文章目录
项目简介
知识图谱、信息抽取以及规则系统(本节内容)
基于机器学习的信息抽取系统
基于深度学习的信息抽取系统
信息抽取最新研究与展望
信息抽取实战经验与面试准备
内容简介
任务简介:了解信息抽取的基础知识
详细说明:
本节引入知识图谱的概念,介绍信息抽取进行知识图谱的基础知识。通过一个具体的比赛数据,介绍知识图谱构建与信息抽取问题的定义
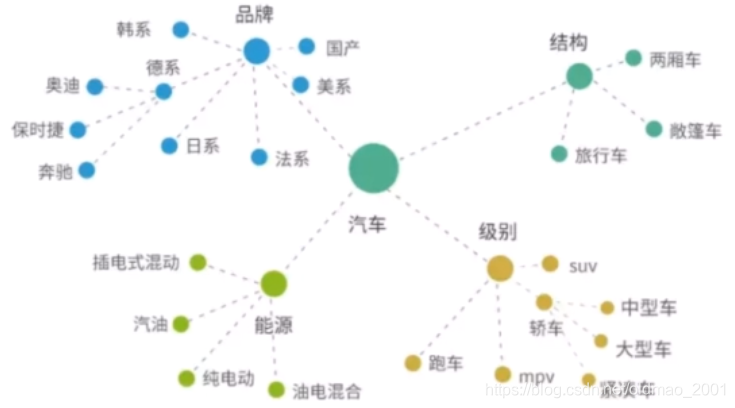
知识图谱的概念、应用与构建
什么是知识图谱?
知识图谱里通常用“实体(Entity)“来表达图里的节点、用“关系(Relation)"来表达图里的“边”。
三元组一>(奥迪,德系,品牌)
知识图谱的应用
多用于搜索引擎,问答系统等。
htups:/magi.com/aggrch2g=迪丽热巴有多高
用户输入关键词,即可获取从互联网文本中自主学习到的结构化知识和网页搜索结果,每个结构化结果后面都会附上来源链接和其可信度评分。
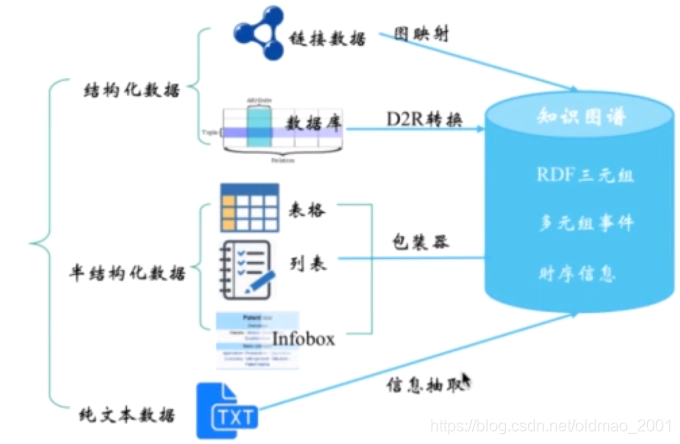
什么是信息抽取
对于结构化与半结构化数据需要复杂表数据的处理与定义抽取的包装器等方式实现。
对非结构化的纯文本数据需要借助自然语言处理等技术来自动地提取出结构化信息。这个过程一般称为信息抽取。
信息抽取的主要任务
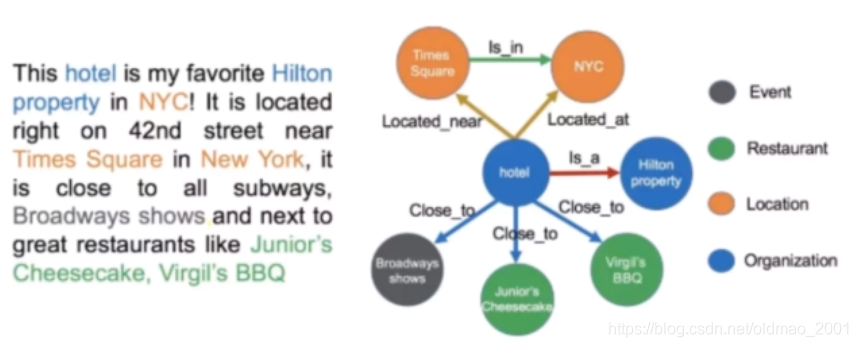
命名实体识别(Name Entity Recognition)
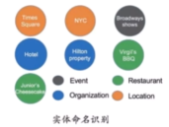
关系抽取(Relation Extraction)

实体统一(Entity Resolution)

指代消解(Coreference Resolution)

自然语言理解的本质
自然语言理解本质是结构预测。自然语言理解的众多任务,包括并不限于中文分词、词性标注、命名实体识别、共指消解、句法分析、语义角色标注等,都是在对文本序列背后特定语义结构进行预测。
信息抽取构建知识图谱实例
构建知识图谱的步骤
搭建一个知识图谱系统的重点并不在于算法和开发,其实最重要的核心在于对业务的理解以及对知识图谱本身的设计
1.定义具体的业务问题
2.数据的收集&预处理
2.1.我们已经有哪些数据?
2.2.虽然现在没有,但有可能拿到哪些数据?
2.3.哪部分数据可以用来构建知识图谱?
3.知识图谱的设计
3.1.需要哪些实体、关系和属性?
3.2.哪些属性可以做为实体,哪些实体可以作为属性?
3.3.哪些信息不需要放在知识图谱中?
4.把数据存入知识图谱
5.上层应用的开发,以及系统的评估。
构建糖尿病知识图谱Construction of diabetes knowledge graph
通过糖尿病相关的教科书、研究论文来做糖尿病文献挖掘并构建糖尿病知识图谱。
一、基于糖尿病临床指南和研究论文的实体标注构建
二、基于糖尿病临床指南和研究论文的实体间关系构建
糖尿病实体体系
疾病相关:
1、疾病名称(Disease)
2、病因(Reason)
3、临床表现(Symptom)
4.、检查方法(Test)
5、检查指标值(Test_Value)
治疗相关:
6、药品名称(Drug)
7、用药频率(Frequency)
8、用药剂量(Amount)
9、用药方法(Method)
10、非药治疗(Treatment)
11、手术(Operation)
12、不良反应(SideEff)
常规实体:
13、部位(Anatomy)
14、程度(level)
15、持续时间(Duration)
糖尿病关系体系
疾病相关:
1、检查方法->疾病(Test_Disease)
2、临床表现->疾病(Symptom-Disease)
3、非药治疗->疾病(Treatment_Disease)
4、药品名称->疾病(Drug-Disease)
5、部位->疾病(Anatomy_Disease)
药品相关:
6、用药频率->药品名称(Frequency_Drug)
7、持续时间一>药品名称(Duration_Drug)
8、用药剂量->药品名称(Amount_Drug)
9、用药方法->药品名称(Method_Drug)
10、不良反应->药品名称(SideEff-Drug)
标注工具:brat
官网
这里老师省略过程,直接拿到就是标注好的数据。
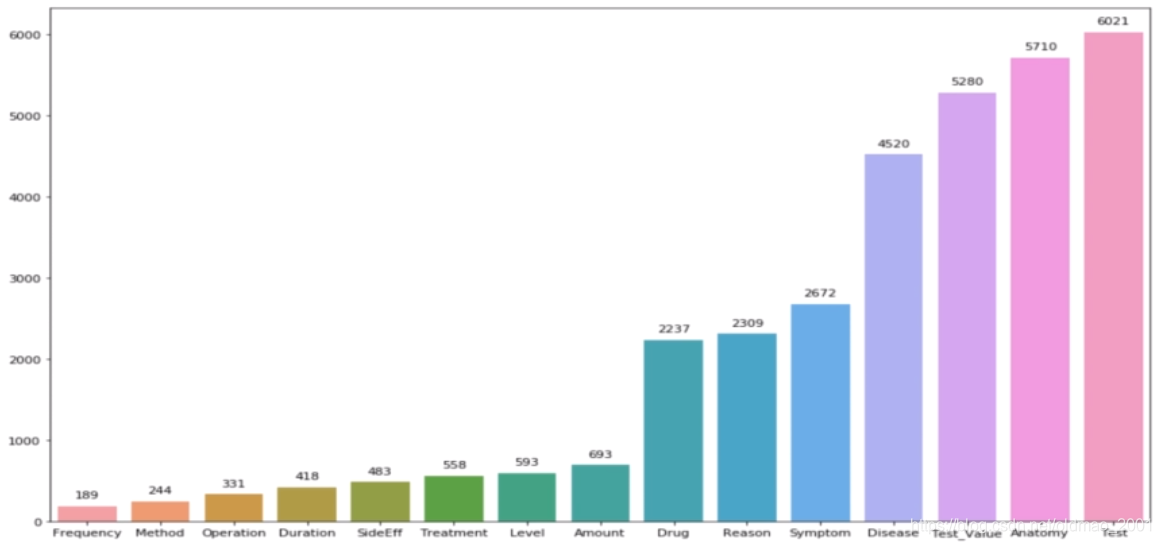
实体分布分析
检查标注文件中实体的数量分布,可见实体分布并不均匀.且差别很大(189一6021)。最少的是frequency,最多的是test
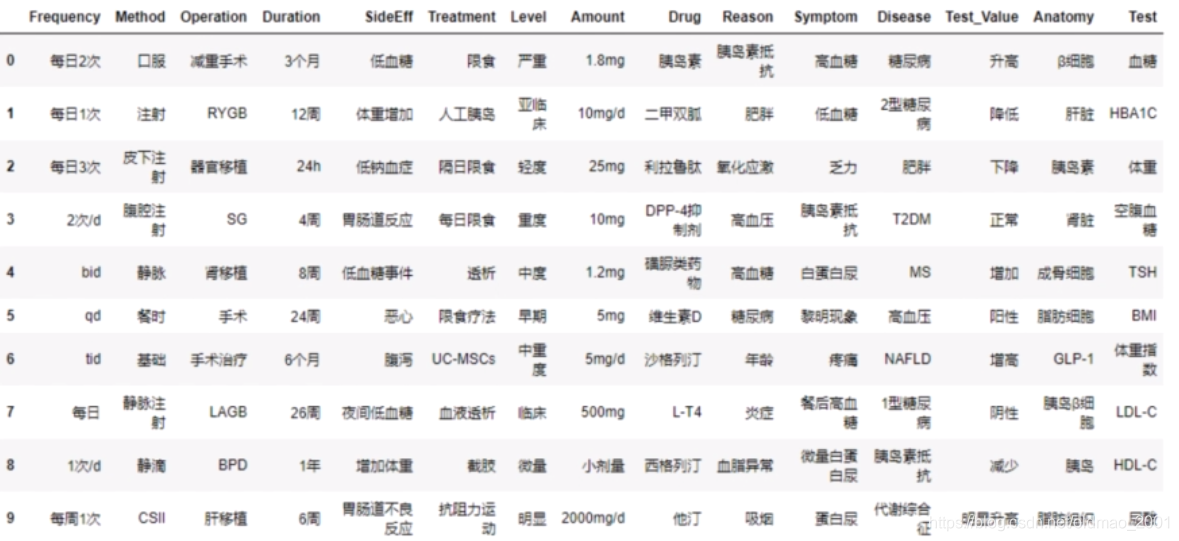
实体内容探索
实体数量top10标签内容探索:
1.总数较少的实体分布,有一定规律:
2.实体之间有重叠:
每日2次和2次/d其实是一样的。
低血糖既可以出现在症状,又可以出现在疾病名称中。
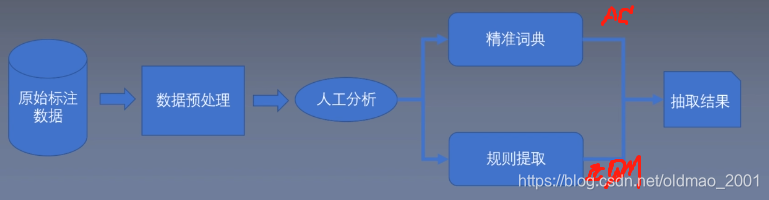
正则表达式与AC自动机
AC自动机
用来词体匹配
字符串搜索算法,用于在输入的一串字符串中匹配有限组“字典”中的子串。它与普通字符串匹配的不同点在于同时与所有字典串进行匹配。算法均摊情况下具有近似于线性的时间复杂度,约为字符串的长度加所有匹配的数量。
用到了两个东西,一个是KMP的思想(注意是思想不是算法),一个是Trie树。
Trie树在这里是用来放字典中的单词的,这样可以使得我们一次匹配多个单词,然后用KMP的算法来使得匹配失败后不进行根结点的回溯。
调用开源的pyahocorasick进行匹配
正则表达式
用来模式匹配
原理:NFA自动机(Non deterministic Finite Automaton 不确定型有穷自动机)。NFA是以正则表达式为基准去匹配的,发现不匹配了。此时就会发生回溯。
这个玩意之前在JS中进行网页信息校验的时候用的比较多,例如:注册邮箱是否填写规范。身份证是否合法。
具体教材点这里点这里
基于规则的信息抽取