知识图谱构建中的抽取方法看法
随便写的、看看就好。
待续
现有开源的知识图谱一般使用三元组存储,也包含概念层的本体定义。小型的知识图谱可以从属性图这个角度来看待,具体应该包括点、边、点的属性,其中点和边都存在不同的类型。总体来说新建一个知识图谱需要定义。
- 实体的类型集合
- 关系的类型集合及其限制(起点和终点分别是何种类型的点)
- 实体-属性名-属性值 三元组
- 实体-关系-实体 三元组
- 属性值集合(定义规则)
在构建知识图谱中 1.实体的类型集合 和 2.关系的类型集合及其限制 一般利用固定领域的知识和知识图谱使用需求进行预先定义,其也相当于开源知识图谱中本体概念层。知识图谱的构建过程主要关心 3. 实体-属性名-属性值 三元组 和 4. 实体-关系-实体 三元组。一般来说,将任务3当作任务4来处理。但是其也存在明显不同,具体不做比较。
这里也就可以将知识库构建中的抽取任务分为:
- 实体抽取
- 属性抽取
- 关系抽取
- 实体属性抽取
- 实体与关系联合抽取
一、实体抽取
实体抽取也叫命名实体识别。从方法上来说存在着:
- 利用外部词典和外部知识库进行识别
- 基于规则的方法进行识别
- 基于统计学习的方法。
现在开放域命名实体识别已经成为了一项基础任务了,大量工具都能够将命名实体识别做到较好的效果。
但是在特定领域下实体抽取的效果并不理想,可以标注足量数据,使用BERT、LSTM+CRF模型利用序列标注模型抽取实体。不过构建数据集的成本一般比较高,一般还可以结合外部词典或者知识库、定义规则快速抽取实体。
二、属性值抽取
属性值相比实体名来说,其定义更加宽泛,其类型相比实体来说肯定更多。感觉上,可以完全把属性当作实体处理,利用序列标注来完成属性抽取、也可以基于规则来识别大量属性(毕竟存在着长度、宽度这样的属性)。
三、关系三元组抽取
关系抽取的方法按照机器学习中的训练模式大体上可以分为基于规则的方法、有监督、半监督、无监督、远程监督、开放域关系抽取。
基于规则的关系抽取
无监督的关系抽取不需要训练数据,主要依靠领域专家自定义一定的规则(正则表达式)来抽取出实体之间的关系。一个简单的例子就是“特朗普的国籍是美国”,我们只要定义。一个人名实体后接“的国籍是”后面接一个国家实体。那么就可以抽取出 特朗普–国籍–美国。当然实际的做法会比这样复杂一些,毕竟中间的字段是不能穷举的。但是基于规则的方法就是这样去自定义一些规则来实现抽取的任务。
当然,在抽取的过程中实质上我们得到的数据不仅仅是“特朗普的国籍是美国”这一个字符串,在刚才的例子中我们就利用了 “特朗普”是人,“美国”是一个国家的信息,我们还可以挖掘该句子中的其他信息,最常见的就是利用语法信息和语义信息,这些都可以利用到关系抽取中来提高我们定义规则的完备程度。
有监督关系抽取
有监督的关系抽取其实也就是关系分类。关系分类主要是利用统计机器学习的方法来实现分类,输入为一个句子“特朗普的国籍是美国”和两个实体“特朗普”“美国”,以及预先定义的关系类型集合,输出为类型集合中的一个关系(此处为“国籍”)。细分下去也包含三种、分别是基于特征向量,基于核函数和基于深度学习的方法,由于该问题的输入输出很明确,现在已经有大量的神经网络模型来处理这个明确的分类问题,其中效果最好的应该是Linlin Wang的多层注意力CNN论文地址。同样解决这个问题CNN相比RNN感觉效果更好一些,不过从本能的设想来看,RNN更能解决这类序列数据问题。当然也可以利用预训练模型来改进模型,我简单测试在CNN原始模型上只能达到82,而加入bert后达到86.9。github链接.而阿里使用bert后拼接两实体和句子向量进行分类,F1值达到89.25。论文地址。
这些论文所处理的数据集都是SEM_EVAL 2010 task 8 任务集,相对来说数据集很小,曾经看到过说在这个数据集上的任务都是在不断的过拟合,在实际任务场景下效果是没有保障的。
基于神经网络的做法主要好处就是端对端,不需要预抽取特征或者说语法分析。
实际应用场景下的关系抽取任务,不论是小型知识图谱还是大型知识图谱,都难以去预定义完全的候选关系。
半监督关系抽取
半监督关系抽取主要利用自举的思路:其首先人工构造少了关系实例作为种子集合,然后利用模式学习或者训练模型的方法,通过不停迭代来扩展关系集合,最终获得足够规模的关系。
无监督关系抽取
无监督关系抽取应该也是包含基于规则的方法的,这里主要指利用聚类算法来实现关系类型的确定,一般应用场景是未知关系类型情况下,需要利用语料来确定关系类型。其一般需要大规模语料支持,通过语料冗余性来得到可能关系模式集合,最后确定该关系名称。
远程监督关系抽取
远程监督的关系抽取主要是利用已有的知识库,和文档集合。其假设一句话里面包含两个实体,并且在知识库中两实体存在关系,那么这句话就包含了两实体存在关系的信息。有一个中文人物关系数据集就是使用百科中的关系人物和新闻语句中同时出现来构建的。
该假设是一个强假设,包含大量错误数据,这样必然会影响到后面机器学习算法的效果。由此又有大量研究关注于降低远程监督导致的误差这一问题。
开放域关系抽取
开放域的关系抽取其实主要是面向任务去区分的,其使用的技术还是之前的技术,只是其解决的问题是面向开放域抽取中出现的新问题。
四、属性三元组抽取
实体-属性名-属性值抽取,可以直接转换为实体-关系-实体这样的三元组去处理,另外一个直接可以使用规则来抽取属性值和实体-属性名-属性值。现在有大量工作来做实体和关系的联合抽取,属性值和实体-属性名-属性值更适合联合去做,毕竟单独抽取属性值在通用型上不合适。
五、实体、关系联合抽取
实体关系联合抽取就是一个模型同时抽取实体和关系,而不是按照先抽取实体再抽取关系的pipeline来进行。好处当然就是这样抽取可以避免错误传播,而且在关系抽取任务上可以利用抽取实体的信息。另外这样也更加端到端:输入句子,输出关系三元组。
1.可以直接把关系和实体统一到一个任务中。比如用序列标注模型,“特朗普是美国总统、他住在华盛顿”,特朗普标签为’E1-职位",美国总统标签为"E2-职位",他标签为"E1-住址",华盛顿标签为"E2-住址",这样我们就可以识别出任务中的两个关系三元组。使用所有的序列标注模型都可以完成这样的任务。当然,这个模型存在这样一个问题: 难以处理同一实体涉及多个关系的情况。
2.可以使用多任务学习,使用一个网络同时学习实体抽取和关系抽取模型。BERT-Based Multi-Head Selection for Joint Entity-Relation Extraction。
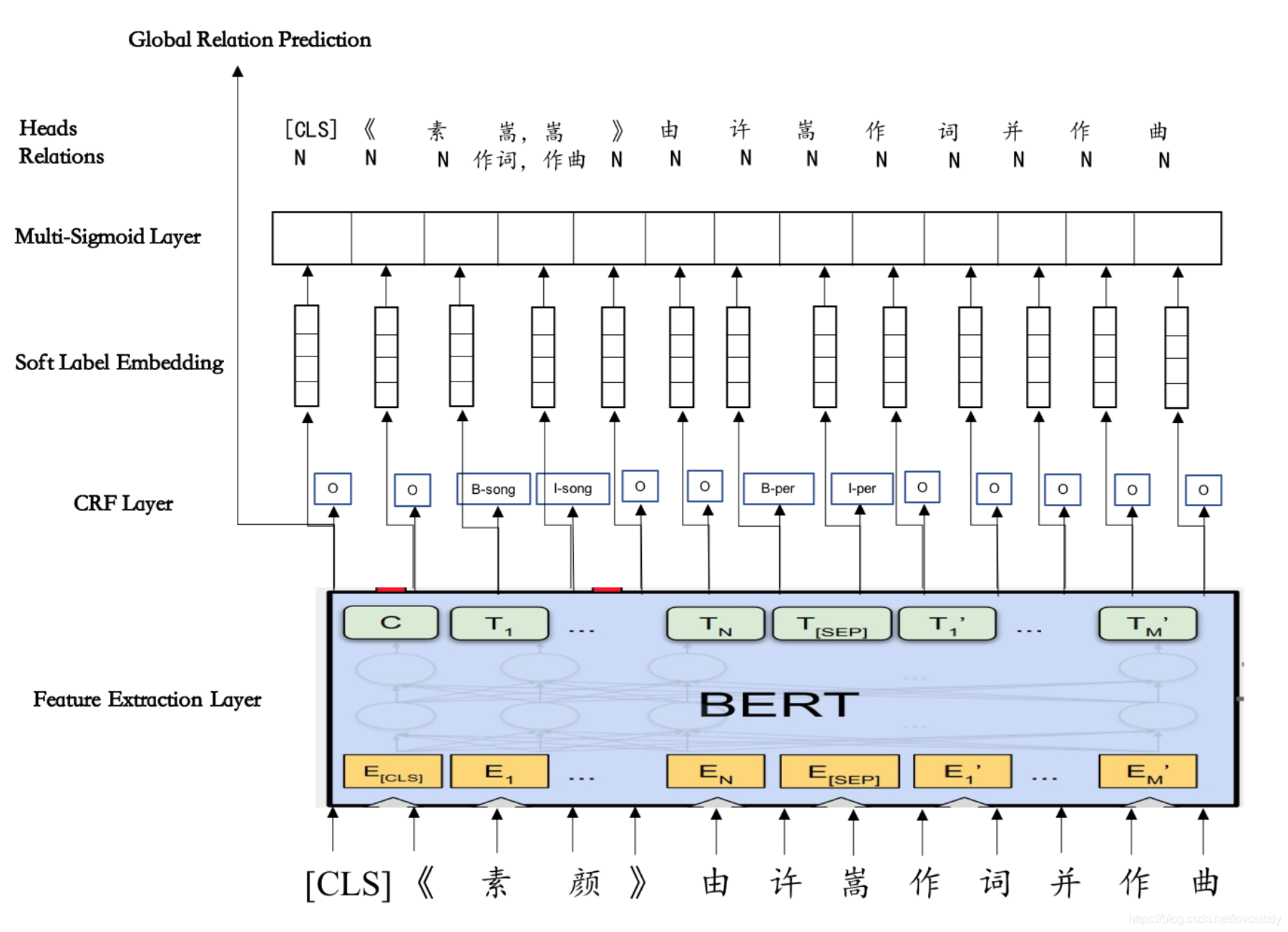
其同时学习关系抽取和实体抽取两个模型达到联合抽取的效果。而且为了避免前面出现的同一实体涉及多个关系这样的问题, 这里每个尾实体学习一个指向头实体的index。这样同一个头实体可以涉及多个关系。
属性和关系的区分。 具体来说对关于特朗普的两个三元组。"特朗普–性别–男性"和“特朗普–国家–美国“这两个三元组,我们是既可以划分到关于特朗普的属性三元组,也可以划分到关于特朗普的关系三元组的。那到底应该把”性别“和”国家“看作属性还是关系呢?大的来说属性表示的是实体的内在特性、关系表示的是实体的外部联系。而从操作的角度来说,对于其图谱最终存储到了知识库中。我们会通过 男性找到特朗普么?我们会通过 美国找到特朗普么?
如果我们访问这条三元组表达的信息主要通过实体,那么它应该被划分为一个属性。
如果我们访问这条三元组表达的信息可以通过实体和尾实体,那么它应被划分到关系中去。
数据集
SEM-EVAL2010 task8 英文数据集 (官网有吧、可联系邮件提供)
中文人名数据集 (github有吧、可联系邮件提供)
2019语言与智能技术竞赛数据 (可联系邮件提供)