from urllib import request
import re
import pandas as pd
url = "https://tophub.today/n/Jb0vmloB1G"
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36'}
aaa = request.Request(url, headers=headers) #模拟请求头,访问网页
bbb = request.urlopen(aaa).read().decode('utf-8') #请求今日热榜百度热搜网址
title=re.compile(r'itemid="[0-9]*">(.*?)</a>') #正则提取网页中的“今日热议”
num=re.compile(r'<td>(.*?)</td>') #正则提取网页中的“热度”
titles=title.findall(bbb)[0:10] #匹配“今日热议”正则十次
nums=num.findall(bbb)[0:10] #匹配“今日热议”正则十次
m={"今日热议":titles,"热度":nums}
file=pd.DataFrame(m)
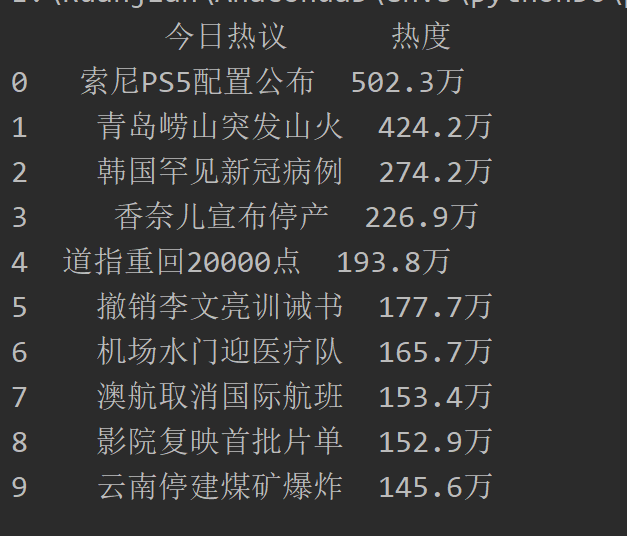
print(file)