在“信息平台和数据科学家的崛起”中,Jeff Hammerbacher将信息平台描述为“他们的公司努力吸收、处理和产生信息的中心”,以及他们如何“促进从经验数据中学习的过程”。“Jeff团队在Face book上开发的信息平台的最大组成部分是Apache Hive,它是Hadoop上的数据仓库框架。
Hive从需要管理和学习的大量数据中成长起来,这是Facebook每天从蓬勃发展的社交网络中产生的海量数据。在尝试了几个不同的系统之后,团队选择了Hadoop来进行存储和处理,因为它的成本是有效的,并且满足了可伸缩性需求。
创建Hive是为了让具有强大SQL技能的分析师(但Java编程技能不高)能够对Facebook存储在HDFS上的海量数据进行查询。如今,Hive是一个成功的Apache项目,它被许多组织用作通用的、可扩展的数据处理平台。当然,SQL并不适合每一个大的数据问题,它不适合构建复杂的机器学习算法,但是它对很多分析来说都是很好的,而且它在业界非常有名。此外,SQL是商业智能工具中的通用语言(例如,ODBC是一个通用的桥梁),所以Hive可以很好地与这些产品集成。
一、定义
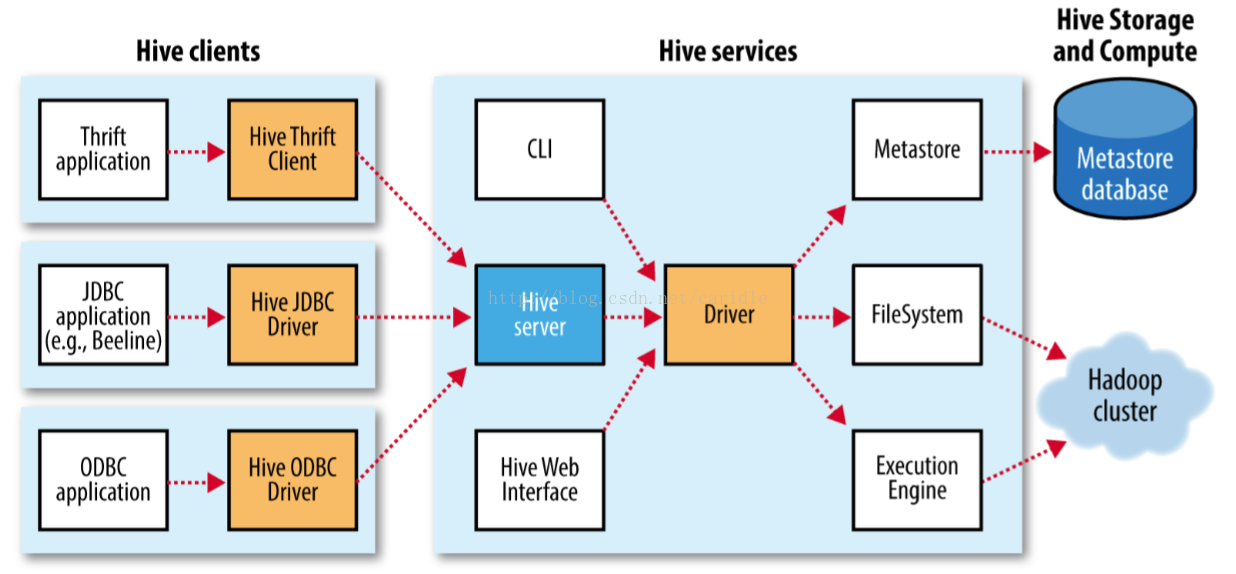

1)数据单元
按照数据的粒度大小,hive数据可以被组织成:
1)databases: 避免不同表产生命名冲突的一种命名空间
2)tables:具有相同scema的同质数据的集合
3)partitions:一个表可以有一个或多个决定数据如何存储的partition key
4)buckets(或clusters):在同一个partition中的数据可以根据某个列的hash值分为多个bucket。partition和bucket并非必要,但是它们能大大加快数据的查询速度。
2)、数据类型
(1)简单类型:
TINYINT - 1 byte integer
SMALLINT - 2 byte integer
INT - 4 byte integer
BIGINT - 8 byte
BOOLEAN - TRUE/ FALSE
FLOAT - 单精度
DOUBLE - 双精度
- DECIMAL—一个固定的点值,用户定义的尺度和精度
- VARCHAR—特定的字符序列,具有最大长度
- CHAR—具有指定指定长度的字符集中的字符序列
- TIMESTAMP—一个特定的时间点,达到纳秒精度
- DATE—一个日期
- BINARY—字节序列
STRING - 字符串集合
(2)复杂类型:
Structs : structs内部的数据可以通过DOT(.)来存取,例如,表中一列c的类型为STRUCT{a INT; b INT},我们可以通过c.a来访问域a。
Maps(Key-Value对) :访问指定域可以通过['element name']进行,例如,一个Map M包含了一个group->gid的k-v对,gid的值可以通过M['group']来获取。
Arrays: array中的数据为相同类型,例如,假如array A中元素['a','b','c'],则A[1]的值为'b'。
3)、内建运算符和函数
包括关系运算符(A=B, A!=B, A<B等等)、
算术运算符(A+B, A*B, A&B, A|B等等)、
逻辑运算符(A&&B, A|B等等)、
复杂类型上的运算符(A[n], M[key], S.x)、
各种内建函数:round,floor,substr
4)、语言能力
hive查询语言提供基本的类sql操作,这些操作基于table和partition,包括:
1. 使用where语句过滤制定行
2. 使用select查找指定列
3. join两张table
4. group by
5. 一个表的查询结果存入另一张表
6. 将一个表的内容存入本地目录
7. 将查询结果存储到hdfs上
8. 管理table和partition(creat、drop、alert)
9. 在查询中嵌入map-reduce程序
1. 等值比较: =
语法:A=B
操作类型:所有基本类型
描述: 如果表达式A与表达式B相等,则为TRUE;否则为FALSE
举例:
Hive>select 1 from lxw_dual where 1=1;
2. 不等值比较: <>
语法: A <> B
操作类型: 所有基本类型
描述: 如果表达式A为NULL,或者表达式B为NULL,返回NULL;如果表达式A与表达式B不相等,则为TRUE;否则为FALSE
举例:
hive> select1 from lxw_dual where 1 <> 2;
注意:
由于在通常得SQL写法中不等于也可以这样写 != 。但在hive中,当一个string类型和int类型比较的时候会出现问题。
数字和数字类型用 可以用 != 比较:
- hive> select * from t_pvorder where 1 != 1 and start_date=20130306 limit 1;
- OK
- Time taken: 0.079 seconds
带引号的数字和数字类型 可以用!= 比较:
- hive> select * from t_pvorder where "136258563267" != 0 and start_date=20130306 limit 1;
- OK
- 1323499396180741 13437046875509ec 0 102213 100002 01 -1 2013-03-06 20:59:07 1362574747440zW4 20130306
- Time taken: 0.169 seconds
带引号的数字和带引号数字类型 可以用 != 比较:
- hive> select * from t_pvorder where "136258563267" != "0" and start_date=20130306 limit 1;
- OK
- 1323499396180741 13437046875509ec 0 102213 100002 01 -1 2013-03-06 20:59:07 1362574747440zW4 20130306
- Time taken: 0.129 seconds
字符串和数字类型 不可以用 !=比较:
- hive> select * from t_pvorder where 0 != "1362585632671uFu" and start_date=20130306 limit 1;
- Total MapReduce jobs = 1
- Launching Job 1 out of 1
- Number of reduce tasks is set to 0 since there's no reduce operator
- //发起mapreduce 查不出结果
- ....
字符串和数字类型 不可以用 <> 比较:
- hive> select * from t_pvorder where 0 <> "1362585632671uFu" and start_date=20130306 limit 1;
- Total MapReduce jobs = 1
- Launching Job 1 out of 1
- Number of reduce tasks is set to 0 since there's no reduce operator
- //发起mapreduce <span style="font-family: Arial, Helvetica, sans-serif;">查不出结果</span>
- ....
总之,用不等于比较的时候两者的字段类型尽量保持一致。
3. 小于比较: <
语法: A < B
操作类型: 所有基本类型
描述: 如果表达式A为NULL,或者表达式B为NULL,返回NULL;如果表达式A小于表达式B,则为TRUE;否则为FALSE
举例:
hive> select1 from lxw_dual where 1 < 2;
4. 小于等于比较: <=
语法: A <= B
操作类型: 所有基本类型
描述: 如果表达式A为NULL,或者表达式B为NULL,返回NULL;如果表达式A小于或者等于表达式B,则为TRUE;否则为FALSE
举例:
hive> select1 from lxw_dual where 1 <= 1;
5. 大于比较: >
语法: A > B
操作类型: 所有基本类型
描述: 如果表达式A为NULL,或者表达式B为NULL,返回NULL;如果表达式A大于表达式B,则为TRUE;否则为FALSE
举例:
hive> select1 from lxw_dual where 2 > 1;
6. 大于等于比较: >=
语法: A >= B
操作类型: 所有基本类型
描述: 如果表达式A为NULL,或者表达式B为NULL,返回NULL;如果表达式A大于或者等于表达式B,则为TRUE;否则为FALSE
举例:
hive> select1 from lxw_dual where 1 >= 1;
注意:String的比较要注意(常用的时间比较可以先to_date之后再比较)
hive> select* from lxw_dual;
OK
201111120900:00:00 2011111209
hive> selecta,b,a<b,a>b,a=b from lxw_dual;
201111120900:00:00 2011111209 false true false
7. 空值判断: IS NULL
语法: A IS NULL
操作类型: 所有类型
描述: 如果表达式A的值为NULL,则为TRUE;否则为FALSE
举例:
hive> select1 from lxw_dual where null is null;
8. 非空判断: IS NOTNULL
语法: A IS NOT NULL
操作类型: 所有类型
描述: 如果表达式A的值为NULL,则为FALSE;否则为TRUE
举例:
hive> select1 from lxw_dual where 1 is not null;
9. LIKE比较: LIKE
语法: A LIKE B
操作类型: strings
描述: 如果字符串A或者字符串B为NULL,则返回NULL;如果字符串A符合表达式B 的正则语法,则为TRUE;否则为FALSE。B中字符”_”表示任意单个字符,而字符”%”表示任意数量的字符。
举例:
hive> select1 from lxw_dual where 'football' like 'foot%';
hive> select1 from lxw_dual where 'football' like 'foot____';
注意:否定比较时候用NOT ALIKE B
hive> select1 from lxw_dual where NOT 'football' like 'fff%';
10. JAVA的LIKE操作: RLIKE
语法: A RLIKE B
操作类型: strings
描述: 如果字符串A或者字符串B为NULL,则返回NULL;如果字符串A符合Java正则表达式B的正则语法,则为TRUE;否则为FALSE。
举例:
hive> select1 from lxw_dual where 'footbar’ rlike '^f.*r$’;
注意:判断一个字符串是否全为数字:
hive>select 1from lxw_dual where '123456' rlike '^\\d+$';
hive> select1 from lxw_dual where '123456aa' rlike '^\\d+$';
11. REGEXP操作: REGEXP
语法: A REGEXP B
操作类型: strings
描述: 功能与RLIKE相同
举例:
hive> select1 from lxw_dual where 'footbar' REGEXP '^f.*r$';
1.字符串长度函数:length
语法: length(string A)
返回值: int
说明:返回字符串A的长度
举例:
Hive> select length(‘abcedfg’) from lxw_dual;
7
2. 字符串反转函数:reverse
语法: reverse(string A)
返回值: string
说明:返回字符串A的反转结果
举例:
hive> select reverse(abcedfg’) from lxw_dual;
gfdecba
3.字符串连接函数:concat
语法: concat(string A, string B…)
返回值: string
说明:返回输入字符串连接后的结果,支持任意个输入字符串
举例:
hive> select concat(‘abc’,’def’,’gh’) from lxw_dual;
abcdefgh
4.带分隔符字符串连接函数:concat_ws
语法: concat_ws(string SEP, string A, string B…)
返回值: string
说明:返回输入字符串连接后的结果,SEP表示各个字符串间的分隔符
举例:
hive> select concat_ws(‘,’,’abc’,’def’,’gh’) from lxw_dual;
abc,def,gh
5.字符串截取函数:substr,substring
语法: substr(string A, int start),substring(string A, int start)
返回值: string
说明:返回字符串A从start位置到结尾的字符串
举例:
hive> select substr(‘abcde’,3) from lxw_dual;
cde
hive> select substring(‘abcde’,3) from lxw_dual;
cde
hive> selectsubstr(‘abcde’,-1) from lxw_dual; (和Oracle相同)
e
6.字符串截取函数:substr,substring
语法: substr(string A, int start, int len),substring(string A, intstart, int len)
返回值: string
说明:返回字符串A从start位置开始,长度为len的字符串
举例:
hive> select substr(‘abcde’,3,2) from lxw_dual;
cd
hive> select substring(‘abcde’,3,2) from lxw_dual;
cd
hive>select substring(‘abcde’,-2,2) from lxw_dual;
de
7.字符串转大写函数:upper,ucase
语法: upper(string A) ucase(string A)
返回值: string
说明:返回字符串A的大写格式
举例:
hive> select upper(‘abSEd’) from lxw_dual;
ABSED
hive> select ucase(‘abSEd’) from lxw_dual;
ABSED
8.字符串转小写函数:lower,lcase
语法: lower(string A) lcase(string A)
返回值: string
说明:返回字符串A的小写格式
举例:
hive> select lower(‘abSEd’) from lxw_dual;
absed
hive> select lcase(‘abSEd’) from lxw_dual;
absed
9.去空格函数:trim
语法: trim(string A)
返回值: string
说明:去除字符串两边的空格
举例:
hive> select trim(’ abc ‘) from lxw_dual;
abc
10.左边去空格函数:ltrim
语法: ltrim(string A)
返回值: string
说明:去除字符串左边的空格
举例:
hive> select ltrim(’ abc ‘) from lxw_dual;
abc
11.右边去空格函数:rtrim
语法: rtrim(string A)
返回值: string
说明:去除字符串右边的空格
举例:
hive> select rtrim(’ abc ‘) from lxw_dual;
abc
12.正则表达式替换函数:regexp_replace
语法: regexp_replace(string A, string B, string C)
返回值: string
说明:将字符串A中的符合Java正则表达式B的部分替换为C。注意,在有些情况下要使用转义字符,类似oracle中的regexp_replace函数。
举例:
hive> select regexp_replace(‘foobar’, ‘oo|ar’, ”) from lxw_dual;
fb
13.正则表达式解析函数:regexp_extract
语法: regexp_extract(string subject, string pattern, int index)
返回值: string
说明:将字符串subject按照pattern正则表达式的规则拆分,返回index指定的字符。
举例:
hive> select regexp_extract(‘foothebar’, ‘foo(.*?)(bar)’, 1) fromlxw_dual;
the
hive> select regexp_extract(‘foothebar’, ‘foo(.*?)(bar)’, 2) fromlxw_dual;
bar
hive> select regexp_extract(‘foothebar’, ‘foo(.*?)(bar)’, 0) fromlxw_dual;
foothebar
注意,在有些情况下要使用转义字符,下面的等号要用双竖线转义,这是java正则表达式的规则。
select data_field,
regexp_extract(data_field,'.*?bgStart\\=([^&]+)',1) as aaa,
regexp_extract(data_field,'.*?contentLoaded_headStart\\=([^&]+)',1) as bbb,
regexp_extract(data_field,'.*?AppLoad2Req\\=([^&]+)',1) as ccc
from pt_nginx_loginlog_st
where pt = '2012-03-26'limit 2;
14.URL解析函数:parse_url
语法: parse_url(string urlString, string partToExtract [, stringkeyToExtract])
返回值: string
说明:返回URL中指定的部分。partToExtract的有效值为:HOST, PATH, QUERY, REF, PROTOCOL, AUTHORITY, FILE, and USERINFO.
举例:
hive> selectparse_url(‘http://facebook.com/path1/p.php?k1=v1&k2=v2#Ref1‘, ‘HOST’) fromlxw_dual;
facebook.com
hive> selectparse_url(‘http://facebook.com/path1/p.php?k1=v1&k2=v2#Ref1‘, ‘QUERY’,’k1’) from lxw_dual;
v1
15.json解析函数:get_json_object
语法: get_json_object(string json_string, string path)
返回值: string
说明:解析json的字符串json_string,返回path指定的内容。如果输入的json字符串无效,那么返回NULL。
举例:
hive> select get_json_object(‘{“store”:
{“fruit”:[{“weight”:8,”type”:”apple”},{“weight”:9,”type”:”pear”}],
“bicycle”:{“price”:19.95,”color”:”red”}
},
“email”:”amy@only_for_json_udf_test.NET”,
“owner”:”amy”
}
‘,’$.owner’) from lxw_dual;
amy
16.空格字符串函数:space
语法: space(int n)
返回值: string
说明:返回长度为n的字符串
举例:
hive> select space(10) from lxw_dual;
hive> select length(space(10)) from lxw_dual;
10
17.重复字符串函数:repeat
语法: repeat(string str, int n)
返回值: string
说明:返回重复n次后的str字符串
举例:
hive> select repeat(‘abc’,5) from lxw_dual;
abcabcabcabcabc
18.首字符ascii函数:ascii
语法: ascii(string str)
返回值: int
说明:返回字符串str第一个字符的ascii码
举例:
hive> select ascii(‘abcde’) from lxw_dual;
97
19.左补足函数:lpad
语法: lpad(string str, int len, string pad)
返回值: string
说明:将str进行用pad进行左补足到len位
举例:
hive> select lpad(‘abc’,10,’td’) from lxw_dual;
tdtdtdtabc
注意:与GP,ORACLE不同,pad 不能默认
20.右补足函数:rpad
语法: rpad(string str, int len, string pad)
返回值: string
说明:将str进行用pad进行右补足到len位
举例:
hive> select rpad(‘abc’,10,’td’) from lxw_dual;
abctdtdtdt
21.分割字符串函数: split
语法: split(string str, stringpat)
返回值: array
说明: 按照pat字符串分割str,会返回分割后的字符串数组
举例:
hive> select split(‘abtcdtef’,’t’) from lxw_dual;
[“ab”,”cd”,”ef”]
22.集合查找函数:find_in_set
语法: find_in_set(string str, string strList)
返回值: int
说明: 返回str在strlist第一次出现的位置,strlist是用逗号分割的字符串。如果没有找该str字符,则返回0
举例:
hive> select find_in_set(‘ab’,’ef,ab,de’) from lxw_dual;
2
hive> select find_in_set(‘at’,’ef,ab,de’) from lxw_dual;
0

1.字符串长度函数:length
语法: length(string A)
返回值: int
说明:返回字符串A的长度
举例:
Hive> select length(‘abcedfg’) from lxw_dual;
7
2. 字符串反转函数:reverse
语法: reverse(string A)
返回值: string
说明:返回字符串A的反转结果
举例:
hive> select reverse(abcedfg’) from lxw_dual;
gfdecba
3.字符串连接函数:concat
语法: concat(string A, string B…)
返回值: string
说明:返回输入字符串连接后的结果,支持任意个输入字符串
举例:
hive> select concat(‘abc’,’def’,’gh’) from lxw_dual;
abcdefgh
4.带分隔符字符串连接函数:concat_ws
语法: concat_ws(string SEP, string A, string B…)
返回值: string
说明:返回输入字符串连接后的结果,SEP表示各个字符串间的分隔符
举例:
hive> select concat_ws(‘,’,’abc’,’def’,’gh’) from lxw_dual;
abc,def,gh
5.字符串截取函数:substr,substring
语法: substr(string A, int start),substring(string A, int start)
返回值: string
说明:返回字符串A从start位置到结尾的字符串
举例:
hive> select substr(‘abcde’,3) from lxw_dual;
cde
hive> select substring(‘abcde’,3) from lxw_dual;
cde
hive> selectsubstr(‘abcde’,-1) from lxw_dual; (和Oracle相同)
e
6.字符串截取函数:substr,substring
语法: substr(string A, int start, int len),substring(string A, intstart, int len)
返回值: string
说明:返回字符串A从start位置开始,长度为len的字符串
举例:
hive> select substr(‘abcde’,3,2) from lxw_dual;
cd
hive> select substring(‘abcde’,3,2) from lxw_dual;
cd
hive>select substring(‘abcde’,-2,2) from lxw_dual;
de
7.字符串转大写函数:upper,ucase
语法: upper(string A) ucase(string A)
返回值: string
说明:返回字符串A的大写格式
举例:
hive> select upper(‘abSEd’) from lxw_dual;
ABSED
hive> select ucase(‘abSEd’) from lxw_dual;
ABSED
8.字符串转小写函数:lower,lcase
语法: lower(string A) lcase(string A)
返回值: string
说明:返回字符串A的小写格式
举例:
hive> select lower(‘abSEd’) from lxw_dual;
absed
hive> select lcase(‘abSEd’) from lxw_dual;
absed
9.去空格函数:trim
语法: trim(string A)
返回值: string
说明:去除字符串两边的空格
举例:
hive> select trim(’ abc ‘) from lxw_dual;
abc
10.左边去空格函数:ltrim
语法: ltrim(string A)
返回值: string
说明:去除字符串左边的空格
举例:
hive> select ltrim(’ abc ‘) from lxw_dual;
abc
11.右边去空格函数:rtrim
语法: rtrim(string A)
返回值: string
说明:去除字符串右边的空格
举例:
hive> select rtrim(’ abc ‘) from lxw_dual;
abc
12.正则表达式替换函数:regexp_replace
语法: regexp_replace(string A, string B, string C)
返回值: string
说明:将字符串A中的符合Java正则表达式B的部分替换为C。注意,在有些情况下要使用转义字符,类似oracle中的regexp_replace函数。
举例:
hive> select regexp_replace(‘foobar’, ‘oo|ar’, ”) from lxw_dual;
fb
13.正则表达式解析函数:regexp_extract
语法: regexp_extract(string subject, string pattern, int index)
返回值: string
说明:将字符串subject按照pattern正则表达式的规则拆分,返回index指定的字符。
举例:
hive> select regexp_extract(‘foothebar’, ‘foo(.*?)(bar)’, 1) fromlxw_dual;
the
hive> select regexp_extract(‘foothebar’, ‘foo(.*?)(bar)’, 2) fromlxw_dual;
bar
hive> select regexp_extract(‘foothebar’, ‘foo(.*?)(bar)’, 0) fromlxw_dual;
foothebar
注意,在有些情况下要使用转义字符,下面的等号要用双竖线转义,这是java正则表达式的规则。
select data_field,
regexp_extract(data_field,'.*?bgStart\\=([^&]+)',1) as aaa,
regexp_extract(data_field,'.*?contentLoaded_headStart\\=([^&]+)',1) as bbb,
regexp_extract(data_field,'.*?AppLoad2Req\\=([^&]+)',1) as ccc
from pt_nginx_loginlog_st
where pt = '2012-03-26'limit 2;
14.URL解析函数:parse_url
语法: parse_url(string urlString, string partToExtract [, stringkeyToExtract])
返回值: string
说明:返回URL中指定的部分。partToExtract的有效值为:HOST, PATH, QUERY, REF, PROTOCOL, AUTHORITY, FILE, and USERINFO.
举例:
hive> selectparse_url(‘http://facebook.com/path1/p.php?k1=v1&k2=v2#Ref1‘, ‘HOST’) fromlxw_dual;
facebook.com
hive> selectparse_url(‘http://facebook.com/path1/p.php?k1=v1&k2=v2#Ref1‘, ‘QUERY’,’k1’) from lxw_dual;
v1
15.json解析函数:get_json_object
语法: get_json_object(string json_string, string path)
返回值: string
说明:解析json的字符串json_string,返回path指定的内容。如果输入的json字符串无效,那么返回NULL。
举例:
hive> select get_json_object(‘{“store”:
{“fruit”:[{“weight”:8,”type”:”apple”},{“weight”:9,”type”:”pear”}],
“bicycle”:{“price”:19.95,”color”:”red”}
},
“email”:”amy@only_for_json_udf_test.NET”,
“owner”:”amy”
}
‘,’$.owner’) from lxw_dual;
amy
16.空格字符串函数:space
语法: space(int n)
返回值: string
说明:返回长度为n的字符串
举例:
hive> select space(10) from lxw_dual;
hive> select length(space(10)) from lxw_dual;
10
17.重复字符串函数:repeat
语法: repeat(string str, int n)
返回值: string
说明:返回重复n次后的str字符串
举例:
hive> select repeat(‘abc’,5) from lxw_dual;
abcabcabcabcabc
18.首字符ascii函数:ascii
语法: ascii(string str)
返回值: int
说明:返回字符串str第一个字符的ascii码
举例:
hive> select ascii(‘abcde’) from lxw_dual;
97
19.左补足函数:lpad
语法: lpad(string str, int len, string pad)
返回值: string
说明:将str进行用pad进行左补足到len位
举例:
hive> select lpad(‘abc’,10,’td’) from lxw_dual;
tdtdtdtabc
注意:与GP,ORACLE不同,pad 不能默认
20.右补足函数:rpad
语法: rpad(string str, int len, string pad)
返回值: string
说明:将str进行用pad进行右补足到len位
举例:
hive> select rpad(‘abc’,10,’td’) from lxw_dual;
abctdtdtdt
21.分割字符串函数: split
语法: split(string str, stringpat)
返回值: array
说明: 按照pat字符串分割str,会返回分割后的字符串数组
举例:
hive> select split(‘abtcdtef’,’t’) from lxw_dual;
[“ab”,”cd”,”ef”]
22.集合查找函数:find_in_set
语法: find_in_set(string str, string strList)
返回值: int
说明: 返回str在strlist第一次出现的位置,strlist是用逗号分割的字符串。如果没有找该str字符,则返回0
举例:
hive> select find_in_set(‘ab’,’ef,ab,de’) from lxw_dual;
2
hive> select find_in_set(‘at’,’ef,ab,de’) from lxw_dual;
0