说明:目前 只记录了 过采样 和 欠采样 的代码部分
1 样本分布不均衡描述:
样本量少的分类所包含的特征过少,建立的模型容易过拟合
过抽样:
from imblearn.over_sampling import SMOTE
又称上采样(over-sampling),通过增加分类中少数类样本的数量来实现样本均衡
import pandas as pd # 导入数据文件 df = pd.read_table('data.txt', sep='\t')

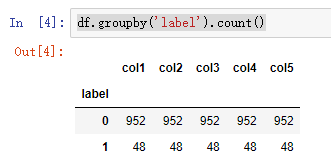
2 查看数据分布,发现分布不均衡
df.groupby('label').count()
3 切片,分开 特征x 和 目标y
x, y = df.iloc[:,:-1], df.iloc[:,-1]
4 使用 SMOTE 进行过抽样处理
# 导包 from imblearn.over_sampling import SMOTE # 建立模型 smote_model = SMOTE() # 进行过抽样处理 x_smote, y_smote = smote_model.fit_sample(x, y) # 将特征值和目标值组合成一个DataFrame smote_df = pd.concat([x_smote,y_smote], axis=1)
处理完成,查看分布情况

5 使用 RandomUnderSampler 方法进行欠抽样处理
from imblearn.under_sampling import RandomUnderSampler # 建立模型 under_model = RandomUnderSampler() # 欠抽样处理 x_under, y_under = under_model.fit_sample(x,y) # 合并数据 under_df = pd.concat([x_under, y_under],axis=1)
处理完成,查看分布情况
