note
- CRF条件随机场是全局最优(判别式模型),HMM是局部最优(生成式模型)
- 实体关系抽取方法概览:

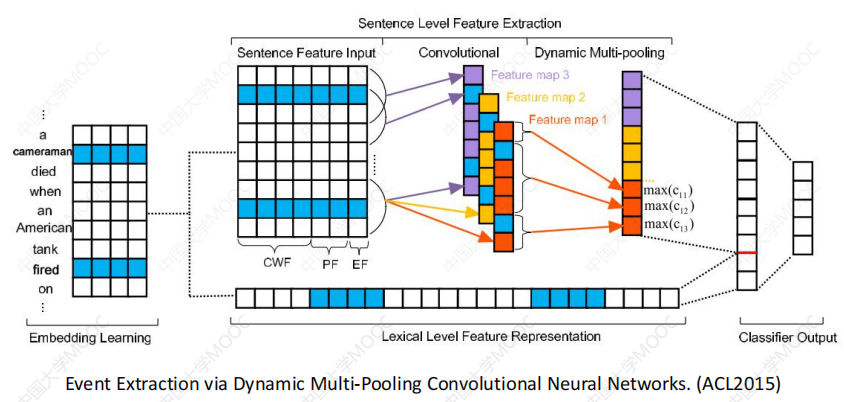
- 事件抽取主要分为事件的发现和分类和事件要素抽取两部分,又可以细分为触发词识别与事件分类和要素检测与要素角色分类。与关系抽取相比,事件抽取是一个更加困难和复杂的任务。
文章目录
一、知识工程和知识获取
- 知识图谱 ≠ 专家系统;传统知识工程不是获取三元组,也使用更多的人工。
- 知识图谱工程:简化的知识工程

- 从不同来源、不同结构的数据中进行知识提取,存入知识图谱

- 本次学习更多是NLP从文本获取知识:
- 命名实体识别:如从”库克非常兴奋“中找到实体【库克】,库克是个任务
- 术语提取(概念抽取):从预料中发现多个单词组成的相关术语
- 关系抽取:如从句子”王思聪是集团董事长王健林的独子“中抽取出:[王健林] <父子关系> [王思聪]
二、实体识别与分类
2.1 基于序列标注
(1)基本任务
分类:确定标签体系,选择模型,定义特征,模型训练
结果:给每个词打一个标签
注意:序列标签体系耗时

(2)HMM模型(隐马尔可夫模型)
- 有向图模型
- 假设特征之间是独立的
2.2 基于深度学习的NER

2.3 基于预训练语言模型的ENR

2.4 小结
- 实体识别仍面临着标签分布不平衡,实体嵌套等问题,制约了现实应用;
- 中文的实体识别面临一些特有的问题,例如:中文没有自然分词、用字变化 多、简化表达现象严重等等;
- 实体识别是语义理解和构建知识图谱的重要一环,也是进一步抽取三元组和 关系分类的前提基础。
三、关系抽取与属性补全
3.1 关系抽取方法的演变:

一个基于深度学习的开源中文关系抽取框架 https://github.com/zjunlp/deepke
实体关系抽取方法概览:
- 基于特征的方法需要人工设计特征,这类方法适用于标注数量较少,精度要求较高,人工能够 胜任的情况。
- 基于核函数的方法能够从字符串或句法树中自动抽取大量特征,但这类方法始终是在衡量两段 文本在子串或子树上的相似度,并没有从语义的层面对两者做深入比较。
- 上述两类方法通常都需要做词性标注和句法分析,用于特征抽取或核函数计算,这是典型的pipeline做法,会把前序模块产生的错误传导到后续的关系抽取任务,并被不断放大。
- 深度学习技术不断发展,端到端的抽取方法能大幅减少特征工程,并减少对词性标注等预处理 模块的依赖,成为当前关系抽取技术的主流技术路线。
3.2 基于图神经网络的关系抽取
- 图神经网络在图像领域的成功应用证明了以节点为中心的局部信息聚合同样可以有效的提 取图像信息。
- 思想:
- 利用句子的依赖解析树构成图卷积中的邻接矩阵,以句子中的每个单词为节点做图卷积操作。
- 如此就可以抽取句子信息,再经过池化层和全连接层即可做关系抽取的任务
- 论文:Graph Convolution over Pruned Dependency Trees Improves Relation Extraction. (EMNLP2018)
- 这篇论文是利用GCN实现关系抽取的高被引经典研究,提出了针对关系抽取量身定制的一种新型图卷积网络。模型使用有效的图卷积运算对输入句子的依存关系结构进行编码,然后抽取以实体为中心的表示,以进行可靠的关系预测。
- 设计了一个以路径为中心的剪枝策略移除依存树中与关系抽取无关的路径。

论文:Graph Convolution over Pruned Dependency Trees Improves Relation Extraction. (EMNLP2018)
3.3 基于胶囊神经网络多标签关系抽取
- 传统模型主要关注单标签关系抽取,但同一个句子可能包含多个关系。采用胶囊神经网络 可以帮助实现多标签的关系抽取。
- 如图所示:
- 模型首先通过预训练的 embedding 将句子中的词转化为词向量;
- 随后使用 BiLSTM 网络得到粗粒度的句子特征表示,
- 再将所得结果输入到胶囊网络,首先构建出 primary capsule,经由动态路由的方法得到与分类结果相匹配的输出胶囊。胶囊的模长代表分类结果的概率大小

Attention-based capsule networks with dynamic routing for relation extraction. (EMNLP2018)
3.4 属性补全任务
- 任务:事物的多个属性描述,补全。
- 方法:
- 抽取式:抽取输入文本中的字词,组成预测的属性值。预测出的属性值一定要在输入侧出现过。可解释性较高
- 生成式:直接生成属性值,该属性值不一定在输入文本出现,只要模型在训练数据中见过即可
- 应用:商品关键属性补全,即利用算法的图文预测item的类别、同款、品牌等

四、概念抽取
4.1 问题描述
- 如浙大是实体,高校是概念,浙大是高校,即浙大是高校的下位词
- 概念(Concept)是人类在认识过程中,从感性认识上升到理性认识,把所感知 的事物的共同本质特点抽象出来的一种表达
- 概念知识一般可以通过基于模板、基于百科和基于序列标注等方法进行获取
- 概念知识可以帮助自然语言理解,促进搜索、推荐等应用的效果
4.2 和GNN的结合
- Jointly Multiple Events Extraction via Attention-based Graph Information Aggregation. EMNLP 2018.
- Authors: Xiao Liu, Zhunchen Luo, Heyan Huang.
- 利用GCN做多事件抽取的研究,提出了一种新颖的联合多个事件抽取(JMEE)框架,通过引入句法捷径弧和图卷积网络加自注意力机制来建模图结构信息。
- 事件抽取模型需要对一句话中的所有token经过词嵌入层和Bi-LSTM层,之后将得到的无向图转换为带有自环的有向图结构,并利用GCN计算每个节点的表示: h v ( k + 1 ) = f ( ∑ u ∈ N ( v ) ( W K ( u , v ) ( k ) h u ( k ) + b K ( u , v ) ( k ) ) ) h_v^{(k+1)}=f\left(\sum_{u \in \mathcal{N}(v)}\left(W_{K(u, v)}^{(k)} h_u^{(k)}+b_{K(u, v)}^{(k)}\right)\right) hv(k+1)=f u∈N(v)∑(WK(u,v)(k)hu(k)+bK(u,v)(k))
五、事件识别与抽取
5.1 问题描述
- 事件是发生在某个特定的时间点或时间段、某个特定的地域范围内,由一个 或者多个角色参与的一个或者多个动作组成的事情或者状态的改变。
- 谁在啥时候,啥地方,做了啥事情
- 事件抽取主要分为事件的发现和分类和事件要素抽取两部分,又可以细分为触发词识别与事件分类和要素检测与要素角色分类。与关系抽取相比,事件抽取是一个更加困难和复杂的任务
- 事件结构远比实体关系三元组复杂,事件的Schema结构对事件抽取有很强的约束作用
5.2 基于结构预测
- Joint Inference 将各模型通过整体优化目标整合起来,可以通过整数规划 等方法进行优化。
- Joint Modeling (Structured) 将事件结构看作依存树,抽取任务相应转化为 依存树结构预测问题
- 基于神经网络的事件抽取需要大量标注样本:样本难标注,远程监督困难
六、KBQA知识问答的两种主流方法

知识问答:基于KB知识库(包含<主题,关系,对象>的事实集合)。一般常用的的知识库有DBpedia和WikiData。
- 一个复杂的KBQA问题:“Who is the first wife of the TV producer that was nominated for The Jeff Probst Show? 该问题需要找到以下的组合:
- 约束关系:我们正在寻找The Jeff Probst Show提名的电视制片人,因此需要找到一个与The Jeff Probst Show提名链接的实体,并且是一个 TV producer。
- 多跳推理:一旦我们找到电视制作人,我们需要找到他的妻子(wife)。
- 数值运算:一旦我们找到电视制作人的妻子,我们就会寻找第一任(first )妻子,因此需要比较数字并生成一个排名。

对于复杂的KBQA有两种主流方法,都是:
- 从识别问题的主题开始,并将其链接到知识库中的实体(主题实体);
- 在主题实体的知识库附近获得答案
6.1 基于语义解析的方法
将自然语言转化为中间的语义表示,然后转化为可以在KG中执行的描述性语言。
有4种方法:
- 语义解析(Semantic Parser)过程转化为query map 生成问题的各类方法;
- 仅在领域数据集适用的Encoder-Decoder模型化解析方法;
- 基于 Transition-Based 的状态迁移可学习的解析方法;
- 利用 KV-MemoryNN 进行解释性更强的深度 KBQA 模型。
6.2 基于信息检索的方法
- 首先会确定用户 Query 中的Entity Mention,
- 然后链接到 KG 中的主题实体(Topic Entity),并将与 Topic Entity 相关的子图(Subgraph)提取出来作为候选答案集合,
- 然后分别从 Query 和候选答案中抽取特征。
- 最后利用排序模型对 Query 和候选答案进行建模并预测。
七、知识抽取技术前沿
- 举一反三,面对低资源少样本场景,我们需要更加智能的少样本零样本知识 抽取方法;与时俱进, 知识是不断变化的,我们需要能够终身学习知识的框架
- 零样本知识抽取ZSL:基于可见标注数据集和可见标签集合,学习并预测不可见数据集结果
- 转换为问题:学习输入特征空间到类别描述的语义空间的映射
时间安排
| 任务 | 任务信息 | 截止时间 |
|---|---|---|
| - | 12月12日正式开始 | |
| Task01: | CP1知识图谱概论(2天) | 12月12-13日 周二 |
| Task02: | CP2知识图谱表示 + CP3知识图谱的存储和查询(上)(6天) | 12月14-19日 周六 |
| Task03: | CP3知识图谱的存储和查询(下)(3天) | 12月20-22日 周二 |
| Task04: | CP4知识图谱的抽取和构建(3天) | 12月23-25日 周五 |
| Task05: | CP5知识图谱推理(4天) | 12月26-29日 周二 |
Reference
[1] 推荐系统前沿与实践. 李东胜等
[2] 自然语言处理cs224n-2021–Lecture15: 知识图谱
[3] 东南大学《知识图谱》研究生课程课件
[4] 2022年中国知识图谱行业研究报告
[5] 浙江大学慕课:知识图谱导论.陈华钧老师
[6] https://conceptnet.io/
[7] KG paper:https://github.com/km1994/nlp_paper_study_kg
[8] 北大gStore - a graph based RDF triple store
[9] Natural Language Processing Demystified
[10] 玩转Neo4j知识图谱和图数据挖掘
[11] 锋哥的NLP知识图谱学习笔记
[12] https://github.com/datawhalechina/team-learning-nlp/tree/master/KnowledgeGraph_Basic
[13] 新一代知识图谱关键技术综述. 东南大学 王萌
[14] cs224w(图机器学习)2021冬季课程学习笔记12 Knowledge Graph Embeddings
[15] 关系抽取和事件抽取代码案例:https://github.com/taishan1994/taishan1994 (西西嘛呦)
[16] 年末巨制:知识图谱嵌入方法研究总结
[17] “知识图谱+”系列:知识图谱+图神经网络
[18] 【知识图谱】斯坦福 CS520公开课(双语字幕)
[19] 【论文阅读笔记】Graph Convolution over Pruned Dependency Trees Improves Relation Extraction
[20] 【论文翻译】Graph Convolution over Pruned Dependency Trees Improves Relation Extraction
[21] 论文笔记 EMNLP 2018|Jointly Multiple Events Extraction via Attention-based Graph Information Aggregation
[22] https://github.com/LIANGKE23/Awesome-Knowledge-Graph-Reasoning
[23] 再谈图谱表示:图网络表示GE与知识图谱表示KGE的原理对比与实操效果分析
[24] WSDM’23 | 工业界搜推广nlp论文整理
[25] 知识问答(KBQA)两种主流方法:基于语义解析和信息检索的方法介绍