在之前的博文中提到,hive的表数据是可以同步到impala中去的。一般impala是提供实时查询操作的,像比较耗时的入库操作我们可以使用hive,然后再将数据同步到impala中。另外,我们也可以在hive中创建一张表同时映射hbase中的表,实现数据同步。
下面,笔者依次进行介绍。
一、impala与hive的数据同步
首先,我们在hive命令行执行show databases;可以看到有以下几个数据库:
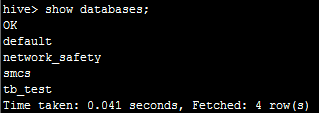
然后,我们在impala同样执行show databases;可以看到:
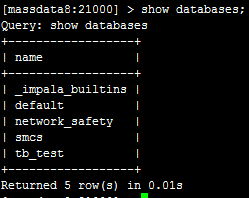
目前的数据库都是一样的。
下面,我们在hive里面执行create database qyk_test;创建一个数据库,如下:
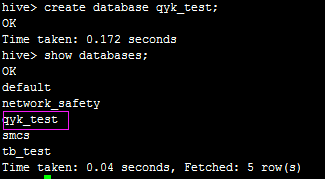
然后,我们使用qyk_test这个数据库创建一张表,执行create table user_info(id bigint, account string, name string, age int) row format delimited fields terminated by ‘\t’;如下:

此时,我们已经在hive这边创建好了,然后直接在impala这边执行show databases;可以看到:
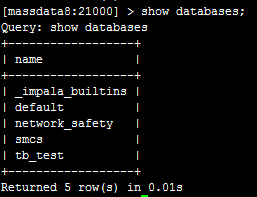
连qyk_test这个数据库都没有。
接下来,我们在impala执行INVALIDATE METADATA;然后再查询可以看到:
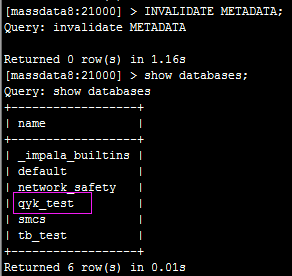
数据库和表都会同步过来。
好了,笔者来做个总结:
如果在hive里面做了新增、删除数据库、表或者数据等更新操作,需要执行在impala里面执行INVALIDATE METADATA;命令才能将hive的数据同步impala;
如果直接在impala里面新增、删除数据库、表或者数据,会自动同步到hive,无需执行任何命令。
二、hive与hbase的数据同步
首先,我们在hbase中创建一张表create ‘user_sysc’, {NAME => ‘info’},然后,我们在hive中执行
CREATE EXTERNAL TABLE user_sysc (key int, value string) ROW FORMAT SERDE 'org.apache.hadoop.hive.hbase.HBaseSerDe'
STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
WITH SERDEPROPERTIES ( 'serialization.format'='\t', 'hbase.columns.mapping'=':key,info:value', 'field.delim'='\t')
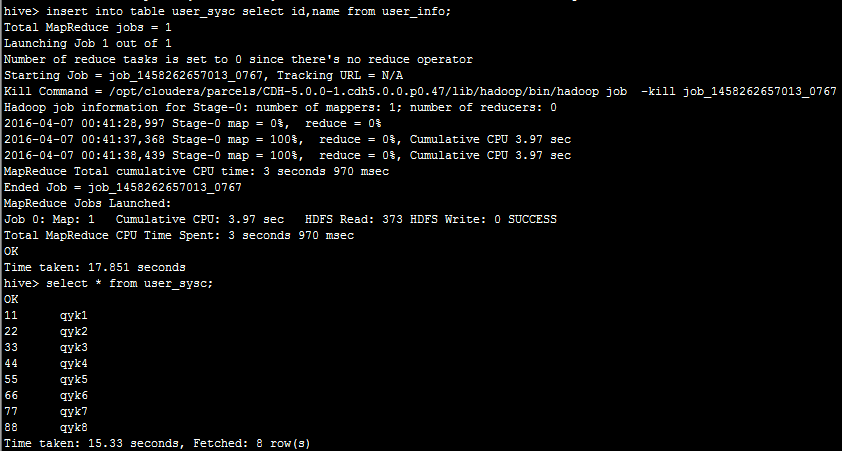
TBLPROPERTIES ('hbase.table.name'='user_sysc')创建一张外部表指向hbase中的表,然后,我们在hive执行insert into table user_sysc select id,name from user_info;入一步份数据到user_sysc可以看到:
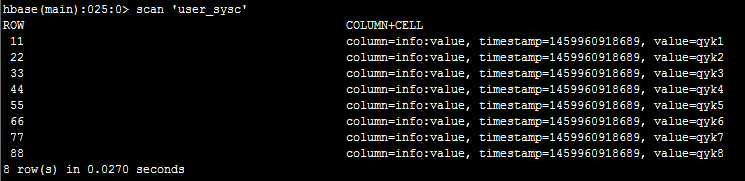
然后,我们在hbase里面执行scan ‘user_sysc’可以看到:
接下来,我们在hbase里面执行deleteall ‘user_sysc’, ‘11’删掉一条数据,如下:
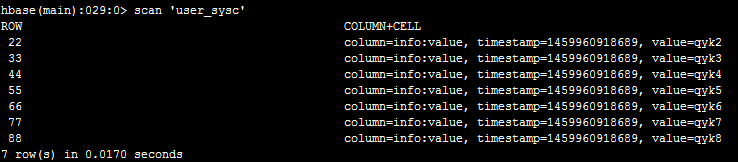
然后,我在hive里面查询看看,如下:
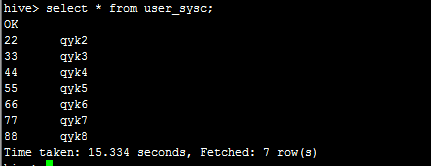
说明自动同步过来了。因此,只要创建hive表时,与hbase中的表做了映射,表名和字段名可以不一致,之后无论在hbase中新增删除数据还是在hive中,都会自动同步。
如果在hive里面是创建的外部表需要在hbase中先创建,内部表则会在hbase中自动创建指定的表名。
因为hive不支持删除等操作,而hbase里面比较方便,所以我们可以采用这种方式。