项目简介
知识图谱、信息抽取以及规则系统
基于机器学习的信息抽取系统
基于深度学习的信息抽取系统(本节内容)
信息抽取最新研究与展望
信息抽取实战经验与面试准备
任务简介:
学习深度学习在NLP领域的应用
详细说明:
本节开始学习深度学习解决NLP问题的方法与应用,包括文本表示、文本特征抽取,常见NLP任务模型结构等。
深度学习解决NLP任务
传统方法解决NER问题
1.基于规则的专家系统召回低,规则维护复杂,泛化能力差
2.基于特征的监督学习需要大量特征工程,泛化能力一般
基于DL的NER模型成为主流,并取得了SOTA

深度学习解决NLP任务
深度学习的关键优势在于其强大的表示学习能力。通过向量表示和神经网络学习复杂的组合语义。
深度学习可以通过对原始数据进行训练。自动发现分类或检测所需的语义表示。
NLP中监督任务的基本套路:
文本数据搜集和预处理
将文本进行编码和表征
设计模型解决具体任务

文本表示
文本表示是深度学习进行NLP任务的第一步,将自然语言转化为深度学习能处理的数据。
词向量
词向量,将自然语言进行数学化。
1.One-hot:维度灾难,不能刻画词与词之间的相似性,稀疏性,不能表达一词多义。
2.Distributed:将词映射成固定长度的短向量,构造词向量空间,通过距离刻画词之间的相似性。
语言模型
语言模型就是用来计算一个句子的概率的模型,也就是判断一句话是否是人话的概率。
中国是世界上糖尿病患者最多的国家。
中国是世界上患者最多的国家糖尿病。
中国是世界上最多的国家糖尿病患者。

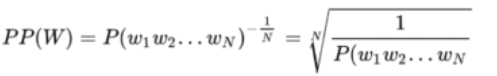
N元语言模型N-gram Language model
N元模型就是假设当前词的出现概率只与它前面的N-1个词有关(马尔可夫假设)。而这些概率参数都是可以通过大规模语料库来计算。
神经语言模型NNLM
没记错应该是bengio在03年提出的

之前的论文带读也学过:https://blog.csdn.net/oldmao_2001/article/details/100575432
然后几个常见的词向量学习方法这里就省略了
分别是:Word2vec,Glove,Fasttext
文本特征抽取器
文本特征抽取利用深度学习自动发现特征的优势,学习到对最终任务有用的特征。
nlp任务特征:
1.序列输入.前后依赖
2.输入不定长
3.位置敏感
这节课内容之前学过,不写太详细,直接过一遍好了。。。
卷积神经网络
特点:卷积一>池化一>全连接
优点:
局部感知
参数共享
并行化.速度快
CNN来做NLP,相当于N-gram的加强版
但是缺点是:无法捕捉长距离特征
当然也弄了一些trick来进行改善:
膨胀Dilate
应该就是空洞卷积
Dilated CNN为传统CNN的filter增加了一个dilation width.作用在输入矩阵的时候,会skip所有dilation width中间的输入数据:而filter本身的大小保持不变,这样filter获取到了更广阔的输入矩阵上的数据,看上去就像是“膨胀”了一般。

可以看到空洞卷积的感受野比普通的卷积核要大很多。也就一定量的改善了普通CNN不能捕捉长距离特征。
加深
门控结构gated linear units(GLM)
门控+残差
主要解决网络过深,梯度消失的问题。
循环神经网络
长期依赖问题:RNN可以通过中间状态保存上下文信息,作为输入影响下一时序的预测。
编码:可以将可变输入编码成固定长度的向量。和CNN相比,能够保留全局最优特征。
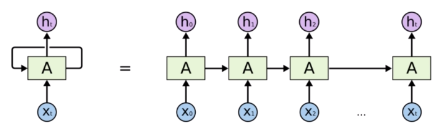
缺点是并行能力差。(相对于CNN)
LSTM Long Short Term Memory
长短期记忆是一种特殊的RNN,主要是为了解决长序列训练过程中的梯度消失和梯度爆炸问题。
简单来说,就是相比普通的RNN,LSTM能够在更长的序列中有更好的表现。
BiLSTM
前向与后向的信息相结合

Transformer
https://blog.csdn.net/oldmao_2001/article/details/100856786
注意力机制
人类利用有限的注意力资源从大量信息中快速筛选出高价值信息。
深度学习中的注意力机制核心目标也是从众多信息中选择出对当前任务目标更关键的信息。
Encoder-Decoder框架
Encoder:对输入句子Source进行编码,将输入句子通过非线性变换转化为中间语义表示C。
Decoder:根据句子Source的中间语义表示C和之前已经生成的历史信息来生成下一时刻要生成的信息。
这个有点问题,就是无论多长都会压缩为一个向量C,会丢失一些信息。
Attention based Encoder-Decoder
注意力分配概率分布值的通用计算
Attention模型看作是输出Target句子中某个单词和输入Source句子每个单词的对齐模型
自注意力机制(略)
自注意力为什么有效
CNN:基于N-gram的局部特征;
RNN:梯度消失,只能解决短距离依赖;
FCN(全连接网络):无法处理变长的输入序列;
Self-Attention:利用注意力机制来“动态”地捕捉输入之间的联系,从而处理变长的信息序列。
Transformer Block
1.多头自注意力机制;
2.位置编码;
3.残差连接;
小结
语义特征提取能力
Transformer>>CNN=RNN
长距离特征捕获能力
Transformer>RNN>>CNN
任务综合特征抽取能力
Transformer>CNN=RNN
并行计算能力及运行效率
Transformer=CNN>>RNN
常见NLP任务模型结构
常见的NLP任务有数十种.但对NLP任务进行抽象的话,会发现绝大多数NLP任务可以归结为几大类任务。两个看似差异很大的任务,在解决任务的模型角度,可能完全是一样的。
NLP四大任务
序列标注
分类任务
句子关系判断
生成式任务
分类任务
分类任务,包括垃圾内容识别、情感计算、舆情监控、评论挖掘等。它的特点是不管文本有多长,总体给出一个分类类别即可。
序列标注
序列标注,包括中文分词,词性标注,命名实体识别,语义角色标注等,它的特点是句子中每个单词要求模型根据上下文都要给出一个分类类别。
句子关系判断
句子关系判断,包括问答、语义改写、自然语言推理、摘要抽取等任务。它的特点是给定两个文本(可以是文本和句子,可以是句子和句子,可以是文本和文本),模型判断出两个文本是否具备某种语义关系;
生成式任务
生成式任务,包括机器翻译、文本摘要、写诗造句、看图说话等。它的特点是输入文本或图像等内容后,能自主生成另外一段文字。
