不均衡样本集的处理
不均衡样本在分类时会出现问题,本质原因是模型在训练时优化的目标函数和在测试时使用的评价标准不一致。这种“不一致”可能是由于训练数据的样本分布于测试时期望的样本分布不一致(如训练集正负样本比例是1:99,而实际测试时期望的正负样本比例是1:1);也可能是由于训练阶段不同类别的权重与测试阶段不一致(如训练时认为所有样本的贡献是相等的,而测试时假阳性样本和假阴性样本有着不同的代价)。
基于上述分析,一般从两个角度来处理样本不均衡的问题,分别为基于数据和基于算法。
基于数据的方法
基于数据的方法是对样本进行重采样,使原本不均衡的样本变得均衡。使用\(C_{maj}\)表示样本数大的类别,\(C_{min}\)表示样本数小的类别。对应的样本集分别为\(S_{maj}\)和\(S_{min}\),并且有|\(S_{maj}\)|>>|\(S_{min}\)|。
1. 随机采样
随机采样是最简单的一种方法,一般分为过采样(Over-sampling)和欠采样(Under-sampling)。
随机过采样是从少数样本集\(S_{min}\)中随机重复抽取样本(有放回)以得到更多样本;随机欠采样则相反,从多类样本集中随机选取较少的样本(有放回或无放回)。
存在问题:过采样对少数类样本进行了多次复制, 扩大了数据规模, 增加了模型训练的复杂度, 同时也容易造成过拟合; 欠采样会丢弃一些样本, 可能会损失部分有用信息, 造成模型只学到了整体模式的一部分。
2. 采样一些方法生产新样本,解决过采样产生的问题
为了解决随机采样存在的一些问题,可以在采样时并不是简单的复制样本,而是采用一些方法生产新的样本。
-
SMOTE算法
SMOTE算法对少数类样本集\(S_{min}\)中每个样本x,从它在\(S_{min}\)中的K近邻中随机选一个样本y, 然后在x,y连线上随机选取一点作为新合成的样本(根据需要的过采样倍率重复上述过程若干次),这种合成新样本的过采样方法可以降低过拟合风险。
存在问题:SMOTE算法为每个少数类样本合成相同数量的新样本,这可能会增大类间重叠度,并且生成一些不能提供有益信息的无用样本。下面的两种算法就是对SMOTE算法的改进。
如下图所示:
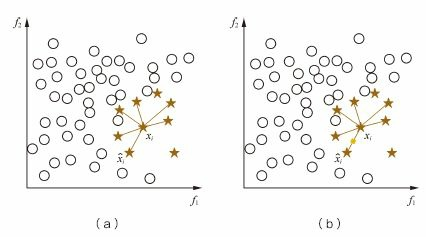
-
Borderline-SMOTE
Borderline-SMOTE只给那些处在分类边界上的少数类样本合成新样本
-
ADASYN
ADASYN给不同的少数类样本合成不同个数的新样本 。
-
数据清理方法Tomek Links
使用数据清理的方法来进一步降低合成样本带来的类间重叠,得到更加良定义(well-defined)的类簇。
3. 使用Informed Undersampling来解决欠采样带来的数据丢失问题
-
Easy Ensemble算法。
每次从多数类Smaj中上随机抽取一个子集E(|E|≈|\(S_{min}\)|), 然后用E+\(S_{min}\)训练一个分类器; 重复上述过程若干次, 得到多个分类器,最终的分类结果是这多个分类器结果的融合。
-
Balance Cascade算法
级联结构, 在每一级中从多数类\(S_{maj}\)中随机抽取子集E, 用E+\(S_{min}\)训练该级的分类器; 然后将\(S_{maj}\)中能够被当前分类器正确判别的样本剔除掉, 继续下一级的操作, 重复若干次得到级联结构; 最终的输出结果也是各级分类器结果的融合
-
NearMiss
利用K近邻信息挑选具有代表性的样本
-
Onesided Selection
采用数据经历技术
4. 其他一些有用的方法
-
基于聚类的方法
基于聚类的方法,利用数据的类簇信息来指导过采样/欠采样操作;
-
数据扩充方法
是一个过采样技术,对少数类样本进行一些噪声扰动或变换(如图像数据集中对图像进行裁剪、翻转、旋转、光照等)以构造出新样本;
-
Hard Negative Mining
是一种欠采样,把比较难分的样本抽取出来,用于迭代分类器。
基于算法的方法
-
改变模型训练时的目标函数
当样本不均衡时,改变模型训练的目标函数,如使用代价敏感学习中不同类别有不同的权重来矫正这种不平衡性。
-
改变问题类别
当样本极度不平衡时,可以将问题转变为单类学习(one-class learning)、异常检测(anomaly detection)。