◎本文为极市开发者「ArtyZe」原创投稿,转载请注明来源。
◎极市「项目推荐」专栏,帮助开发者们推广分享自己的最新工作,欢迎大家投稿。联系极市小编(fengcall19)即可投稿~
量化简介
在实际神经网络在例如端侧的部署时,由于内存,带宽或者最重要计算资源的限制,通常会采用量化等手段来加速神经网络的表现。量化的意思即是将原来浮点运算转化为定点运算,例如最常见的8bit量化,无论是int8还是uint8,都是将浮点的区间参数映射到256个离散区间上。这样原来32位的运算就变成了8位的运算
r = S ( q − Z ) r=S(q-Z) r=S(q−Z)
这里我们以非对称量化到uint8举例,其中S代表量化因子(scale factor), Z代表zero point.

量化的优点非常明显,即使除去后处理,反量化或者非对称量化带来额外运算,单张图片的推理速度通常都能获得2-3倍的提升(这里不讨论针对硬件进行特殊优化带来的加速),但是随之而来的就是量化造成的精度下降问题。
简单来说,量化造成精度损失主要来自两个方面:
-
取整损失,例如r = [6.8, 7.2, -0.6], scale = (7.2+0.6)/127 = 0.061417, q1 = 7.2/scale = 117.23,那么他的量化值就是117,有了0.23的损失
-
截断损失 ,因为scale是取最优区间,那么边界的点势必会有超过最大量化值的情况,这些离群点就会被忽略掉,量化的最大最小值区间相比于原数据分布就有了截断损失
为了能够减少量化过程中的精度损失,我们参考google的论文
《Quantization and Training of Neural Networks for Efficient Integer-Arithmetic-Only Inference》,这种方法属于aware training quantization,与之对应的是post training quantization,后面一种方法是tensorRT使用的量化方法,后面有机会可以把实现的代码上传到github上。
事实上,学术界认为8bit的量化已经饱和了,已经开始做4bit的量化研究了,但是在实际的工作过程中,发现对于较小的识别网络,8bit的量化效果依然不是令人非常满意。
量化实现
为了方便的部署到嵌入式端,我最初选择实现框架定在实现语言为C或者C++,最终选定的框架为darknet,一方面darknet在工业界有着不错的应用群体,二来框架简单直接,实现起来非常方便,同时还可以验证反向过程是否正确。在复现过程中,为了能够将算法成功的集成进去,对darknet做了许多小的修改,正好这里也记录一下。
代码链接:
https://github.com/ArtyZe/yolo_quantization
伪量化
相信对量化了解的同学都读过这篇文章,tf-lite都是用的这种量化方式。区别于训练后量化的方式,google采用的是在训练过程中加入伪量化来模拟量化过程中由于取整造成的精度损失。
那么伪量化是个什么操作呢?
q = ⌊ x − a s ⌋ x + a q=\left\lfloor\frac{x-a}{s}\right\rfloor x+a q=⌊sx−a⌋x+a
其中,类似中括号那里就是取整的意思。可以看到,如果说没有取整这个操作,完全就是减一个数,除一个数,再乘回来,再加回来,完全就没有任何变化。但是因为有了这个取整,所以这中间就有了变化。
想象一下,如果在训练过程中,采取了这么一个操作,那不就相当于提前就把量化的损失考虑进去了吗?这样等到inference的时候,精度下降就少的多了呀。
那么要把这个伪量化放在哪里呢?
那当然是放在inference的时候需要进行量化的位置,以论文中给出的图来解析,
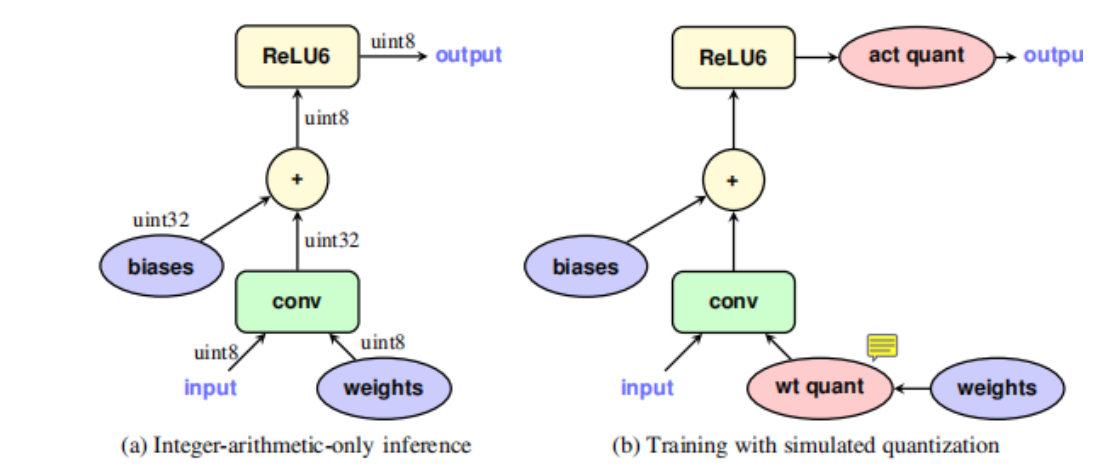
卷积的操作用公式来描述无非就是:
y = f ( w x ) y=f(w x) y=f(wx)
所以要量化的就是weights以及feature x。
这时候就有人提出疑问了,可是你看啊,人家给出的图中是weights和激活值的伪量化啊,你怎么说是input的feature呢,可是如果你这样想呢,除了第一层真正的输入之外,剩下的层,上一层的activ输出值不就是下一层的input值吗,而且使用activ值有一个什么最大的好处呢?在最后一层将定点值反量化回到浮点值需要用到激活值的scale和zero_point(如果是非对称量化的话)。
在训练中融合BN到CONV
我们平时见到的最多的融合BN+CONV就是在inference的时候为了加速做的,但是你细想一下,你BN的参数在inference的时候怎么办呢?如果inference的时候不融合,那么BN的参数你要怎么量化,如果融合了,那么weights的量化参数是根据融合前生成的啊,那你怎么能用呢?
所以解决方案就是,把BN融合在训练阶段就加进去,如下图:

具体怎么做呢?
- 首先就 y = w x y=w x y=wx的前向跑一遍,计算得到均值,方差等一系列BN的参数
- 然后,利用这些BN的参数,通过融合公式加到input和weights中去,将卷积公式变成真正的
y ′ = w ′ x + b ′ y^{\prime}=w^{\prime} x+b^{\prime} y′=w′x+b′
其中
w ′ = p w σ 2 + ε b ′ = b − γ μ σ 2 + ε w^{\prime}=\frac{p w}{\sqrt{\sigma^{2}+\varepsilon}} \quad b^{\prime}=b-\frac{\gamma \mu}{\sqrt{\sigma^{2}+\varepsilon}} w′=σ2+εpwb′=b−σ2+εγμ
为了后续能够更新原生 w w w 和 b , b, b, 该过程中不仅需要保存 w ′ w^{\prime} w′ 和 b ′ , b^{\prime}, b′, 还需要保存 w w w 和 b b b,至于反向更新过程中,需要使用Straight Through Estimator(STE)来跳过伪量化过程中的round使得梯度可以正常回传
- 之后根据不同层的type添加input, weights和activation量化即可。目前我采用的方式是第一层卷积input, weights和activation量化都要有,其他层如route后面的卷积层同样需要input量化,因为route的activation量化参数直接使用他的输入层的activation量化参数即可;maxpool或者upsample都是添加activation量化即可
需要注意的
Uint8推理实现
下面开始介绍定点推理,公式如下
y = w x + b y=w x+b y=wx+b
由前面可知
r = S ( q − Z ) r=S(q-Z) r=S(q−Z)
S 3 ( q 3 − Z 3 ) = S 2 ( q 2 − Z 2 ) S 1 ( q 1 − Z 1 ) + S b ( q b − Z b ) S_{3}\left(q_{3}-Z_{3}\right)=S_{2}\left(q_{2}-Z_{2}\right) S_{1}\left(q_{1}-Z_{1}\right)+S_{b}\left(q_{b}-Z_{b}\right) S3(q3−Z3)=S2(q2−Z2)S1(q1−Z1)+Sb(qb−Zb)
为了保持量纲一致,令, S b = S 1 S 2 , Z b = 0 S_{b}=S_{1} S_{2}, \quad Z_{b}=0 Sb=S1S2,Zb=0
对上式进行简单的变换
q 3 = Z 3 + M ( N Z 1 Z 2 − Z 1 ∑ q 2 − Z 2 ∑ q 1 + ∑ q 1 q 2 + q b ) q_{3}=Z_{3}+M\left(N Z_{1} Z_{2}-Z_{1} \sum q_{2}-Z_{2} \sum q_{1}+\sum q_{1} q_{2}+q_{b}\right) q3=Z3+M(NZ1Z2−Z1∑q2−Z2∑q1+∑q1q2+qb)
其中, M = S 1 S 2 / S 3 M=S_{1} S_{2} / S_{3} M=S1S2/S3 是唯一的浮点数, 因此采用 M = M 0 × 2 − s h i f t M=M_{0} \times 2^{-s h i f t} M=M0×2−shift 来代表, M 0 M_{0} M0 和 shift 都是定点值,具体多大需要看精度需要,一般采用32位的值来表示。
-
在进入到正式的推理之前,首先看上式哪些值是常量可以提前计算出来,例如 Z 3 , Z 1 Z 2 , Z 1 ∑ q 2 , q b Z_{3}, Z_{1} Z_{2}, Z_{1} \sum q_{2}, q_{b} Z3,Z1Z2,Z1∑q2,qb都是常量,其中1代表ft,2代表weights
-
进入到正式推理后,需要注意的问题就是溢出的问题,一般情况下为了防止这种情 况有两种方式,一种就是使用一个shift来统计溢出的情况,另一种就是直接把输出范围扩大,例如8bit的乘加输出到32bit。下面我们开始计算 Z 2 ∑ q 1 Z_{2} \sum q_{1} Z2∑q1 及 ∑ q 1 q 2 \sum q_{1} q_{2} ∑q1q2,为了能够尽可能的探索优化速度的极限,gemm函数我们使用的是mkl中的cblas库函数。
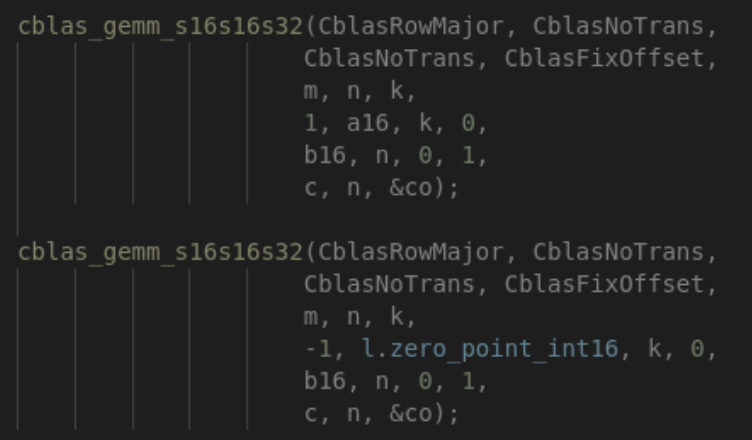
-
得到 q 3 q_{3} q3之后的最后一步操作就是激活,这部分在实际使用过程中也是关乎到量化精度的一个关键点。如果激活函数是类似softmax,tanh,swish等非线性函数的话,都要通过lookup table查表的方式,为了能够尽快的实现,我这里选用的是tiny-yolov3,里面的激活函数都是leaky relu的线性激活函数
-
其他层例如maxpool,route由于并不涉及到计算操作,因此直接将代码转成uint8的即可
-
在最后一层yolo层的前面需要将uint8反量化回到float类型,方式如下

后续改进
目前已经实现了yolov3-tiny的所有算子的实现,为了方便,目前使用relu6替代了原来的
leakyrelu,包括conv, pooling, route, upsample,这些除了conv全部都是线性的算子,后续会
继续支持leaky relu, softmax, shortcut, elementwise add, concat等非线性算子。
量化performance
为了尽可能的不影响精度,我选择在yolo层的上面一层conv层不进行量化。测试结果如下,可以看到前向时间相比于原来的darknet压缩明显,同时精度下降非常低。

传送门
Github链接:
https://github.com/ArtyZe/yolo_quantization