和HMMs相比,Log-Linear Tagging Models的核心优势在于它高度灵活的表示,它可以让丰富的特征在模型中很容易地聚合起来!
提示:MEMMs和Log-Linear Tagging Model是同一个模型,因为ME本质上就是Log-Linear Model,而且MEMMs中用到的马尔可夫假设和HMM中用到的是几乎一样。只不过MEMMs是一个判别模型,它学习的是一个条件分布!
条件标注模型

有三个核心问题需要解决:

我们用对数线性模型来定义条件标注模型,用对数线性模型的参数估计方法来估计参数,用维特比算法的变形来寻找最优标注序列即解码问题。
1,Trigram MEMMs
在理解玩HMM和对数线性模型之后,这个模型就变得十分简单了。
我们的根本任务是对以下条件分布建模:
首先利用链式法则和二阶马尔可夫假设对以上的条件分布进行分解,得到:
利用对数线性模型对以下概率进行估计:
其中,必须理解 的定义。
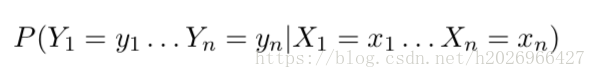
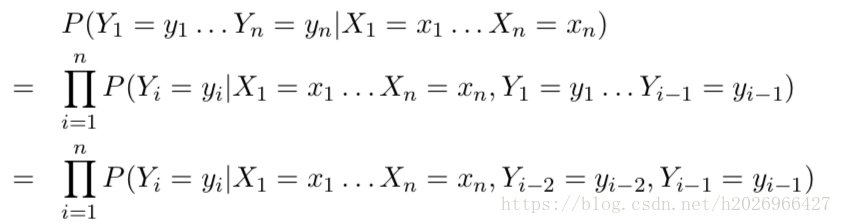

则Trigram MEMMs的正式定义如下:
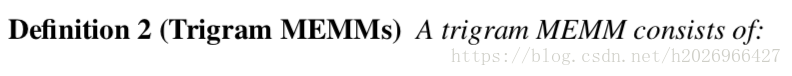

2,Features in Trigram MEMMs
Trigram MEMMs容易聚合大量特征的优点使得它比Trigram HMM强的多!而且Trigram MEMMs可以聚合任意形式的特征!
主要特征有:
Word/tag feature:类似HMM中的e(x|y)。
Prefix and Suffix feature:拼写特征,类似HMM中的那些低频词中的伪词。
- Trigram,Bigram and Unigram Tag features:词性搭配特征,类似HMM中的q(VB|DT,JJ)。
- Other Contextual Features
- Other Features


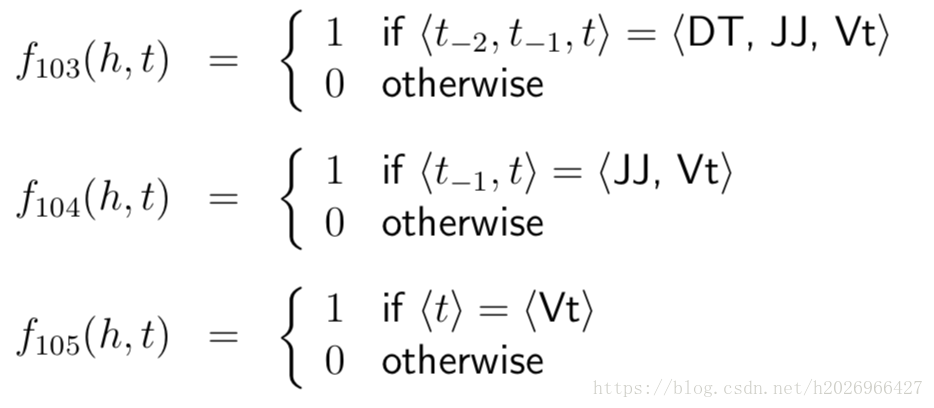


3,Trigram MEMMs的参数估计
和对数线性模型的方法一样,通过最大似然估计将其转化为最优化问题。
对数似然函数如下:

则所估计的参数为:
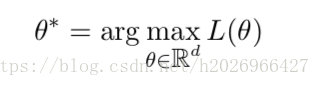
4,MEMMs的解码问题
解码问题如下:

维特比算法求解:
MEMMs中的维特比算法的递归式和HMM中的维特比算法的递推式区别很小,如下:

算法详细流程如下:

还是比较容易理解的。
