目录
两款IP Camera+YOLOV3进行目标检测(手机摄像头作为电脑摄像头使用)
windows平台使用CMake工具对darknet的编译以及安装过程+yolov3+图像检测+摄像头检测+视频检测+手机作为摄像头进行检测(详解)
提示:
若读者还没有使用CMake工具对darknet源码进行编译,那么请看上面的文章《windows平台使用CMake工具对darknet的编译以及安装过程+yolov3+图像检测+摄像头检测+视频检测+手机作为摄像头进行检测(详解)》;
若已经在windows平台上对其darknet进行了编译,则可以直接进行下面的操作。
以下整个过程结构图:

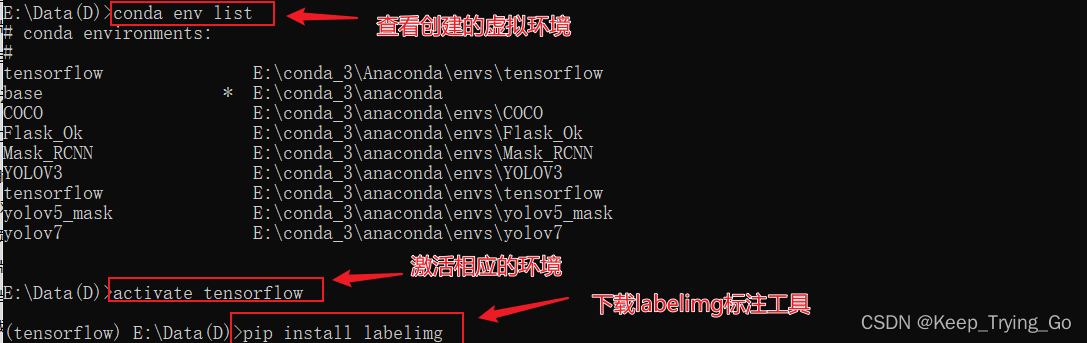
1.准备标注工具
(1)图像标注工具:pip install labelimg
(2)打开标注工具:labelimg(在windows的命令窗口激活相应的虚拟环境之后)
(3)选择要标注的图像文件夹;

2.数据集准备
(1)下载数据集
链接:https://pan.baidu.com/s/18R30A4NtFJ2vpLEIk8I1-w
提取码:b61k提示:以上下载的数据集是已经处理好的,但是如果读者想要标注自己的数据集的话,那么建议在标注数据集的同时,文件的存放结构按照如下所示:
- VOCdevkit
- VOC2007
- Annotations(存放标注图像之后得到的XML文件)
- ImageSets(包含了存放图像的路径的.txt文件)
- Main
- train.txt
- test.txt
- val.txt
- JPEGImages(存放相应标注图像的位置.jpg)
- labels(运次那个处理数据集的程序之后产生的文件,里面包含了每一张图像对应的txt文件,.txt文件中包含了:[class,cx,cy,w,h])
- 2007_test.txt(包含了用于测试集的图像绝对路径)
- 2007_train.txt(包含了用于训练集的图像绝对路径)
- 2007_val.txt(包含了用验证集的图像绝对路径)
- train.all.txt(包含了所有图像绝对路径)
- train.txt(包含了用于训练集和验证集的图像绝对路径)
提示:为什么建议读者按照上方的结构来放置数据集呢,主要是因为在处理数据集的程序中给定的路径就如上方样式所示,而且上面这样的格式也比较清晰。

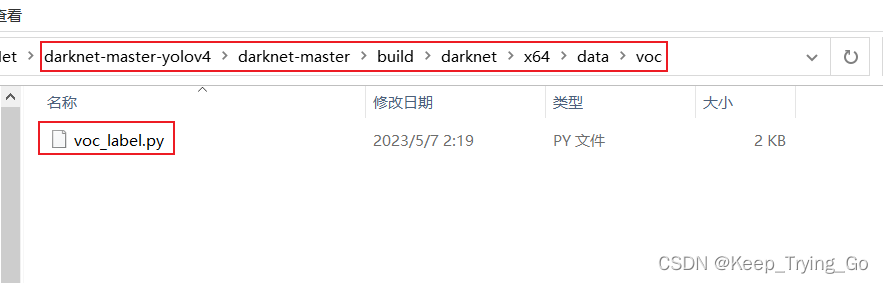
(2)处理数据集
提示:该代码看起来有一点长,但是读者不要害怕,关键的地方都做了说明,并且很容易理解。下面的一部分代码是原本就已经给出的,路径为:
import os
import pickle
import random
import numpy as np
from PIL import Image
from os.path import join
from os import listdir, getcwd
import xml.etree.ElementTree as ET
import cv2
# sets=[('2012', 'train'), ('2012', 'val'), ('2007', 'train'), ('2007', 'val'), ('2007', 'test')]
# classes = ["aeroplane", "bicycle", "bird", "boat", "bottle", "bus", "car", "cat", "chair", "cow", "diningtable", "dog", "horse", "motorbike", "person", "pottedplant", "sheep", "sofa", "train", "tvmonitor"]
sets =('2007', 'train'), ('2007', 'val'), ('2007', 'test')
classes = ['face']
#将数据的格式转换为中心坐标以及图像的高宽[cx,cy,w,h]
def convert(size, box):
dw = 1./(size[0])
dh = 1./(size[1])
x = (box[0] + box[1])/2.0 - 1
y = (box[2] + box[3])/2.0 - 1
w = box[1] - box[0]
h = box[3] - box[2]
x = x*dw
w = w*dw
y = y*dh
h = h*dh
return (x,y,w,h)
"""
读者XML文件下的相关信息,比如标注的图像中物体的高宽以及图像的尺寸等信息
注意:XML中的得到的框[xmin,ymin,xmax,ymax]表示图像中物体的左上角坐标(xmin,ymin)
和右下角坐标(xmax,ymax);但是需要将数据的格式转换为中心坐标以及图像的高宽[cx,cy,w,h]
"""
def convert_annotation(year, image_id):
in_file = open('VOCdevkit/VOC%s/Annotations/%s.xml'%(year, image_id))
out_file = open('VOCdevkit/VOC%s/labels/%s.txt'%(year, image_id), 'w')
tree=ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult)==1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text), float(xmlbox.find('ymax').text))
bb = convert((w,h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
"""
读取文件ImageSets/Main/train.txt,ImageSets/Main/val.txt,ImageSets/Main/test.txt
中的图像的名称,以此来图像的路径+图像名称构成图像的完整路径,读取图像。
"""
def VOC2007():
wd = getcwd()
for year, image_set in sets:
if not os.path.exists('VOCdevkit/VOC%s/labels/'%(year)):
os.makedirs('VOCdevkit/VOC%s/labels/'%(year))
image_ids = open('VOCdevkit/VOC%s/ImageSets/Main/%s.txt'%(year, image_set)).read().strip().split()
list_file = open('%s_%s.txt'%(year, image_set), 'w')
for image_id in image_ids:
list_file.write('%s/VOCdevkit/VOC%s/JPEGImages/%s.jpg\n'%(wd, year, image_id))
convert_annotation(year, image_id)
list_file.close()
os.system("cat 2007_train.txt 2007_val.txt 2012_train.txt 2012_val.txt > train.txt")
os.system("cat 2007_train.txt 2007_val.txt 2007_test.txt 2012_train.txt 2012_val.txt > train.all.txt")
"""
缩放图像的大小到指定图像大小
"""
def resizeImage():
"""
:return:
"""
imgPath = r"E:\tempImage"
imgs_list = os.listdir(imgPath)
for img_name in imgs_list[:200]:
img_path = os.path.join(imgPath,img_name)
img = cv2.imread(img_path)
newimg = cv2.resize(src = img,dsize=(416,416))
cv2.imwrite(filename='../myDataset/VOC2007/JPEGImages/'+str(img_name),img = newimg)
cv2.destroyAllWindows()
"""
由于ImageSets/Main下面并没有存在一下文件
ImageSets/Main/train.txt,ImageSets/Main/val.txt,ImageSets/Main/test.txt
所以需要根据图像,将图像数据集划分为训练集,验证集,测试集,并且将这些数据集的名称存放入
train.txt,val.txt,test.txt文件中
"""
def ImageSets():
train_val_ratio = 0.8
val_ratio = 0.1
test_ratio = 0.1
xmlfilepath = 'VOCdevkit/VOC2007/Annotations'
mainPath = 'VOCdevkit/VOC2007/ImageSets/Main'
if not os.path.exists(mainPath):
os.makedirs(mainPath)
xml_list = os.listdir(xmlfilepath)
total_num = len(xml_list)
#按其文件名的顺序进行读取
xml_list.sort(key=lambda x:int(x.split('.')[0]))
total_range = range(total_num)
n_train = int(total_num * train_val_ratio)
n_val = int(total_num * val_ratio)
n_test = int(total_num * test_ratio)
# trainPath = os.path.join('VOCdevkit/VOC2007/ImageSets/Main','train')
# valPath = os.path.join('VOCdevkit/VOC2007/ImageSets/Main','val')
# testPath = os.path.join('VOCdevkit/VOC2007/ImageSets/Main','test')
# if not os.path.exists(trainPath):
# os.mkdir(trainPath)
# if not os.path.exists(valPath):
# os.mkdir(valPath)
# if not os.path.exists(testPath):
# os.mkdir(testPath)
train = open('VOCdevkit/VOC2007/ImageSets/Main/train.txt', 'w')
test = open('VOCdevkit/VOC2007/ImageSets/Main/test.txt', 'w')
val = open('VOCdevkit/VOC2007/ImageSets/Main/val.txt', 'w')
for xml_idx in total_range[:n_train]:
xml_name = xml_list[xml_idx]
file = xml_name.split('.')[0]+'\n'
train.write(file)
for xml_idx in total_range[n_train:n_train + n_val]:
xml_name = xml_list[xml_idx]
file= xml_name.split('.')[0]+'\n'
val.write(file)
for xml_idx in total_range[n_train+ n_val:total_num]:
xml_name = xml_list[xml_idx]
file = xml_name.split('.')[0]+'\n'
test.write(file)
train.close()
test.close()
val.close()
"""
由于在训练的过程遇到过一个错误,导致不需要8位深的图像转换为24位深的图像
"""
def changeDepthBit():
path8 = r'VOCdevkit/VOC2007/JPEGImages'
newpath24 = r'VOCdevkit/VOC2007/ImageDepth24'
files8 = os.listdir(path8)
files8.sort(key=lambda x:int(x.split('.')[0]))
for img_name in files8:
imgpath = os.path.join(path8,img_name)
img = Image.open(imgpath).convert('RGB')
file_name, file_extend = os.path.splitext(img_name)
dst = os.path.join(newpath24, file_name + '.jpg')
img.save(dst)
if __name__ == '__main__':
# resizeImage()
# ImageSets()
# VOC2007()
changeDepthBit()
pass
3.修改相应的配置文件
(1)修改voc.data和voc.names
提示:将darknet-master-yolov4\darknet-master\build\darknet\x64\data路径下的voc.data和voc.names拷贝到自己项目的文件目录下。
修改voc.data:

修改voc.names:

(2)修改yolov3.cfg配置文件

max_batches修改原则:将行max_batches更改为(classes*2000,但不少于训练图像的数量,且不少于6000),如果您训练了3个类,则f.e.max_batches=6000。
提示:像上面这样的修改有三处需要进行修改,上面给出的只是第一处。需要修改的地方都在是yolo之后和convolutional之后。
4.下载权重文件
5.训练数据集
(1)训练开始
darknet.exe detector train data/voc.data cfg/yolov3.cfg preTrain/darknet53.conv.74
- data/voc.data
- cfg/yolov3.cfg
- preTrain/darknet53.conv.74

(2)训练结果

(3)测试结果
提示:读者可以使用如下链接的代码进行测试:
https://mydreamambitious.blog.csdn.net/article/details/125520487
或者就使用在介绍关于darknet编译的时候使用的命令进行测试。
"""
@Author : Keep_Trying_Go
@Major : Computer Science and Technology
@Hobby : Computer Vision
@Time : 2023/5/24 8:40
"""
import os
import cv2
import numpy as np
#创建窗口
# cv2.namedWindow(winname='detect',flags=cv2.WINDOW_AUTOSIZE)
# cv2.resizeWindow(winname='detect',width=750,height=600)
#读取YOLO-V3权重文件和网络配置文件
net=cv2.dnn.readNet(model='backup/yolov3_final.weights',config='cfg/yolov3.cfg')
#设置置信度阈值和非极大值抑制的阈值
Confidence_thresh=0.2
Nms_thresh=0.35
#读取coco.names文件中的类别
with open('data/voc.names','r') as fp:
classes=fp.read().splitlines()
#yolo-v3检测
def detect(frame):
#获取网络模型
model=cv2.dnn_DetectionModel(net)
#设置网络的输入参数
model.setInputParams(scale=1/255,size=(416,416))
#进行预测
class_id,scores,boxes=model.detect(frame,confThreshold=Confidence_thresh,
nmsThreshold=Nms_thresh)
#返回预测的类别和坐标
return class_id,scores,boxes
#实时的检测
def detect_time():
#开启摄像头 'video/los_angeles.mp4' or 'video/soccer.mp4'
cap=cv2.VideoCapture(0)
while cap.isOpened():
OK,frame=cap.read()
if not OK:
break
frame=cv2.flip(src=frame,flipCode=2)
# frame=cv2.resize(src=frame,dsize=(416,416))
#进行预测
class_ids,scores,boxes=detect(frame)
#绘制矩形框
for (class_id,box) in enumerate(boxes):
(x,y,w,h)=box
class_name = classes[class_ids[class_id]]
confidence = scores[class_id]
confidence=str(round(confidence,2))
cv2.rectangle(img=frame,pt1=(x,y),pt2=(x+w,y+h),
color=(0,255,0),thickness=2)
text=class_name+' '+confidence
cv2.putText(img=frame,text=text,
org=(x,y-10),fontFace=cv2.FONT_HERSHEY_SIMPLEX,
fontScale=1.0,color=(0,255,0),thickness=2)
cv2.imshow('detect',frame)
key=cv2.waitKey(1)
if key==27:
break
cap.release()
#单张图片的检测
def signal_detect(image_path='data/2141.png'):
frame=cv2.imread(image_path)
frame = cv2.resize(src=frame, dsize=(416, 416))
# 进行预测
class_ids, scores, boxes = detect(frame)
# 绘制矩形框
for (class_id, box) in enumerate(boxes):
(x, y, w, h) = box
class_name = classes[class_ids[class_id]]
confidence = scores[class_ids[class_id]]
confidence = str(round(confidence, 2))
cv2.rectangle(img=frame, pt1=(x, y), pt2=(x + w, y + h),
color=(0, 255, 0), thickness=2)
text = class_name + ' ' + confidence
cv2.putText(img=frame, text=text,
org=(x, y - 10), fontFace=cv2.FONT_HERSHEY_SIMPLEX,
fontScale=1.0, color=(0, 255, 0), thickness=2)
cv2.imshow('detect', frame)
cv2.waitKey(0)
cv2.destroyAllWindows()
if __name__ == '__main__':
print('Pycharm')
# signal_detect()
detect_time()