第1部分-创建模板
Detector的成员变量
class Detector
{
protected:
cv::Ptr<ColorGradient> modality;
int pyramid_levels;
std::vector<int> T_at_level;
typedef std::vector<Template> TemplatePyramid;
typedef std::map<std::string, std::vector<TemplatePyramid>> TemplatesMap;
TemplatesMap class_templates;
typedef std::vector<cv::Mat> LinearMemories;
// Indexed as [pyramid level][ColorGradient][quantized label]
typedef std::vector<std::vector<LinearMemories>> LinearMemoryPyramid;
};
cv::Ptr modality; 彩色图像的梯度
class ColorGradient
{
public:
ColorGradient();
ColorGradient(float weak_threshold, size_t num_features, float strong_threshold);
std::string name() const;
float weak_threshold; //弱阈值,待解释
size_t num_features;
float strong_threshold; //强阈值,待解释
void read(const cv::FileNode &fn);
void write(cv::FileStorage &fs) const;
cv::Ptr<ColorGradientPyramid> process(const cv::Mat src, const cv::Mat &mask = cv::Mat()) const
{
return cv::makePtr<ColorGradientPyramid>(src, mask, weak_threshold, num_features, strong_threshold);
}
};
ColorGradientPyramid 彩色梯度金字塔
class ColorGradientPyramid
{
public:
ColorGradientPyramid(const cv::Mat &src, const cv::Mat &mask,
float weak_threshold, size_t num_features,
float strong_threshold);
void quantize(cv::Mat &dst) const;
bool extractTemplate(Template &templ) const;
void pyrDown();
public:
void update();
/// Candidate feature with a score
struct Candidate
{
Candidate(int x, int y, int label, float score);
/// Sort candidates with high score to the front
bool operator<(const Candidate &rhs) const
{
return score > rhs.score;
}
Feature f;
float score;
};
cv::Mat src;
cv::Mat mask;
int pyramid_level;
cv::Mat angle;
cv::Mat magnitude;
float weak_threshold; //弱阈值,待解释
size_t num_features;
float strong_threshold; //强阈值,待解释
static bool selectScatteredFeatures(const
std::vector<Candidate> &candidates,
std::vector<Feature> &features,
size_t num_features, float distance);
};
Feature 梯度的特征变量
struct Feature
{
int x; //行方向像素值
int y; //列方向像素值
int label; //梯度的方向
void read(const cv::FileNode &fn);
void write(cv::FileStorage &fs) const;
Feature() : x(0), y(0), label(0) {}
Feature(int x, int y, int label);
};
TemplatePyramid 模板金字塔
Template 模板
struct Template
{
int width; //宽度
int height; //高度
int tl_x; //模板x方向偏移
int tl_y; //模板y方向偏移
int pyramid_level; //金字塔等级
std::vector<Feature> features; //特征集
void read(const cv::FileNode &fn);
void write(cv::FileStorage &fs) const;
};
Info 模板信息
class Info{
public:
float angle;
float scale;
Info(float angle_, float scale_){
angle = angle_;
scale = scale_;
}
};
addTemplate //为每一个角度和尺度的图像计算特征金字塔模板
int Detector::addTemplate(const Mat source, const std::string &class_id,
const Mat &object_mask, int num_features)
{
//这里class_templates初始化为空,std::map可以直接赋值如下
//这里的引用&是点睛之笔,如果不引用则函数结束后该变量被析构,内容为空
std::vector<TemplatePyramid> &template_pyramids = class_templates[class_id];
int template_id = static_cast<int>(template_pyramids.size());
//该角度和尺度的金字塔模板
TemplatePyramid tp;
//pyramid_levels表示金字塔的层数
tp.resize(pyramid_levels);
{
//提取每层金字塔图层的梯度,process其实就是实例化ColorGradientPyramid
//ColorGradientPyramid的参数weak_thresh, num_features, strong_threash通过modality来初始化,modality在Detector构造函数内初始化
Ptr<ColorGradientPyramid> qp = modality->process(source, object_mask);
//num_features默认为0,所以传入qp的是0
if(num_features > 0)
qp->num_features = num_features;
for (int l = 0; l < pyramid_levels; ++l)
{
/// @todo Could do mask subsampling here instead of in pyrDown()
if (l > 0)
{
//梯度图像下采样
qp->pyrDown();
}
//提取梯度图像的特征模板
bool success = qp->extractTemplate(tp[l]);
if (!success) return -1;
}
}
//裁剪模板,待分析
cropTemplates(tp);
/// @todo Can probably avoid a copy of tp here with swap
template_pyramids.push_back(tp);
return template_id;
}
ColorGradientPyramid 的初始化或者叫实例化
ColorGradientPyramid::ColorGradientPyramid(const Mat &_src, const Mat &_mask,
float _weak_threshold, size_t _num_features,
float _strong_threshold)
: src(_src),
mask(_mask),
pyramid_level(0),
weak_threshold(_weak_threshold),
num_features(_num_features),
strong_threshold(_strong_threshold)
{
update();
}
void ColorGradientPyramid::update()
{
//量化方向,每个像素有八个方向,量化为0-1-2-3-4-5-6-7
//magnitude此时为空,也可以称为梯度,一般为sobel_x与sobel_y的平方和
quantizedOrientations(src, magnitude, angle, weak_threshold);
}
quantizedOrientations 量化方向,我们以单通道为例
static void quantizedOrientations(const Mat &src, Mat &magnitude,
Mat &angle, float threshold)
{
// 高斯滤波
Mat smoothed;
// Compute horizontal and vertical image derivatives on all color channels separately
static const int KERNEL_SIZE = 7;
// For some reason cvSmooth/cv::GaussianBlur, cvSobel/cv::Sobel have different defaults for border handling...
GaussianBlur(src, smoothed, Size(KERNEL_SIZE, KERNEL_SIZE), 0, 0, BORDER_REPLICATE);
//我们以单通道为例,
if(src.channels() == 1){
//计算sobel,x和y方向
Mat sobel_dx, sobel_dy, sobel_ag;
Sobel(smoothed, sobel_dx, CV_32F, 1, 0, 3, 1.0, 0.0, BORDER_REPLICATE);
Sobel(smoothed, sobel_dy, CV_32F, 0, 1, 3, 1.0, 0.0, BORDER_REPLICATE);
//计算图像梯度
magnitude = sobel_dx.mul(sobel_dx) + sobel_dy.mul(sobel_dy);
//计算图像角度
phase(sobel_dx, sobel_dy, sobel_ag, true);
//梯度图像阈值处理
hysteresisGradient(magnitude, angle, sobel_ag, threshold * threshold);
}else{
magnitude.create(src.size(), CV_32F);
// Allocate temporary buffers
Size size = src.size();
Mat sobel_3dx; // per-channel horizontal derivative
Mat sobel_3dy; // per-channel vertical derivative
Mat sobel_dx(size, CV_32F); // maximum horizontal derivative
Mat sobel_dy(size, CV_32F); // maximum vertical derivative
Mat sobel_ag; // final gradient orientation (unquantized)
Sobel(smoothed, sobel_3dx, CV_16S, 1, 0, 3, 1.0, 0.0, BORDER_REPLICATE);
Sobel(smoothed, sobel_3dy, CV_16S, 0, 1, 3, 1.0, 0.0, BORDER_REPLICATE);
short *ptrx = (short *)sobel_3dx.data;
short *ptry = (short *)sobel_3dy.data;
float *ptr0x = (float *)sobel_dx.data;
float *ptr0y = (float *)sobel_dy.data;
float *ptrmg = (float *)magnitude.data;
const int length1 = static_cast<const int>(sobel_3dx.step1());
const int length2 = static_cast<const int>(sobel_3dy.step1());
const int length3 = static_cast<const int>(sobel_dx.step1());
const int length4 = static_cast<const int>(sobel_dy.step1());
const int length5 = static_cast<const int>(magnitude.step1());
const int length0 = sobel_3dy.cols * 3;
for (int r = 0; r < sobel_3dy.rows; ++r)
{
int ind = 0;
for (int i = 0; i < length0; i += 3)
{
// Use the gradient orientation of the channel whose magnitude is largest
int mag1 = ptrx[i + 0] * ptrx[i + 0] + ptry[i + 0] * ptry[i + 0];
int mag2 = ptrx[i + 1] * ptrx[i + 1] + ptry[i + 1] * ptry[i + 1];
int mag3 = ptrx[i + 2] * ptrx[i + 2] + ptry[i + 2] * ptry[i + 2];
if (mag1 >= mag2 && mag1 >= mag3)
{
ptr0x[ind] = ptrx[i];
ptr0y[ind] = ptry[i];
ptrmg[ind] = (float)mag1;
}
else if (mag2 >= mag1 && mag2 >= mag3)
{
ptr0x[ind] = ptrx[i + 1];
ptr0y[ind] = ptry[i + 1];
ptrmg[ind] = (float)mag2;
}
else
{
ptr0x[ind] = ptrx[i + 2];
ptr0y[ind] = ptry[i + 2];
ptrmg[ind] = (float)mag3;
}
++ind;
}
ptrx += length1;
ptry += length2;
ptr0x += length3;
ptr0y += length4;
ptrmg += length5;
}
// Calculate the final gradient orientations
phase(sobel_dx, sobel_dy, sobel_ag, true);
hysteresisGradient(magnitude, angle, sobel_ag, threshold * threshold);
}
}
hysteresisGradient //计算最终的梯度方向
void hysteresisGradient(Mat &magnitude, Mat &quantized_angle,
Mat &angle, float threshold)
{
// Quantize 360 degree range of orientations into 16 buckets
// Note that [0, 11.25), [348.75, 360) both get mapped in the end to label 0,
// for stability of horizontal and vertical features.
//把方向图像1~360归一化至1~16
Mat_<unsigned char> quantized_unfiltered;
//缩放因子--> 16.0 / 360.0
angle.convertTo(quantized_unfiltered, CV_8U, 16.0 / 360.0);
// Zero out top and bottom rows
/// @todo is this necessary, or even correct?
//把归一化的首行末行首列末列设置为0,不知道其用意
memset(quantized_unfiltered.ptr(), 0, quantized_unfiltered.cols);
memset(quantized_unfiltered.ptr(quantized_unfiltered.rows - 1), 0, quantized_unfiltered.cols);
// Zero out first and last columns
for (int r = 0; r < quantized_unfiltered.rows; ++r)
{
quantized_unfiltered(r, 0) = 0;
quantized_unfiltered(r, quantized_unfiltered.cols - 1) = 0;
}
// Mask 16 buckets into 8 quantized orientations
//同一直线的正反方向被认为是同方向,比如30和210是同方向 (210 = 180+30)
for (int r = 1; r < angle.rows - 1; ++r)
{
uchar *quant_r = quantized_unfiltered.ptr<uchar>(r);
for (int c = 1; c < angle.cols - 1; ++c)
{
quant_r[c] &= 7;
}
}
// Filter the raw quantized image. Only accept pixels where the magnitude is above some
// threshold, and there is local agreement on the quantization.
quantized_angle = Mat::zeros(angle.size(), CV_8U);
for (int r = 1; r < angle.rows - 1; ++r)
{
float *mag_r = magnitude.ptr<float>(r);
for (int c = 1; c < angle.cols - 1; ++c)
{
if (mag_r[c] > threshold)
{
// Compute histogram of quantized bins in 3x3 patch around pixel
//计算该像素点周围3x3的方向直方图累计,就是看哪个方向的趋势最大
int histogram[8] = {0, 0, 0, 0, 0, 0, 0, 0};
uchar *patch3x3_row = &quantized_unfiltered(r - 1, c - 1);
histogram[patch3x3_row[0]]++;
histogram[patch3x3_row[1]]++;
histogram[patch3x3_row[2]]++;
patch3x3_row += quantized_unfiltered.step1();
histogram[patch3x3_row[0]]++;
histogram[patch3x3_row[1]]++;
histogram[patch3x3_row[2]]++;
patch3x3_row += quantized_unfiltered.step1();
histogram[patch3x3_row[0]]++;
histogram[patch3x3_row[1]]++;
histogram[patch3x3_row[2]]++;
// Find bin with the most votes from the patch
//找到最大方向趋势的下标
int max_votes = 0;
int index = -1;
for (int i = 0; i < 8; ++i)
{
if (max_votes < histogram[i])
{
index = i;
max_votes = histogram[i];
}
}
// Only accept the quantization if majority of pixels in the patch agree
//如果该方向的趋势足够大(>5),则记录该像素的方向,这里进行了放大,把1向左移动几位,就是2的几次方
static const int NEIGHBOR_THRESHOLD = 5;
if (max_votes >= NEIGHBOR_THRESHOLD)
quantized_angle.at<uchar>(r, c) = uchar(1 << index);
}
}
}
}
好了,到这里模板的建立基本结束,有几个opencv函数这里记录一下:
pyrDown //金字塔降采样,然后重复执行quantizedOrientations,不再复述
{
// Extract a template at each pyramid level
Ptr<ColorGradientPyramid> qp = modality->process(source, object_mask);
if(num_features > 0)
qp->num_features = num_features;
for (int l = 0; l < pyramid_levels; ++l)
{
/// @todo Could do mask subsampling here instead of in pyrDown()
if (l > 0)
qp->pyrDown();
bool success = qp->extractTemplate(tp[l]);
if (!success)
return -1;
}
}
extractTemplate //提取模板特征,这里有个细节,找到同时为强度极值点和强方向点的像素位置作为特征点。
bool ColorGradientPyramid::extractTemplate(Template &templ) const
{
// Want features on the border to distinguish from background
Mat local_mask;
if (!mask.empty())
{
erode(mask, local_mask, Mat(), Point(-1, -1), 1, BORDER_REPLICATE);
// subtract(mask, local_mask, local_mask);
}
std::vector<Candidate> candidates;
bool no_mask = local_mask.empty();
//这里是强阈值的平方
float threshold_sq = strong_threshold * strong_threshold;
int nms_kernel_size = 5;
//@peak.ding 我觉得这个变量magnitude_valid没啥用
cv::Mat magnitude_valid = cv::Mat(magnitude.size(), CV_8UC1, cv::Scalar(255));
//循环遍历,找到同时为强度极值点和强方向点的像素位置
for (int r = 0+nms_kernel_size/2; r < magnitude.rows-nms_kernel_size/2; ++r)
{
const uchar *mask_r = no_mask ? NULL : local_mask.ptr<uchar>(r);
for (int c = 0+nms_kernel_size/2; c < magnitude.cols-nms_kernel_size/2; ++c)
{
if (no_mask || mask_r[c])
{
float score = 0;
if(magnitude_valid.at<uchar>(r, c)>0){
score = magnitude.at<float>(r, c);
bool is_max = true;
for(int r_offset = -nms_kernel_size/2; r_offset <= nms_kernel_size/2; r_offset++){
for(int c_offset = -nms_kernel_size/2; c_offset <= nms_kernel_size/2; c_offset++){
if(r_offset == 0 && c_offset == 0) continue;
if(score < magnitude.at<float>(r+r_offset, c+c_offset)){
score = 0;
is_max = false;
break;
}
}
}
//为了加速计算,因为找到极值点后周围不可能存在其他极值点了
if(is_max){
for(int r_offset = -nms_kernel_size/2; r_offset <= nms_kernel_size/2; r_offset++){
for(int c_offset = -nms_kernel_size/2; c_offset <= nms_kernel_size/2; c_offset++){
if(r_offset == 0 && c_offset == 0) continue;
magnitude_valid.at<uchar>(r+r_offset, c+c_offset) = 0;
}
}
}
}
if (score > threshold_sq && angle.at<uchar>(r, c) > 0)
{
candidates.push_back(Candidate(c, r, getLabel(angle.at<uchar>(r, c)), score));
}
}
}
}
// We require a certain number of features
if (candidates.size() < num_features)
return false;
// NOTE: Stable sort to agree with old code, which used std::list::sort()
std::stable_sort(candidates.begin(), candidates.end());
// Use heuristic based on surplus of candidates in narrow outline for initial distance threshold
float distance = static_cast<float>(candidates.size() / num_features + 1);
if (!selectScatteredFeatures(candidates, templ.features, num_features, distance))
{
return false;
}
// Size determined externally, needs to match templates for other modalities
templ.width = -1;
templ.height = -1;
templ.pyramid_level = pyramid_level;
return true;
}
selectScatteredFeatures //按一定距离稀疏化特征,使得特征被均匀地被采样
bool ColorGradientPyramid::selectScatteredFeatures(const std::vector<Candidate> &candidates,
std::vector<Feature> &features,
size_t num_features, float distance)
{
features.clear();
float distance_sq = distance * distance;
int i = 0;
while (features.size() < num_features)
{
Candidate c = candidates[i];
// Add if sufficient distance away from any previously chosen feature
bool keep = true;
//比较是否满足距离条件
for (int j = 0; (j < (int)features.size()) && keep; ++j)
{
Feature f = features[j];
keep = (c.f.x - f.x) * (c.f.x - f.x) + (c.f.y - f.y) * (c.f.y - f.y) >= distance_sq;
}
if (keep)
features.push_back(c.f);
//如果没有足够的特征点,则降低距离阈值,再次进行添加
if (++i == (int)candidates.size())
{
// Start back at beginning, and relax required distance
i = 0;
distance -= 1.0f;
distance_sq = distance * distance;
// if (distance < 3)
// {
// // we don't want two features too close
// break;
// }
}
}
if (features.size() == num_features)
{
return true;
}
else
{
std::cout << "this templ has no enough features" << std::endl;
return false;
}
}
cropTemplates(tp); //中心化模板(这里是以左上角的点来做基准,感觉是不对的),这里有问题,由于不同的旋转图像产生不同的模板,所以它的基准是不同的,所以这里中心化的参数有问题,需要修改。这里就不解释了
static Rect cropTemplates(std::vector<Template> &templates)
{
int min_x = std::numeric_limits<int>::max();
int min_y = std::numeric_limits<int>::max();
int max_x = std::numeric_limits<int>::min();
int max_y = std::numeric_limits<int>::min();
// First pass: find min/max feature x,y over all pyramid levels and modalities
for (int i = 0; i < (int)templates.size(); ++i)
{
Template &templ = templates[i];
for (int j = 0; j < (int)templ.features.size(); ++j)
{
int x = templ.features[j].x << templ.pyramid_level;
int y = templ.features[j].y << templ.pyramid_level;
min_x = std::min(min_x, x);
min_y = std::min(min_y, y);
max_x = std::max(max_x, x);
max_y = std::max(max_y, y);
}
}
/// @todo Why require even min_x, min_y?
if (min_x % 2 == 1)
--min_x;
if (min_y % 2 == 1)
--min_y;
// Second pass: set width/height and shift all feature positions
for (int i = 0; i < (int)templates.size(); ++i)
{
Template &templ = templates[i];
templ.width = (max_x - min_x) >> templ.pyramid_level;
templ.height = (max_y - min_y) >> templ.pyramid_level;
templ.tl_x = min_x >> templ.pyramid_level;
templ.tl_y = min_y >> templ.pyramid_level;
for (int j = 0; j < (int)templ.features.size(); ++j)
{
templ.features[j].x -= templ.tl_x;
templ.features[j].y -= templ.tl_y;
}
}
return Rect(min_x, min_y, max_x - min_x, max_y - min_y);
}
第2部分-使用模板
detector.match(img, 90, ids);
std::vector<Match> Detector::match(Mat source, float threshold,
const std::vector<std::string> &class_ids, const Mat mask) const
{
Timer timer;
std::vector<Match> matches;
// Initialize each ColorGradient with our sources
std::vector<Ptr<ColorGradientPyramid>> quantizers;
CV_Assert(mask.empty() || mask.size() == source.size());
quantizers.push_back(modality->process(source, mask));
// pyramid level -> ColorGradient -> quantization
LinearMemoryPyramid lm_pyramid(pyramid_levels,
std::vector<LinearMemories>(1, LinearMemories(8)));
// For each pyramid level, precompute linear memories for each ColorGradient
std::vector<Size> sizes;
for (int l = 0; l < pyramid_levels; ++l)
{
int T = T_at_level[l];
std::vector<LinearMemories> &lm_level = lm_pyramid[l];
if (l > 0)
{
for (int i = 0; i < (int)quantizers.size(); ++i)
quantizers[i]->pyrDown();
}
Mat quantized, spread_quantized;
std::vector<Mat> response_maps;
for (int i = 0; i < (int)quantizers.size(); ++i)
{
quantizers[i]->quantize(quantized);
spread(quantized, spread_quantized, T);
computeResponseMaps(spread_quantized, response_maps);
LinearMemories &memories = lm_level[i];
for (int j = 0; j < 8; ++j)
linearize(response_maps[j], memories[j], T);
}
sizes.push_back(quantized.size());
}
timer.out("construct response map");
if (class_ids.empty())
{
// Match all templates
TemplatesMap::const_iterator it = class_templates.begin(), itend = class_templates.end();
for (; it != itend; ++it)
matchClass(lm_pyramid, sizes, threshold, matches, it->first, it->second);
}
else
{
// Match only templates for the requested class IDs
for (int i = 0; i < (int)class_ids.size(); ++i)
{
TemplatesMap::const_iterator it = class_templates.find(class_ids[i]);
if (it != class_templates.end())
matchClass(lm_pyramid, sizes, threshold, matches, it->first, it->second);
}
}
// Sort matches by similarity, and prune any duplicates introduced by pyramid refinement
std::sort(matches.begin(), matches.end());
std::vector<Match>::iterator new_end = std::unique(matches.begin(), matches.end());
matches.erase(new_end, matches.end());
timer.out("templ match");
return matches;
}
一个变量,暂时不清楚作用
typedef std::vector<cv::Mat> LinearMemories;
// Indexed as [pyramid level][ColorGradient][quantized label]
typedef std::vector<std::vector<LinearMemories>> LinearMemoryPyramid;
spread(quantized, spread_quantized, T); 梯度扩散
static void spread(const Mat &src, Mat &dst, int T)
{
// Allocate and zero-initialize spread (OR'ed) image
dst = Mat::zeros(src.size(), CV_8U);
// Fill in spread gradient image (section 2.3)
for (int r = 0; r < T; ++r)
{
for (int c = 0; c < T; ++c)
{
orUnaligned8u(&src.at<unsigned char>(r, c), static_cast<const int>(src.step1()), dst.ptr(),
static_cast<const int>(dst.step1()), src.cols - c, src.rows - r);
}
}
}
orUnaligned8u 滑动窗口进行or运算,注意传入的数据指针,是形成滑窗并进行按位运算的关键,这里有个MIPP,真的百度查不到,这个是在多平台指令运算接口,可以跨平台编译。这里的跨度在我的电脑上是32位,所以输出src_v是一个有32个变量的vector。
具体MIPP的网址为 aff3ct /MIPP ,来张图来辅助理解
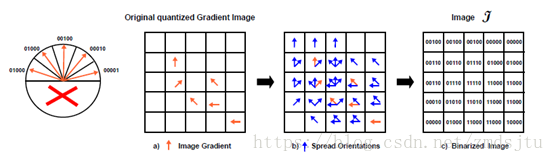
static void orUnaligned8u(const uchar *src, const int src_stride,
uchar *dst, const int dst_stride,
const int width, const int height)
{
for (int r = 0; r < height; ++r)
{
int c = 0;
// not aligned, which will happen because we move 1 bytes a time for spreading
while (reinterpret_cast<unsigned long long>(src + c) % 16 != 0) {
dst[c] |= src[c];
c++;
}
// avoid out of bound when can't divid
// note: can't use c<width !!!
for (; c <= width-mipp::N<uint8_t>(); c+=mipp::N<uint8_t>())
{
mipp::Reg<uint8_t> src_v((uint8_t*)src + c);
//if(src_v[0] !=0 ) std::cout << "src_v" << src_v << std::endl;
mipp::Reg<uint8_t> dst_v((uint8_t*)dst + c);
//if(src_v[0] !=0 ) std::cout << "dst_v" << dst_v << std::endl;
mipp::Reg<uint8_t> res_v = mipp::orb(src_v, dst_v);
//if(src_v[0] !=0 ) std::cout << "res_v" << res_v << std::endl;
res_v.store((uint8_t*)dst + c);
}
for(; c<width; c++)
dst[c] |= src[c];
// Advance to next row
src += src_stride;
dst += dst_stride;
}
}
computeResponseMaps(spread_quantized, response_maps);计算响应图像,就是提前计算每个方向与上一步的梯度扩散图像的匹配结果,目的是为了加速后面过程的模板匹配,这里在计算完响应图像后还要对他进行线性化,因为现代计算机的存储读取方式,这样做可以加快像素value的读取速度。这里计算响应图时用到了查找表,因为方向模式的匹配是固定数量的,也可以提高计算速度。来张图像说明一下,可能模糊最好直接看论文,没什么特别操作不要被吓到,就是算一个最大值
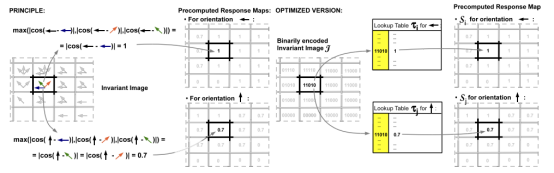
static void computeResponseMaps(const Mat &src, std::vector<Mat> &response_maps)
{
CV_Assert((src.rows * src.cols) % 16 == 0);
// Allocate response maps
response_maps.resize(8);
for (int i = 0; i < 8; ++i)
response_maps[i].create(src.size(), CV_8U);
Mat lsb4(src.size(), CV_8U);
Mat msb4(src.size(), CV_8U);
for (int r = 0; r < src.rows; ++r)
{
const uchar *src_r = src.ptr(r);
uchar *lsb4_r = lsb4.ptr(r);
uchar *msb4_r = msb4.ptr(r);
for (int c = 0; c < src.cols; ++c)
{
// Least significant 4 bits of spread image pixel
lsb4_r[c] = src_r[c] & 15;
// Most significant 4 bits, right-shifted to be in [0, 16)
msb4_r[c] = (src_r[c] & 240) >> 4;
}
}
{
uchar *lsb4_data = lsb4.ptr<uchar>();
uchar *msb4_data = msb4.ptr<uchar>();
bool no_max = true;
bool no_shuff = true;
#ifdef has_max_int8_t
no_max = false;
#endif
#ifdef has_shuff_int8_t
no_shuff = false;
#endif
// LUT is designed for 128 bits SIMD, so quite triky for others
// For each of the 8 quantized orientations...
for (int ori = 0; ori < 8; ++ori){
uchar *map_data = response_maps[ori].ptr<uchar>();
const uchar *lut_low = SIMILARITY_LUT + 32 * ori;
if(mipp::N<uint8_t>() == 1 || no_max || no_shuff){ // no SIMD
for (int i = 0; i < src.rows * src.cols; ++i)
map_data[i] = std::max(lut_low[lsb4_data[i]], lut_low[msb4_data[i] + 16]);
}
else if(mipp::N<uint8_t>() == 16){ // 128 SIMD, no add base
const uchar *lut_low = SIMILARITY_LUT + 32 * ori;
mipp::Reg<uint8_t> lut_low_v((uint8_t*)lut_low);
mipp::Reg<uint8_t> lut_high_v((uint8_t*)lut_low + 16);
for (int i = 0; i < src.rows * src.cols; i += mipp::N<uint8_t>()){
mipp::Reg<uint8_t> low_mask((uint8_t*)lsb4_data + i);
mipp::Reg<uint8_t> high_mask((uint8_t*)msb4_data + i);
mipp::Reg<uint8_t> low_res = mipp::shuff(lut_low_v, low_mask);
mipp::Reg<uint8_t> high_res = mipp::shuff(lut_high_v, high_mask);
mipp::Reg<uint8_t> result = mipp::max(low_res, high_res);
result.store((uint8_t*)map_data + i);
}
}
else if(mipp::N<uint8_t>() == 16 || mipp::N<uint8_t>() == 32
|| mipp::N<uint8_t>() == 64){ //128 256 512 SIMD
CV_Assert((src.rows * src.cols) % mipp::N<uint8_t>() == 0);
uint8_t lut_temp[mipp::N<uint8_t>()] = {0};
for(int slice=0; slice<mipp::N<uint8_t>()/16; slice++){
std::copy_n(lut_low, 16, lut_temp+slice*16);
}
mipp::Reg<uint8_t> lut_low_v(lut_temp);
uint8_t base_add_array[mipp::N<uint8_t>()] = {0};
for(uint8_t slice=0; slice<mipp::N<uint8_t>(); slice+=16){
std::copy_n(lut_low+16, 16, lut_temp+slice);
std::fill_n(base_add_array+slice, 16, slice);
}
mipp::Reg<uint8_t> base_add(base_add_array);
mipp::Reg<uint8_t> lut_high_v(lut_temp);
for (int i = 0; i < src.rows * src.cols; i += mipp::N<uint8_t>()){
mipp::Reg<uint8_t> mask_low_v((uint8_t*)lsb4_data+i);
mipp::Reg<uint8_t> mask_high_v((uint8_t*)msb4_data+i);
mask_low_v += base_add;
mask_high_v += base_add;
mipp::Reg<uint8_t> shuff_low_result = mipp::shuff(lut_low_v, mask_low_v);
mipp::Reg<uint8_t> shuff_high_result = mipp::shuff(lut_high_v, mask_high_v);
mipp::Reg<uint8_t> result = mipp::max(shuff_low_result, shuff_high_result);
result.store((uint8_t*)map_data + i);
}
}
else{
for (int i = 0; i < src.rows * src.cols; ++i)
map_data[i] = std::max(lut_low[lsb4_data[i]], lut_low[msb4_data[i] + 16]);
}
}
}
}
linearize(response_maps[j], memories[j], T); 响应图像线性化,来张图像形象化一下,不要被吓到不是什么神操作。
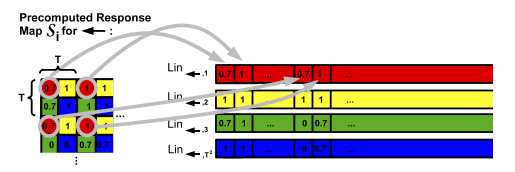
static void linearize(const Mat &response_map, Mat &linearized, int T)
{
CV_Assert(response_map.rows % T == 0);
CV_Assert(response_map.cols % T == 0);
// linearized has T^2 rows, where each row is a linear memory
int mem_width = response_map.cols / T;
int mem_height = response_map.rows / T;
linearized.create(T * T, mem_width * mem_height, CV_8U);
// Outer two for loops iterate over top-left T^2 starting pixels
int index = 0;
for (int r_start = 0; r_start < T; ++r_start)
{
for (int c_start = 0; c_start < T; ++c_start)
{
uchar *memory = linearized.ptr(index);
++index;
// Inner two loops copy every T-th pixel into the linear memory
for (int r = r_start; r < response_map.rows; r += T)
{
const uchar *response_data = response_map.ptr(r);
for (int c = c_start; c < response_map.cols; c += T)
*memory++ = response_data[c];
}
}
}
}
matchClass(lm_pyramid, sizes, threshold, matches, it->first, it->second); 模板匹配, 因为模板需要在输入图像上进行 滑动,所以产生了 similarity map。 每次滑动,模板和输入图像产生一个 相似度。 模板在 水平和垂直方向进行滑动, 所以 产生一个 二维的相似度矩阵。这个矩阵的宽 自然就是 输入图像的宽减去模板的宽, 也就是代码中的span_x。 高的情况类似。
代码当中用 template_positions 表示 模板的当前滑动位置。
计算similarity map最直观的方法是:对每个模板位置, 找出所有特征点在输入图像上对应的像素, 计算所有梯度方向的相似性,累加。 然后 处理下一个模板位置。
但代码中的做法是: 对每个特征点,计算出所有模板位置上 这个特征点 和 所有输入图像上对应点的 梯度方向相似性,保存到similarity map中。 然后 计算下一个特征点的相似性,累加到 similarity map中。
————————————————
版权声明:这一段为CSDN博主「haithink」的原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接及本声明。写的挺好!
原文链接:https://blog.csdn.net/haithink/article/details/88396670
void Detector::matchClass(const LinearMemoryPyramid &lm_pyramid,
const std::vector<Size> &sizes,
float threshold, std::vector<Match> &matches,
const std::string &class_id,
const std::vector<TemplatePyramid> &template_pyramids) const
{
#pragma omp declare reduction \
(omp_insert: std::vector<Match>: omp_out.insert(omp_out.end(), omp_in.begin(), omp_in.end()))
#pragma omp parallel for reduction(omp_insert:matches)
for (size_t template_id = 0; template_id < template_pyramids.size(); ++template_id)
{
const TemplatePyramid &tp = template_pyramids[template_id];
// First match over the whole image at the lowest pyramid level
/// @todo Factor this out into separate function
const std::vector<LinearMemories> &lowest_lm = lm_pyramid.back();
std::vector<Match> candidates;
{
// Compute similarity maps for each ColorGradient at lowest pyramid level
Mat similarities;
int lowest_start = static_cast<int>(tp.size() - 1);
int lowest_T = T_at_level.back();
int num_features = 0;
{
const Template &templ = tp[lowest_start];
num_features += static_cast<int>(templ.features.size());
if (templ.features.size() < 64){
similarity_64(lowest_lm[0], templ, similarities, sizes.back(), lowest_T);
similarities.convertTo(similarities, CV_16U);
}else if (templ.features.size() < 8192){
similarity(lowest_lm[0], templ, similarities, sizes.back(), lowest_T);
}else{
CV_Error(Error::StsBadArg, "feature size too large");
}
}
// Find initial matches
for (int r = 0; r < similarities.rows; ++r)
{
ushort *row = similarities.ptr<ushort>(r);
for (int c = 0; c < similarities.cols; ++c)
{
int raw_score = row[c];
float score = (raw_score * 100.f) / (4 * num_features);
if (score > threshold)
{
int offset = lowest_T / 2 + (lowest_T % 2 - 1);
int x = c * lowest_T + offset;
int y = r * lowest_T + offset;
candidates.push_back(Match(x, y, score, class_id, static_cast<int>(template_id)));
}
}
}
}
// Locally refine each match by marching up the pyramid
for (int l = pyramid_levels - 2; l >= 0; --l)
{
const std::vector<LinearMemories> &lms = lm_pyramid[l];
int T = T_at_level[l];
int start = static_cast<int>(l);
Size size = sizes[l];
int border = 8 * T;
int offset = T / 2 + (T % 2 - 1);
int max_x = size.width - tp[start].width - border;
int max_y = size.height - tp[start].height - border;
Mat similarities2;
for (int m = 0; m < (int)candidates.size(); ++m)
{
Match &match2 = candidates[m];
int x = match2.x * 2 + 1; /// @todo Support other pyramid distance
int y = match2.y * 2 + 1;
// Require 8 (reduced) row/cols to the up/left
x = std::max(x, border);
y = std::max(y, border);
// Require 8 (reduced) row/cols to the down/left, plus the template size
x = std::min(x, max_x);
y = std::min(y, max_y);
// Compute local similarity maps for each ColorGradient
int numFeatures = 0;
{
const Template &templ = tp[start];
numFeatures += static_cast<int>(templ.features.size());
if (templ.features.size() < 64){
similarityLocal_64(lms[0], templ, similarities2, size, T, Point(x, y));
similarities2.convertTo(similarities2, CV_16U);
}else if (templ.features.size() < 8192){
similarityLocal(lms[0], templ, similarities2, size, T, Point(x, y));
}else{
CV_Error(Error::StsBadArg, "feature size too large");
}
}
// Find best local adjustment
float best_score = 0;
int best_r = -1, best_c = -1;
for (int r = 0; r < similarities2.rows; ++r)
{
ushort *row = similarities2.ptr<ushort>(r);
for (int c = 0; c < similarities2.cols; ++c)
{
int score_int = row[c];
float score = (score_int * 100.f) / (4 * numFeatures);
if (score > best_score)
{
best_score = score;
best_r = r;
best_c = c;
}
}
}
// Update current match
match2.similarity = best_score;
match2.x = (x / T - 8 + best_c) * T + offset;
match2.y = (y / T - 8 + best_r) * T + offset;
}
// Filter out any matches that drop below the similarity threshold
std::vector<Match>::iterator new_end = std::remove_if(candidates.begin(), candidates.end(),
MatchPredicate(threshold));
candidates.erase(new_end, candidates.end());
}
matches.insert(matches.end(), candidates.begin(), candidates.end());
}
}
similarity(lowest_lm[0], templ, similarities, sizes.back(), lowest_T); 计算每个模板的相似矩阵,就是求可能的匹配位置。
static void similarity(const std::vector<Mat> &linear_memories, const Template &templ,
Mat &dst, Size size, int T)
{
// we only have one modality, so 8192*2, due to mipp, back to 8192
CV_Assert(templ.features.size() < 8192);
// Decimate input image size by factor of T
int W = size.width / T;
int H = size.height / T;
// Feature dimensions, decimated by factor T and rounded up
int wf = (templ.width - 1) / T + 1;
int hf = (templ.height - 1) / T + 1;
// Span is the range over which we can shift the template around the input image
int span_x = W - wf;
int span_y = H - hf;
int template_positions = span_y * W + span_x + 1; // why add 1?
dst = Mat::zeros(H, W, CV_16U);
short *dst_ptr = dst.ptr<short>();
mipp::Reg<uint8_t> zero_v(uint8_t(0));
for (int i = 0; i < (int)templ.features.size(); ++i)
{
Feature f = templ.features[i];
if (f.x < 0 || f.x >= size.width || f.y < 0 || f.y >= size.height)
continue;
const uchar *lm_ptr = accessLinearMemory(linear_memories, f, T, W);
int j = 0;
// *2 to avoid int8 read out of range
for(; j <= template_positions -mipp::N<int16_t>()*2; j+=mipp::N<int16_t>()){
mipp::Reg<uint8_t> src8_v((uint8_t*)lm_ptr + j);
// uchar to short, once for N bytes
mipp::Reg<int16_t> src16_v(mipp::interleavelo(src8_v, zero_v).r);
mipp::Reg<int16_t> dst_v((int16_t*)dst_ptr + j);
mipp::Reg<int16_t> res_v = src16_v + dst_v;
res_v.store((int16_t*)dst_ptr + j);
}
for(; j<template_positions; j++)
dst_ptr[j] += short(lm_ptr[j]);
}
}
accessLinearMemory(linear_memories, f, T, W); 在之前计算的线性化响应图像中查找匹配值。 计算相似性, similarity中, 核心调用是 accessLinearMemory,
这里面第一行代码
const Mat &memory_grid = linear_memories[f.label];
很关键,这是根据模板中特征点 来 定位 response map 相应的数据
定位到以后,然后 就是 SIMD 指令 来 累加数据了!
————————————————
版权声明:这段为CSDN博主「haithink」的原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/haithink/article/details/88396670
static const unsigned char *accessLinearMemory(const std::vector<Mat> &linear_memories,
const Feature &f, int T, int W)
{
// Retrieve the TxT grid of linear memories associated with the feature label
const Mat &memory_grid = linear_memories[f.label];
CV_DbgAssert(memory_grid.rows == T * T);
CV_DbgAssert(f.x >= 0);
CV_DbgAssert(f.y >= 0);
// The LM we want is at (x%T, y%T) in the TxT grid (stored as the rows of memory_grid)
int grid_x = f.x % T;
int grid_y = f.y % T;
int grid_index = grid_y * T + grid_x;
CV_DbgAssert(grid_index >= 0);
CV_DbgAssert(grid_index < memory_grid.rows);
const unsigned char *memory = memory_grid.ptr(grid_index);
// Within the LM, the feature is at (x/T, y/T). W is the "width" of the LM, the
// input image width decimated by T.
int lm_x = f.x / T;
int lm_y = f.y / T;
int lm_index = lm_y * W + lm_x;
CV_DbgAssert(lm_index >= 0);
CV_DbgAssert(lm_index < memory_grid.cols);
return memory + lm_index;
}
至此,创建模板与模板匹配部分均已完成,匹配部分还有一些细节,待后来个更新,文章写的有些杂乱,待整理更新。
