YOLOv3 Darknet安装编译与训练自己的数据集
文章目录:
1安装编译darknet与测试darknet
1.1 安装编译darknet
YOLO v3的安装与YOLO v2的安装方法一样
1.1.1 下载darknet安装包
从Darknet的github官方地址,先把项目克隆下来
git clone thttps://github.com/pjreddie/darknet.git
1.1.2 编译darknet
1、下载完以后,打开进入到安装包路径内
cd darknet
2、如果你的机器上有Nvidia的GPU,并且安装了Cuda,就可以实现用GPU加速,让yolo运行的更快。只需要对Makefile文件进行修改,然后再进行编译即可(如果没有GPU忽略这一步):
vi Markfile
修改如下(把对应的Flags值该为1,相当于设置为true):
GPU=1
CUDNN=1
OPENCV=1
3、开始编译darknet
make
编译过程中会显示如下信息:
mkdir -p obj
gcc -I/usr/local/cuda/include/ -Wall -Wfatal-errors -Ofast....
gcc -I/usr/local/cuda/include/ -Wall -Wfatal-errors -Ofast....
gcc -I/usr/local/cuda/include/ -Wall -Wfatal-errors -Ofast....
.....
gcc -I/usr/local/cuda/include/ -Wall -Wfatal-errors -Ofast -lm....
编译完成之后,会生成一个darknet的可执行文件,在命令行中执行这个可执行文件:
./darknet
如果返回如下信息,说明编译成功:
usage: ./darknet <function>

1.2 测试darknet
1.2.1 测试单张图片
这里我们测试darknet yolov3在目标检测上的效果
1、下载yolov3 的预训练权重
wget https://pjreddie.com/media/files/yolov3.weights
2、运行demo测试
- 测试模型:yolov3
- cfg/yolov3.cfg:中定义的是yolov3的模型
- yolov3.weights:是预训练的yolov3的权重
- data/dog.jpg:是要测试的图片
./darknet detect cfg/yolov3.cfg yolov3.weights data/dog.jpg
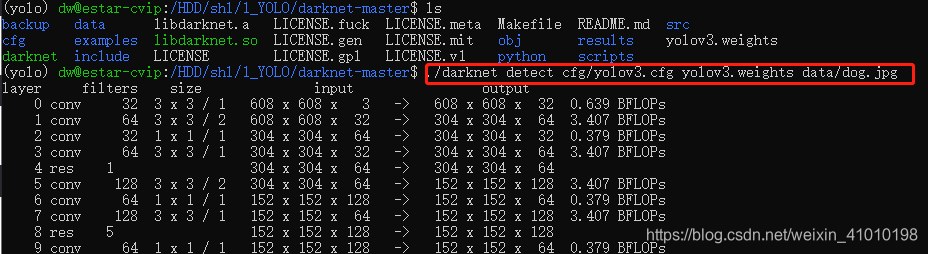
detect命令是detector test命令的简写,`因此在测试单张图片时,下面的两个命令写法是等价的:
./darknet detect cfg/yolov3.cfg yolov3.weights data/dog.jpg
# 或(上下等价)
./darknet detector test cfg/coco.data cfg/yolov3.cfg yolov3.weights data/dog.jpg
执行过程会输出如下信息:
layer filters size input output
0 conv 32 3 x 3 / 1 608 x 608 x 3 -> 608 x 608 x 32 0.639 BFLOPs
1 conv 64 3 x 3 / 2 608 x 608 x 32 -> 304 x 304 x 64 3.407 BFLOPs
2 conv 32 1 x 1 / 1 304 x 304 x 64 -> 304 x 304 x 32 0.379 BFLOPs
3 conv 64 3 x 3 / 1 304 x 304 x 32 -> 304 x 304 x 64 3.407 BFLOPs
4 res 1 304 x 304 x 64 -> 304 x 304 x 64
5 conv 128 3 x 3 / 2 304 x 304 x 64 -> 152 x 152 x 128 3.407 BFLOPs
...
93 conv 255 1 x 1 / 1 38 x 38 x 512 -> 38 x 38 x 255 0.377 BFLOPs
94 yolo
95 route 91
96 conv 128 1 x 1 / 1 38 x 38 x 256 -> 38 x 38 x 128 0.095 BFLOPs
97 upsample 2x 38 x 38 x 128 -> 76 x 76 x 128
98 route 97 36
99 conv 128 1 x 1 / 1 76 x 76 x 384 -> 76 x 76 x 128 0.568 BFLOPs
100 conv 256 3 x 3 / 1 76 x 76 x 128 -> 76 x 76 x 256 3.407 BFLOPs
101 conv 128 1 x 1 / 1 76 x 76 x 256 -> 76 x 76 x 128 0.379 BFLOPs
102 conv 256 3 x 3 / 1 76 x 76 x 128 -> 76 x 76 x 256 3.407 BFLOPs
103 conv 128 1 x 1 / 1 76 x 76 x 256 -> 76 x 76 x 128 0.379 BFLOPs
104 conv 256 3 x 3 / 1 76 x 76 x 128 -> 76 x 76 x 256 3.407 BFLOPs
105 conv 255 1 x 1 / 1 76 x 76 x 256 -> 76 x 76 x 255 0.754 BFLOPs
106 yolo
Loading weights from yolov3.weights...Done!
data/dog.jpg: Predicted in 0.033660 seconds.
dog: 100%
truck: 92%
bicycle: 99%
Unable to init server: 无法连接: 拒绝连接
(predictions:30960): Gtk-WARNING **: 14:23:14.658: cannot open display:
从上面输出信息可以看到,输入信息如下:
- yolov3的网络结构:包括卷积层数、卷积和大小、输入输出大小
- 推理检测需要的时间
- 检测到目标的
置信度
然后会在当前目录下生成检测的结果图:predictions.jpg
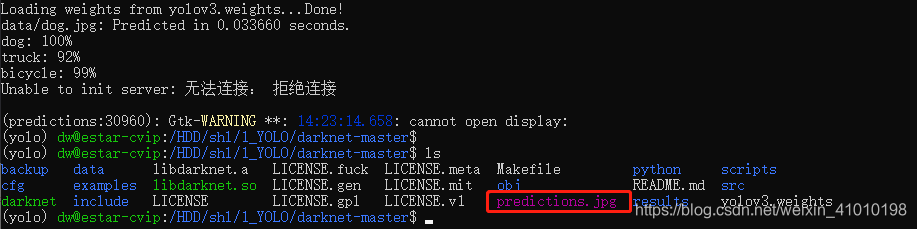
结果图如下:

注意:./darknet其他测试的时候使用其他参数
-i:(索引index)如果有多个GPU,可以设置使用哪一个GPU,eg: -i 1 使用第一块GPU-nogpu:使用CPU训练,我测试了同样上面的一张图片,测试时间为17秒,而且置信度也发生了变化
1.2.2 连续测试多张图片
连续测试多张图片命令(不在命令中指定测试图片路径):
./darknet detect cfg/yolov3.cfg yolov3.weights
当配置和权重加载完成时,会看到如下输出信息提示:
./darknet detect cfg/yolov3.cfg yolov3.weights
layer filters size input output
0 conv 32 3 x 3 / 1 416 x 416 x 3 -> 416 x 416 x 32 0.299 BFLOPs
1 conv 64 3 x 3 / 2 416 x 416 x 32 -> 208 x 208 x 64 1.595 BFLOPs
.......
104 conv 256 3 x 3 / 1 52 x 52 x 128 -> 52 x 52 x 256 1.595 BFLOPs
105 conv 255 1 x 1 / 1 52 x 52 x 256 -> 52 x 52 x 255 0.353 BFLOPs
106 detection
Loading weights from yolov3.weights...Done!
Enter Image Path:
输入一张图片路径:data/horse.jpg 以使其预测该图像的框,结果如下:

完成后,可以输入更多次不同图片的路径进行测试,输入Ctrl+C退出测试
只是显示测试的图片:
./darknet imtest data/dog.jpg
2.2.3 更改检测的阈值(thresh)
默认情况下,yolo仅显示置信度为0.25或更高,可以通过-thresh <val>来设置阈值。例如:要显示所有检测,可以将阈值设置为0
./darknet detect cfg/yolov3.cfg yolov3.weights data/dog.jpg -thresh 0
可以设置不同的阈值,控制模型对阈值的限制,但是不是很有用。
2.2.4 使用Tiny YOLOv3预训练模型测试
如果受自己机器计算资源的限制,可以使用更小的模型yolov3-tiny,其参数也更少,该预训练模型下载:
wget https://pjreddie.com/media/files/yolov3-tiny.weights
用该模型做测试:
./darknet detect cfg/yolov3-tiny.cfg yolov3-tiny.weights data/dog.jpg
2.2.5 使用网络摄像头实时检测
实时检测,必须要有Nvidia GPU,因为在CPU上检测一张图片的时间是10秒左右,不能够达到实时性的要求。因为实时检测会用到CUDA 和 OpenCV,因此要在/darknet/Makefile被编译之前,修改Makefie文件中的GPU=1 和OPENCV=1都设置为1。
1、实时网络摄像头检测,运行如下命令:
./darknet detector demo cfg/coco.data cfg/yolov3.cfg yolov3.weights
如果你有多个摄像头,可以使用-c <num>参数指定使用哪一个摄像头
2、实时检测视频文件,运行如下命令:
./darknet detector demo cfg/coco.data cfg/yolov3.cfg yolov3.weights <video file>
2 darknet训练自己的数据集
2.1 数据集的准备
2.1.1 使用labelImg工具标注自己的数据集
2.1.2 标记好的数据存放位置
1、标记好数据文件结构
首先将自己的数据集标记生成为VOC数据集的格式,至少生成如下格式的文件夹:
Annotations
ImageSets
--Main
--test.txt
--train.txt
--trainval.txt
--val.txt
JPEGImages
Annotations:该文件夹存放的是标记数据集的xml文件(VOC数据集格式)JPEGImage:该文件夹存放的是待标记的原始数据集ImageSets/Main:该文件夹存放的是划分数据集的文件名,文件中的文件名不包含文件后缀
2、标记好数据放到Darknet项目的位置
/darknet/scripts/VOCdevkit/VOC2007
VOCdevkit和VOC两个文件夹需要自己创建:
mkdir -p scripts/VOCdevkit/VOC2007
然后把上面的Annotations、ImageSets、JPEGImage三个文件夹放到VOC2007文件夹下
2.1.3 修改和数据类别相关文件
对/darknet/scripts/voc_label.py文件进行修改:
1、第一处:修改第7行,修改数据集
sets=[('2012', 'train'), ('2012', 'val'), ('2007', 'train'), ('2007', 'val'), ('2007', 'test')]
# 修改为如下:
sets=[('2007', 'train'), ('2007', 'val'), ('2007', 'test')]
2、第二处:修改第9行,修改数据集的类别,改为自己数据集定义的类别
# 把下面类表中定义的类别换成自己定义的类别即可
classes = ["aeroplane", "bicycle", "bird", "boat", "bottle", "bus", "car", "cat", "chair", "cow", "diningtable", "dog", "horse", "motorbike", "person", "pottedplant", "sheep", "sofa", "train", "tvmonitor"]
需要的文件:
- 标记的xml文件,在VOCdevkit/VOC2007/Annotations下
- 划分数据集的文件:ImageSets/Main/train.txt,test.txt,val.txt 里面存的是图片的名字
修改完成以后,运行:voc_label.py文件,生成YOLO训练时使用的labels (labels包含标注物体的位置和类别信息)
python voc_label.py
生成的文件:
运行结束以后,可以在/darknet/scripts/VOCdevkit/VOC2007文件夹内看到labels文件夹,文件夹下是把VOC格式标签文件xml文件转换为的YOLO格式标签txt文件。
- 生成训练数据集大小的n个
YOLO格式的txt文件 - 在
/darknet/scripts文件夹内会生成2007_train.txt、2007_test.txt、2007_val.txt三个文件(文件中的内容是数据集的绝对路径)
eg:008890.txt 是转换后的,第一个数是类别标签,后面的是框的中心坐标以及框的宽和高
(yolo) dw@estar-cvip:/HDD/shl/1_YOLO/darknet-master/scripts/VOCdevkit/VOC2007/labels$ cat 008890.txt
11 0.6213333333333333 0.401 0.6613333333333333 0.19
到这里数据的准备工作就已经全部完成了
下面详细讲解一下:voc_labe.py主要做了什么事
voc_label.py:主要是把标签框的标签进行了归一化
1)标注好的VOC格式的标签xml文件,存储的主要信息为:
- 图片的名字
- 图片的
高height、宽width、通道depth - 标定框的坐标位置:
xmin、ymin、xmax、ymax
例如下图代表的是一样图片:
- 红框代表的是原图大小:height=8,width=8
- 蓝框代表的是标注物体的框:左上角坐标为 (xmin, ymin)=(2,2),右下角的坐标为 (xmax, ymax)=(6,6)
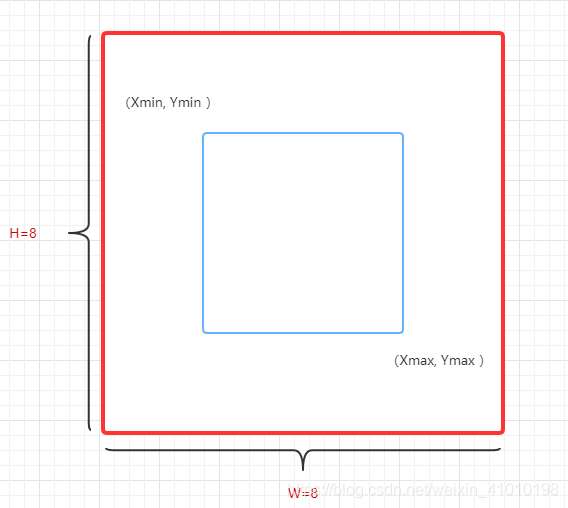
而voc_label.py目的就是把标注为VOC格式数据转化为标注为yolo格式数据: VOC格式标签:图片的实际宽和高,标注框的左上角和右下角坐标YOLO格式标签:标注框的中心坐标(归一化的),标注框的宽和高(归一化的)
VOC格式标签转换为YOLO格式标签计算公式:
框中心的实际坐标(x, y):(一般可能还会在后面减去1)
框归一化后的中心坐标(x, y):
框的高和框(归一化的):
2.2 开始训练自己的数据集
darknet训练命令:
./darknet detector train cfg/voc.data cfg/yolo-voc.cfg darknet19_448.conv.23
上边是进行训练的命令,可以按照上边的命令对文件进行修改。
2.3 修改训练的配置文件
可对上面的训练命令,对文件进行修改
2.3.1 修改cfg/voc.data
classes= 20 //修改为训练分类的个数
train = /home/ws/darknet/scripts/2007_train.txt //修改为数据阶段生成的2007_train.txt文件路径
valid = /home/ws/darknet/scripts/2007_val.txt //修改为数据阶段生成的2007_val.txt文件路径
names = data/voc.names
backup = backup
2.3.2 修改data/voc.names
在上边修改的文件内有一个data/voc.names文件,里边保存目标分类的名称,修改为自己类别的名称即可。
2.3.3 修改cfg/yolo-voc.cfg
第一处
文件开头的配置文件可以按照下边的说明进行修改
# Testing
#batch=1
#subdivisions=1
# Training
batch=64 //每次迭代要进行训练的图片数量 ,在一定范围内,一般来说Batch_Size越大,其确定的下降方向越准,引起的训练震荡越小。
subdivisions=8 //源码中的图片数量int imgs = net.batch * net.subdivisions * ngpus,按subdivisions大小分批进行训练
height=416 //输入图片高度,必须能被32整除
width=416 //输入图片宽度,必须能被32整除
channels=3 //输入图片通道数
momentum=0.9 //冲量
decay=0.0005 //权值衰减
angle=0 //图片角度变化,单位为度,假如angle=5,就是生成新图片的时候随机旋转-5~5度
saturation = 1.5 //饱和度变化大小
exposure = 1.5 //曝光变化大小
hue=.1 //色调变化范围,tiny-yolo-voc.cfg中-0.1~0.1
learning_rate=0.001 //学习率
burn_in=1000
max_batches = 120200 //训练次数
policy=steps //调整学习率的策略
steps=40000,80000 //根据batch_num调整学习率,若steps=100,25000,35000,则在迭代100次,25000次,35000次时学习率发生变化,该参数与policy中的steps对应
scales=.1,.1 //相对于当前学习率的变化比率,累计相乘,与steps中的参数个数保持一致;
**注意:**如果修改max_batches总的训练次数,也需要对应修改steps,适当调整学习率。
具体的含义可以查看YOLO网络中参数的解读
第二处
修改107行最后一个卷积层中filters,按照filter=5*(classes+5)来进行修改。如果类目为3,则为5*(3+5)=40。
[convolutional]
size=1
stride=1
pad=1
filters=40 //计算公式为:filter=3*(classes+5)
activation=linear
第三处
修改类别数,直接搜索关键词“classes”即可,全文就一个。
classes=3
修改好之后,可以开始进行训练:
./darknet detector train cfg/voc.data cfg/yolo-voc.cfg darknet19_448.conv.23 >> log.txt
输入上边的指令就可以进行训练,在命令最后的命令>> log.txt是将输出的日志保存到log.txt文件内,这样便于后期训练结果的查看。
3 测试
3.1 单张图像测试
./darknet detect cfg/yolo-voc.cfg backup/yolo-voc_final.weights data/dog.jpg
./darknet detect [训练cfg文件路径] [权重文件路径] [检测图片的路径]
按照上边的格式进行填写即可。
3.2 多张图像测试
./darknet detect cfg/yolov3.cfg yolov3.weights
3.3 网络摄像头或视频文件测试
加一个参数demo
1、网络摄像头实时检测
./darknet detector demo cfg/coco.data cfg/yolov3.cfg yolov3.weights
2、视频文件实时检测
./darknet detector demo cfg/coco.data cfg/yolov3.cfg yolov3.weights <video file>
3.3 测试数据集测试mAP、recall等参数
参考1:https://pjreddie.com/darknet/install/
参考2:https://pjreddie.com/darknet/yolo/ # yolov3训练自己的数据集
参考3:https://blog.csdn.net/qq_35451572/article/details/80384674
参考4:https://www.cnblogs.com/laozhanghahaha/p/10527474.html