目录
1)在线难样本挖掘(online hard example mining,OHEM)
一、候选框大量重叠问题
1、NMS核心思想
NMS:非极大值抑制,抑制的是得分低的预测框,涉及到两个指标,IOU(交并比:两个框的重叠区域面积与两个框并集面积的比值)和预测框得分,若有多个预测框预测的是同一个物体,若两个框的IOU值大于阈值(一般阈值取0.5和0.7),那么NMS算法将会把得分低的预测框丢弃。

2、 步骤:
1)得到所有的预测框
2)将预测框按照得分降序排序
3)将最高得分的预测框与剩余的预测框,计算IOU,将IOU大于阈值的框去掉
4)将最高得分的预测框记录下来,再从剩下的预测框中重复1)-4)直到只有一个预测框为止



3、缺陷
1)当物体出现比较密集的时候,两个预测框的IOU比值也有可以会超过阈值,强制将得分低的预测框去掉,会导致漏检,降低模型的召回率。这对于互相遮挡的物体群检测是不利的。
2)阈值难以确定。过高导致误检率高,过低导致漏检低。
3)单纯使用预测框得分来作为预测框的置信度,不太合适,因为有的预测框虽然得分高,但是预测的位置不准确
4)速度慢,算法涉及多重循环,在进行大量预测框的计算时,会速度减慢
4、改进
1)soft NMS——衰减的方式来减小预测框的分类得分
NMS强制将IOU超过阈值的低分预测框归零,soft nms是通过衰减的方法来将低分的预测框的得分降低,这样在后面可能会将这个框保留下来。开始不会将预测框强制去掉,而是到最后去掉低于置信度阈值的预测框

 具体得分衰减公式主要分为线性衰减和高斯衰减,线性衰减因为在阈值附近会出现得分的突变,不是连续的,这种跳变会给检测带来很大的波动,一般情况下采用的是连续的高斯衰减。
具体得分衰减公式主要分为线性衰减和高斯衰减,线性衰减因为在阈值附近会出现得分的突变,不是连续的,这种跳变会给检测带来很大的波动,一般情况下采用的是连续的高斯衰减。
Soft-NMS的改进有两种形式,一种是线性加权的:

一种是高斯加权的:

不足:
1)阈值还是比较难确定
2)得分高的位置未必准确
改进:
相对于nms的改进在于不是强制将得分低的预测框给丢弃,而是将其保留但是降低了其得分,使得对于密集目标检测的时候不至于漏检,减缓了这种问题,有效地提高了准确率
2)softer nms——增加了位置置信度
nms和soft nms都是采用了分类置信度(得分)来作为预测框的排序指标,这种情况只适用于所有的得分高的预测框的位置和分类一样准确的情况下。但是实际情况不是这样的,分类得分高的预测框其位置不一定准确,因此基于这个考虑,提出了sofer nms,主要是在nms的基础上不断地改变预测框的位置,以此来增加预测框的位置精度。
二、样本不平衡问题
1、不平滑的来源(3方面)
1)正负样本不平衡
正样本:含有目标物体的候选框
负样本:不含目标物体的候选框
在一张图像中,一般只存在个位数的目标对象,但是深度学习网络一般会生成大量的候选框,比如faster-rcnn利用RPN网络生成了2000个锚框,这里面可能有100个正样本框,其余都是大量的背景框(负样本),导致正负样本数量极度不平衡,降低了精度
2)难易样本不平衡
难样本:分类不明确的样本,比如候选框在前景和背景的过渡区域的框,分为难正样本,难负样本
易样本:分类明确,分为易正样本与易负样本,和真实框重合度非常高为易正样本,和真实框不重合的为易负样本
在fasterrcnn中rpn生成框网络中,生成了大量的候选框,大部分的候选框都是易样本,这对于模型的参数收敛作用是非常有限的,而我们更加希望的是模型去利用难样本进行模型的训练,以此来提高精确度。但是大量的候选框都是在背景上,这导致易样本数量庞大,而这部分更有价值的难样本的数量却非常有限,这就造成了难易样本的不平衡。一般难易不平衡和正负样本不平衡问题是有交叉的,这就导致解决这两个问题的方法是可以通用有效的。
3)类别间样本不平衡
在有些问题中,存在多类别分类,但是不同目标的数量不一样,如数据集中有100万个车辆的标签,有1000个行人的标签,这导致在训练的过程中,模型会更加地关注与减小车辆的损失,而导致行人的检测精度大大下降。不同类别的数量差异,导致了类别间不平衡。
2、解决样本不平衡的方法
通用方法:
1)在fasterRcnn和SSD中,根据样本与真实物体的IOU大小,设置了3:1的正负样本比例。缓解了前两种的不均衡物体
2)在RPN中根据前景的得分排序筛选出了2000个框作为候选框,也实现了样本不平衡的缓解
3)权重惩罚:对于难易样本不平衡和类别间不平衡的方法,可以增加对难样本和少样本的损失权重,缓解不平衡问题
4)数据增强:扩充数据量来实现类别间不平衡的方法
1)在线难样本挖掘(online hard example mining,OHEM)
由两个RCNN组成,一个RCNN负责前向传播,得到难样本,一个RCNN进行前向和后向传播,实现参数的更新。难样本的话主要是将损失较大的样本作为难样本
2) Focal Loss(专注难样本的一个损失函数)
参考:https://blog.csdn.net/qq_42013574/article/details/105864230
1.标准交叉熵损失
标准的交叉熵(Cross Entropy,CE)函数,其形式如下所示。
公式中,p代表样本在该类别的预测概率,y代表样本标签。可以看出,当标签为1时,p越接近1,则损失越小;标签为0时p越接近0,则损失越小,符合优化的方向。(当预测标签越接近真实标签时,损失越小)标准的交叉熵中所有样本的权重都是相同的,因此如果正、负样本不均衡,大量简单的负样本会占据主导地位,少量的难样本与正样 本会起不到作用,导致精度变差。
为了方便表示,按照中将p标记为pt:
则交叉熵可以表示为:
2.平衡交叉熵损失为了改善样本的不平衡问题,平衡交叉熵在标准的基础上增加了 一个系数αt来平衡正、负样本的权重,αt由超参α按照下式计算得来,α取值在[0,1]区间内。
有了αt,平衡交叉熵损失公式如式:
尽管平衡交叉熵损失改善了正、负样本间的不平衡,但由于其缺 乏对难易样本的区分,因此没有办法控制难易样本之间的不均衡。3.Focal Loss
Focal Loss为了同时调节正、负样本与难易样本,提出了如下式所示的损失函数。
对于该损失函数,有如下3个属性:与平衡交叉熵类似,引入了αt权重,为了改善正负样本的不均衡,可以提升一些精度。
·(1-pt)^γ是为了调节难易样本的权重。当一个边框被误分类时,pt 较小,则(1-pt)γ接近于1,其损失几乎不受影响;当pt接近于1时,表明其分类预测较好,是简单样本,(1-pt)γ接近于0,因此其损失被调低了。
γ是一个调制因子,γ越大,简单样本损失的贡献会越低。为了验证Focal Loss的效果,何凯明等人还提出了一个一阶物体 检测结构RetinaNet。
对于RetinaNet的网络结构,有以下5个细节:
在Backbone部分,RetinaNet利用ResNet与FPN构建了一个多尺 度特征的特征金字塔。
RetinaNet使用了类似于Anchor的预选框,在每一个金字塔层, 使用了9个大小不同的预选框。
分类子网络:分类子网络为每一个预选框预测其类别,因此其 输出特征大小为KA×W×H,A默认为9,K代表类别数。中间使用全 卷积网络与ReLU激活函数,最后利用Sigmoid函数输出预测值。
回归子网络:回归子网络与分类子网络平行,预测每一个预选框的偏移量,最终输出特征大小为4A×W×W。与当前主流工作不同 的是,两个子网络没有权重的共享。
·Focal Loss:Focal Loss在训练时作用到所有的预选框上。对于两个超参数,通常来讲,当γ增大时,α应当适当减小。实验中γ取2、α取0.25时效果最好。




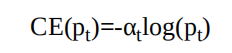

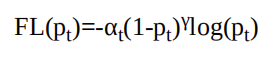

3、一阶段和二阶段的区别
fasterrcnn的精度比SSD高的原因主要是因为多了一个RPN网络,用于生成正负样本3:1的样本,解决了正负样本不平衡的问题,但是SSD一阶段的是直接筛选得到的预测框,因此主要的原因就是因为正负样本不平衡的原因造成了二者之间精度的区别。而focal loss损失函数构造出来的retinanet模型在精度上是可以和fasterrcnn媲美的。
三、过拟合问题
可看文章:原创 【深度学习】——过拟合的处理方法