yolov3-tiny.weights ./yolov3-tiny.conv.15 15然后训练:
sudo ./darknet detector train cfg/voc.data cfg/yolov3-tiny.cfg yolov3-tiny.conv.153.5结果展示
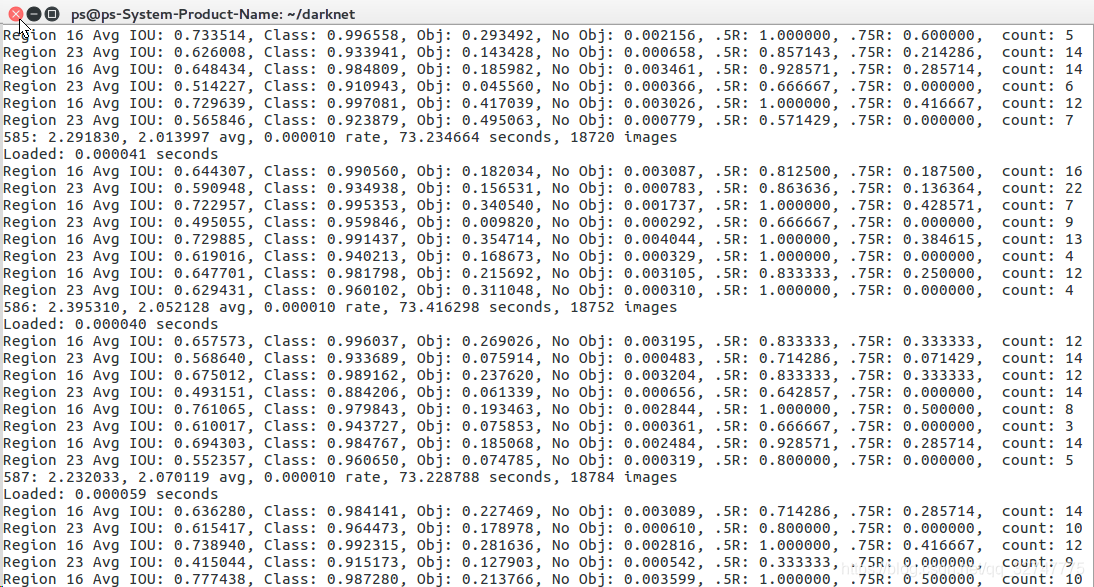
可以看出,500多代后loss很小:2.070119,表明算法收敛。其训练指标具体含义参考https://blog.csdn.net/lilai619/article/details/79695109
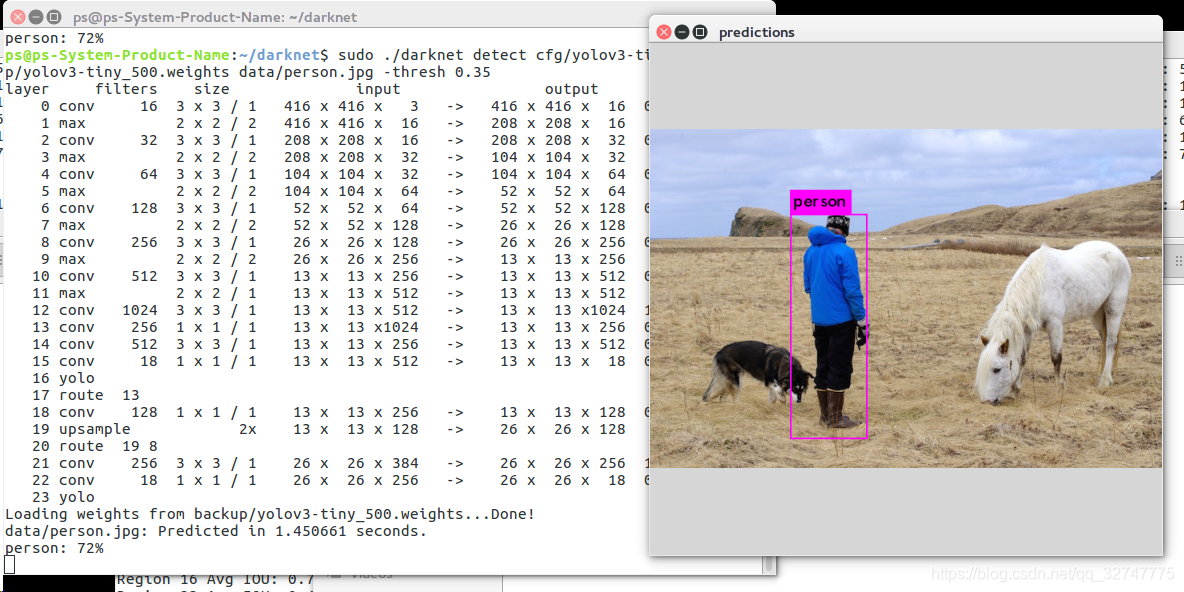
四.调参
训练时需调节参数,cfg/yolov3-tiny.cfg参数含义如下:
[net]
# Testing #测试时取消注释
#batch=1
#subdivisions=1
# Training #训练时取消注释
batch=32 #训练批次大小
subdivisions=4 #测试时批次分组,即一批32张图片,分4组训练
width=416
height=416
channels=3 #图片大小
momentum=0.9 #动量参数
decay=0.0005
angle=0 #通过旋转角度来生成更多训练样本
saturation = 1.5 #调整饱和度来生成更多训练样本
exposure = 1.5 #调整曝光量来生成更多训练样本
hue=.1 #调整色调来生成更多训练样本
learning_rate=0.001 #学习率,0.01-0.001
burn_in=50 #前50代不使用steps策略调整学习率
max_batches = 600 #总训练代数
policy=steps #选取的训练策略 参考https://nanfei.xyz/2018/01/23/YOLOv2%E8%B0%83%E5%8F%82%E6%80%BB%E7%BB%93/
steps=200,400
scales=.1,.1 #steps策略表示,200代之后学习率缩小0.1,400代之后再缩小0.1
调参中,burn_in需要适当选取,因为小于它时学习率慢慢上升到你设定的值。其后steps两次,学习率依次减小。
在训练过程中可能出现其他问题,参考https://blog.csdn.net/Pattorio/article/details/80051988
