文章目录
什么是Hive
- 数据库与数据仓库
数据库:
mysql、oracle、sqlserver、DB2、sqlite、MDB
数据仓库:
Hive,是MR的客户端,也就是说不必要每台机器都安装部署Hive - 本质是什么?
Hive的特性
1、操作接口是采用SQL语法,HQL
2、避免了写MapReduce的繁琐过程
3、不介入在线业务
因为hive是操作MapReduce的,MapReduce就是不介入在线业务的,这里的MapReduce指的是Hadoop中的MapReduce,此外storm等中也有MapReduce是在线的,MapReduce其实是一个概念,不是一个实际的框架。
Hive体系结构
1、Client(两种)
** 终端命令行
** JDBC – 不常用,非常麻烦(相对于前者)
2、metastore
** 原本的数据集和字段名称以及数据信息之间的双射关系。
** 我们目前是存储在Mysql中
3、Server-Hadoop
** 在操作Hive的同时,需要将Hadoop的HDFS开启,YARN开启,MAPRED配置好
基本思想

在HDFS中有三个资源的txt文件,将字段和字段对应的名称做一个唯一映射,这个映射存储在数据库MySql中,数据库的名字叫metastore,数据库中存着,第一个字段对应age,第二个字段对应sex,第三个字段对应name,还要告诉hive,当我使用hive去读取文件的时候,每个字段中间用什么分割,假设中间是/t,然后hive,读取数据的时候,告诉hive,每个字段中间以/t分割,第一个字段叫age,第二个字段叫sex,第三个字段叫name。Hive要做的工作就是将HDFS中的内容读取到Hive中,然后再根据mysql映射过来的字段信息,对应的读取文件中的内容,这样表面上会产生一种错局,就好像在操作数据库一样
Hive把拿到的数据通过sql语句,转化为MR代码,最终打成jar包,提交到yarn上面,然后直接执行这个语句,对于用户操作来讲,好像是写了一段sql语句之后,然后就出现了结果。
Hive的部署与安装
1、解压Hive到安装目录
$ tar -zxf /opt/softwares/hive-0.13.1-cdh5.3.6.tar.gz -C ./
2、重命名配置文件
$ mv hive-default.xml.template hive-site.xml
$ mv hive-env.sh.template hive-env.sh
3、hive-env.sh
JAVA_HOME=/opt/modules/jdk1.8.0_121
HADOOP_HOME=/opt/modules/cdh/hadoop-2.5.0-cdh5.3.6/
export HIVE_CONF_DIR=/opt/modules/cdh/hive-0.13.1-cdh5.3.6/conf
4、安装Mysql
$ su - root
# yum -y install mysql mysql-server mysql-devel
# wget http://dev.mysql.com/get/mysql-community-release-el7-5.noarch.rpm
# rpm -ivh mysql-community-release-el7-5.noarch.rpm
# yum -y install mysql-community-server
尖叫提示:如果使用离线绿色版本(免安装版本,即解压出来直接用的那种)需要手动初始化Mysql数据库
5、配置Mysql
** 开启Mysql服务
# systemctl start mysqld.service
** 设置root用户密码
# mysqladmin -uroot password ‘123456’
** 为用户以及其他机器节点授权
//为其他的机器mysql设置成root 123456 登录,如果是admin用户,则下面的语句变成root@XXXX,hadoop-senior01.itguigu.com是ip,配置完一个,再配置其他的,如hadoop-senior02.itguigu.com
//*.*的意思是所有的数据库里面的所有的表的意思,.左边是数据库,右边是表
mysql> grant all on . to root@‘hadoop-senior01.itguigu.com’ identified by ‘123456’;
grant all on . to root@‘hadoop104’ identified by ‘000000’;
grant:授权
all:所有权限
.:数据库名称.表名称
root:操作mysql的用户
@’’:主机名
密码:123456
** hive-site.xml
<property>
<name>javax.jdo.option.ConnectionURL</name>
//配置数据库,不存在的话就创建一个
<value>jdbc:mysql://hadoop-senior01.itguigu.com:3306/metastore?createDatabaseIfNotExist=true</value>
<description>JDBC connect string for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
<description>Driver class name for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
<description>username to use against metastore database</description>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456</value>
<description>password to use against metastore database</description>
</property>
** hive-log4j.properties
hive.log.dir=/opt/modules/cdh/hive-0.13.1-cdh5.3.6/logs(没有的话就新建)
默认是 $ {java.io.tmpdir}/${user.name}
** 拷贝数据库驱动包到Hive根目录下的lib文件夹
$ cp -a mysql-connector-java-5.1.27-bin.jar /opt/modules/cdh/hive-0.13.1-cdh5.3.6/lib/
** 启动Hive
$ bin/hive
查看mysql数据库
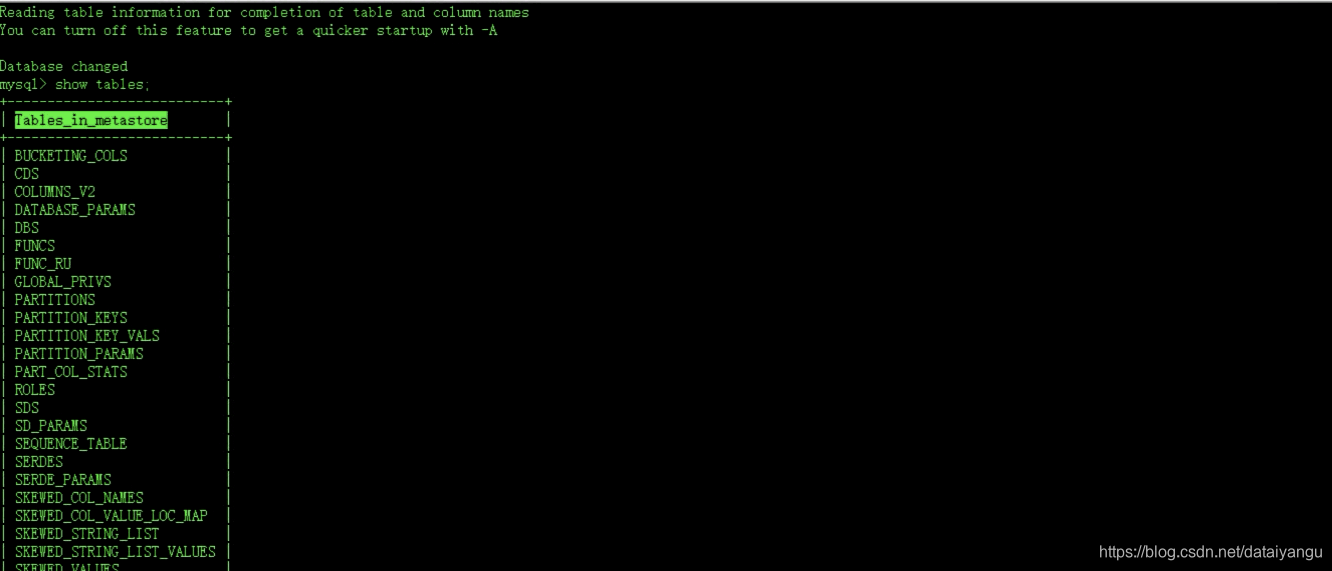
发现有metastore数据库,注意这个mysql的数据库需要定时的备份,否则可能导致hive不能用。
在hive中进行基本的数据库操作
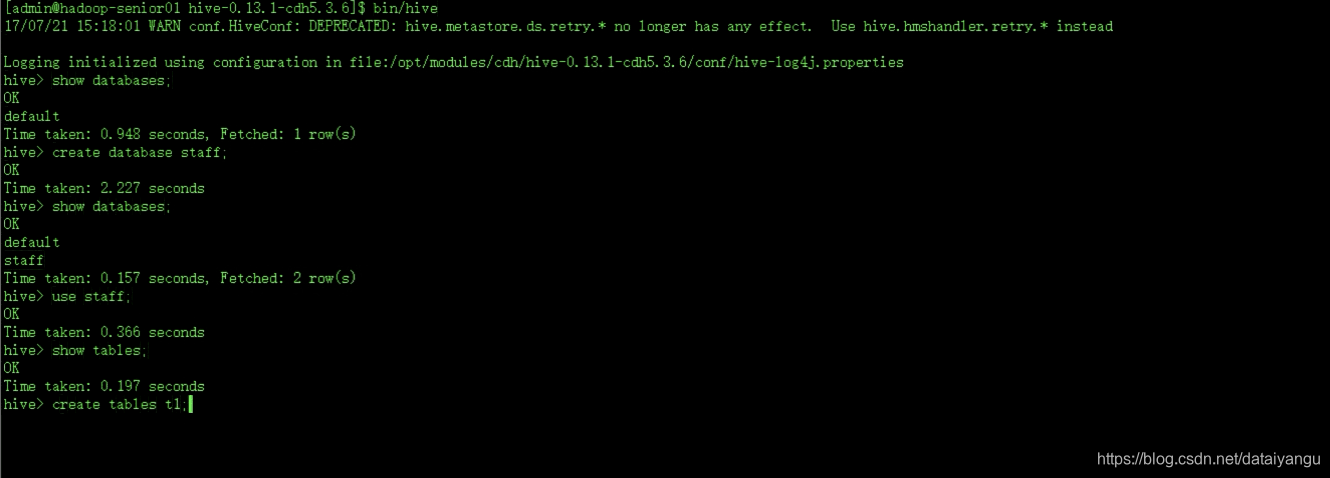
但是注意如果建表直接通过create tables t1的话是不行的,因为还需要分隔符等的信息。
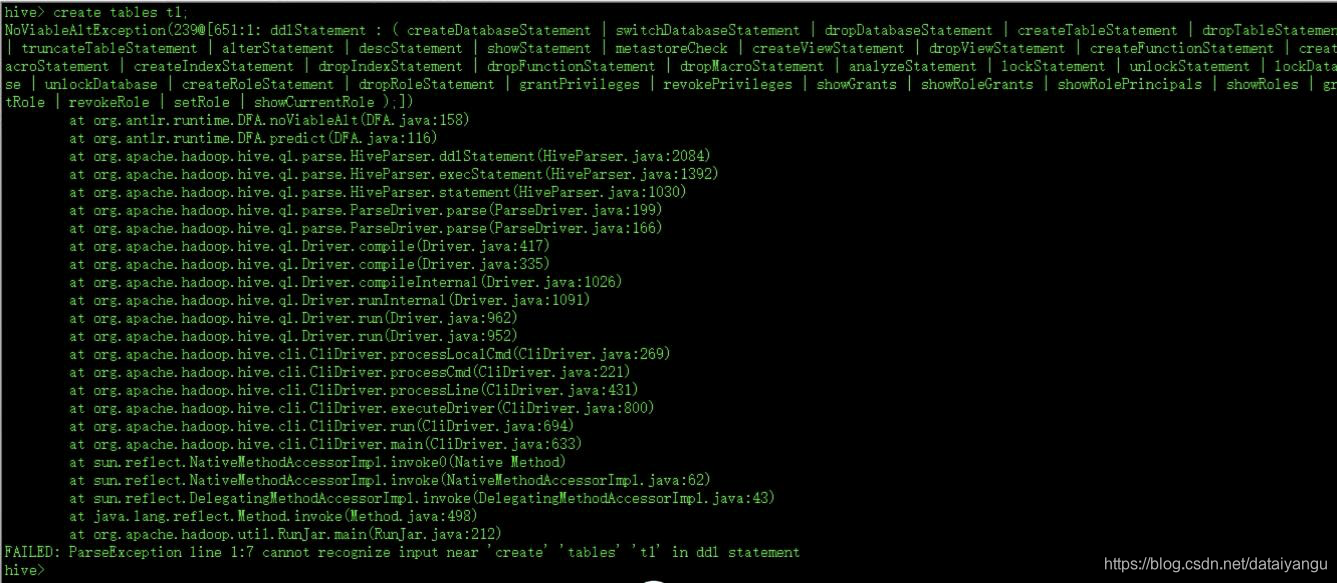
在hive-site.xml文件中
//hive数据仓库在hdfs中的目录,默认的目录,当然视可以改的。
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hibe/warehouse</value>
<description>locatoin of default for the warehouse</description>
</property>
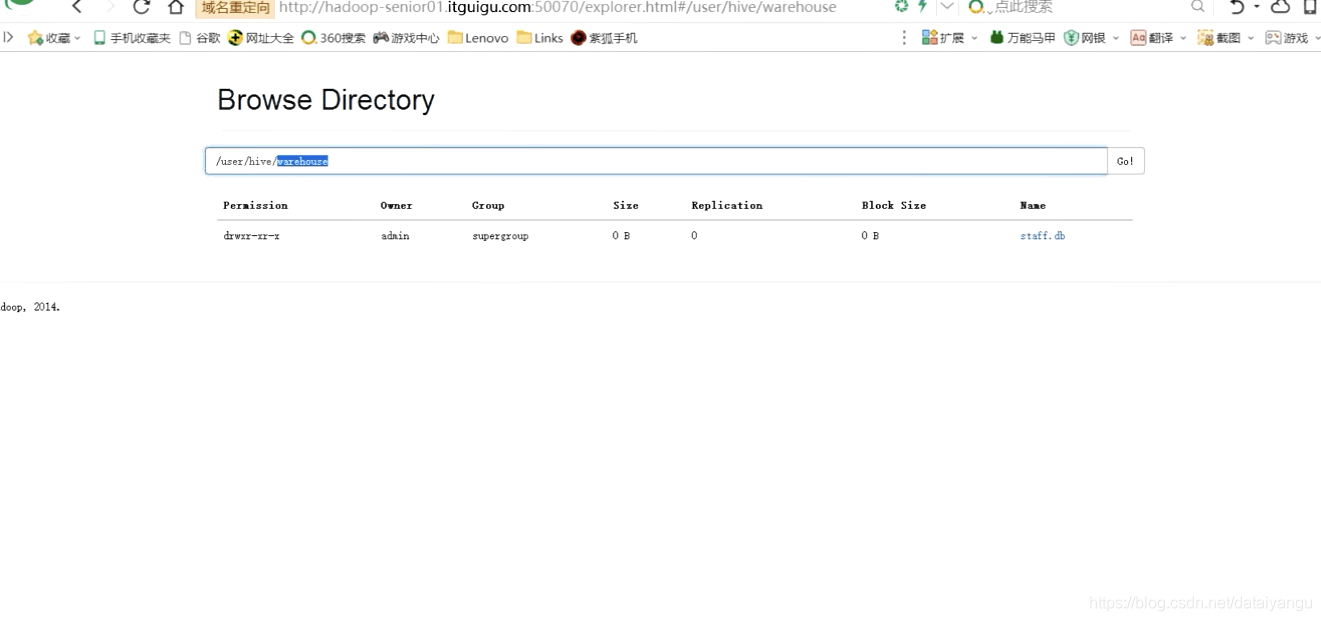
在hive中创建的数据库和表,都会存到这个目录下。
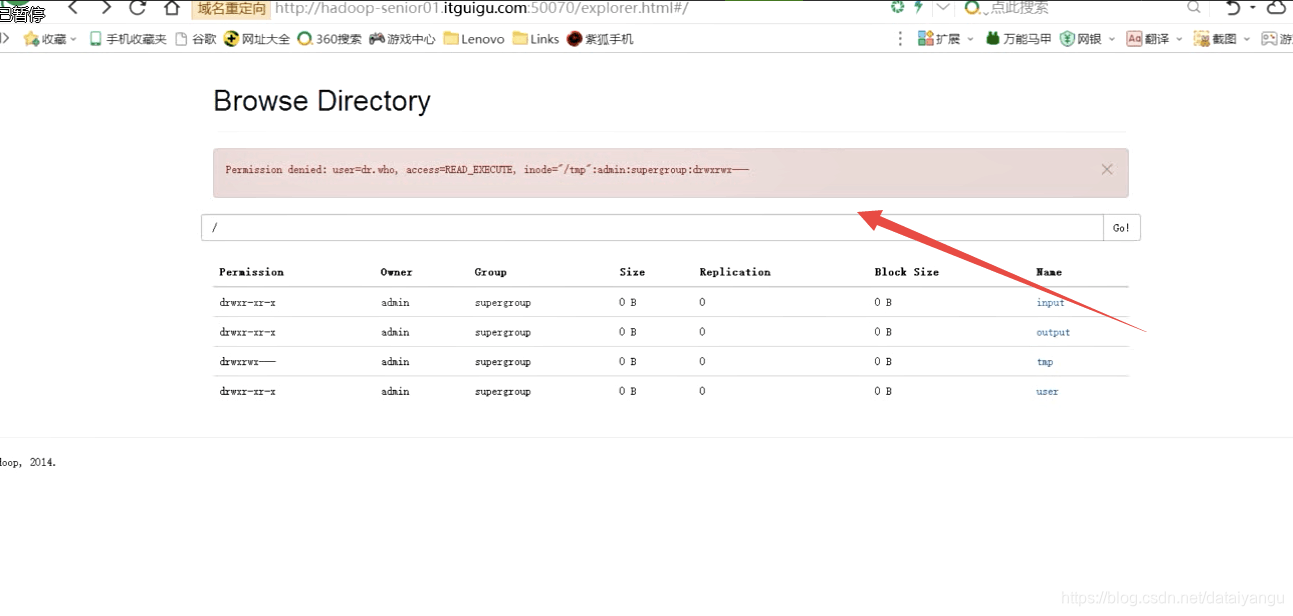
查看temp目录,报错admin没有权限。
** 修改HDFS系统中关于Hive的一些目录权限
$ /opt/modules/cdh/hadoop-2.5.0-cdh5.3.6/bin/hadoop fs -chmod 777 /tmp/
$ /opt/modules/cdh/hadoop-2.5.0-cdh5.3.6/bin/hadoop fs -chmod 777 /user/hive/warehouse
** 显示数据库名称以及字段名称

如上图,默认是不显示具体信息的。
hive-site.xml
<!-- 是否在当前客户端中显示查询出来的数据的字段名称 -->
<property>
<name>hive.cli.print.header</name>
<value>true</value>
<description>Whether to print the names of the columns in query output.</description>
</property>
<!-- 是否在当前客户端中显示当前所在数据库名称 -->
<property>
<name>hive.cli.print.current.db</name>
<value>true</value>
<description>Whether to include the current database in the Hive prompt.</description>
</property>
修改完之后重新启动hive,退出hive数据仓库==>exit >启动 hive>bin/hive
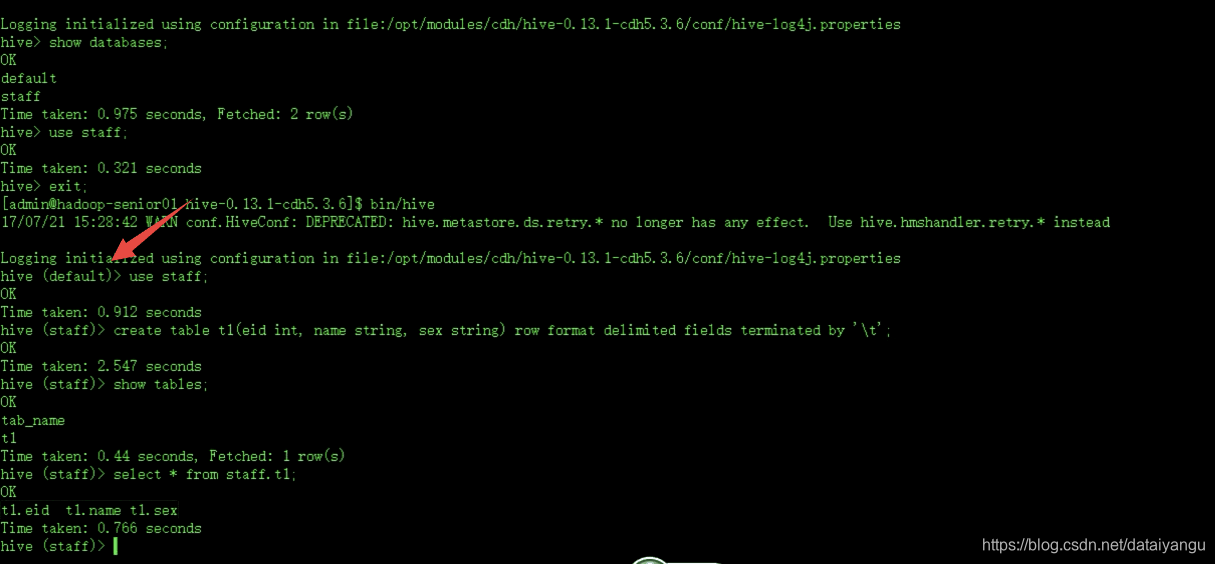
配置完之后有了数据库名称。
** 创建数据库
hive> create database staff;
** 创建表操作
hive> create table t1(eid int, name string, sex string) row format delimited fields terminated by ‘\t’;
表名t1 员工id(int),员工姓名(String),员工性别(String),row每行是通过什么来分割的,fields分割的属性是什么,by ‘\t’,通过\t分割,terminated中断的意思。
** select * from staff.t1

**查看表的详细信息
desc fomated t1

** 导入数据
到hive的根目录了下面
vi t1.txt
tab键分隔

*** 从本地导入
//注意local很关键,从本地导入和从HDFS导入的唯一区别就是这个关键字的有和没有
//文件路径可以是绝对路径可以使相对路径
load data local inpath '文件路径' into table;
*** 从HDFS系统导入

可以执行普通的查询select * from t1,也可以执行MapReduce select name from t1

通过MapReduce界面能够查看到刚才的语句
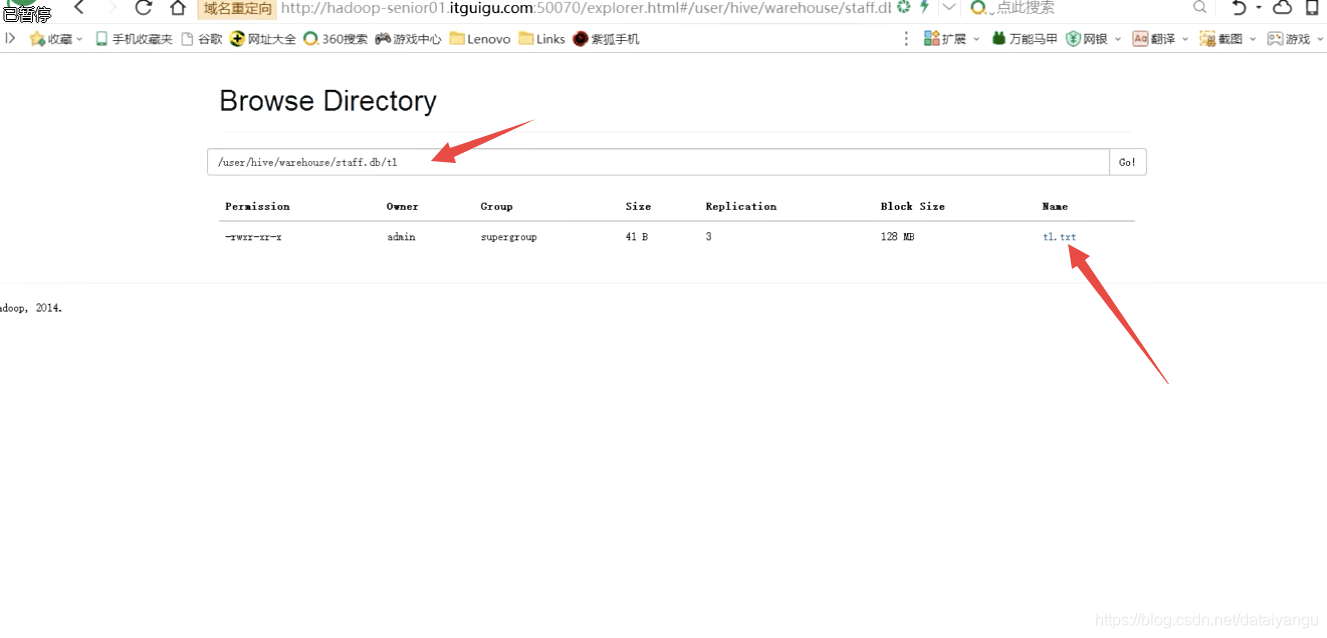
在HDFS查看t1这个表中,存放的还是t1.txt,原本是什么样,在HDFS中存的还是什么样,数据的格式内容都没有变,能够以访问表的形式体现,原因是因为metastore,hibe双射,所有的数据字段映射,原数据信息再HDFS中存放的目录,都在mysql中存放着。