数据分析学习总结笔记07:回归分析概述
1 什么是回归分析
1.1 回归分析概述
回归是用一条有代表性的直线或曲线(在高维空间中,则为超平面或一般曲面)来拟合输入输出数据的一种方法。
拟合的直线或函数刻画了变量之间的相互联系,基于这种联系我们可以对新获得的输入数据的输出结果进行预测。
回归分析:主要研究变量间的统计联系,通过建立统计模型研究变量间相互关系的密切程度、结构状态及进行预测。
1.2 “回归”的由来
- 回归的古典意义:
- 高尔顿(Galton)遗传学的回归概念。
- 父母身高与子女身高的关系:无论高个子或低个子的子女都有向人的平均身高回归的趋势。
- 高尔登把这种孩子的身高向平均值靠近的趋势称为一种回归效应,而他发展的研究两个数值变量的方法称为回归分析。
- 回归的现代意义:
- 一个因变量对若干解释变量依存关系的研究,用恰当的数学模型近似地表达或估计变量之间的变化关系。
- 实质:由已知的或固定的自变量的数值,去估计因变量的总体平均值。
1.3 回归分析归纳
1.3.1 回归分析的主要内容

1.3.2 回归分析的一般模型
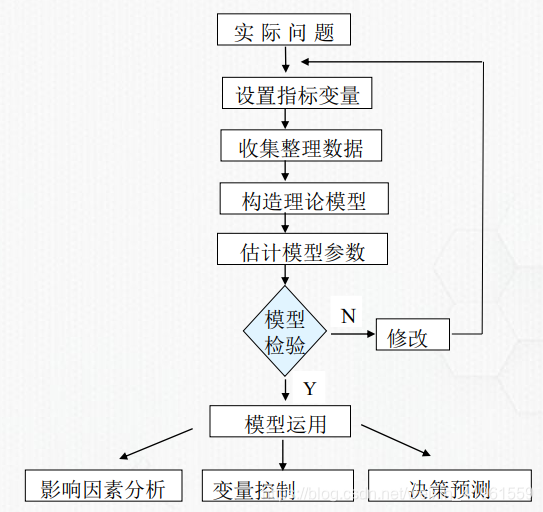
2 统计学中的回归模型
2.1 相关分析与回归分析
(1)相关分析
- 用一个指标(相关系数)来表明现象间相互依存关系的密切程度。
- 广义的相关分析包括相关关系的分析(狭义的相关分析)和回归分析
(2)回归分析
- 指对具有相关关系的现象,根据其相关关系的具体形态,选择一个合适的数据模型(称为回归方程式),用来近似地表达变量间的平均变化关系的一种统计分析方法。
(3)两者的关系
- 相关分析是回归分析的基础和前提。
- 回归分析是相关分析的深入和继续。
2.2 回归模型的具体化

2.3 回归类型的判断
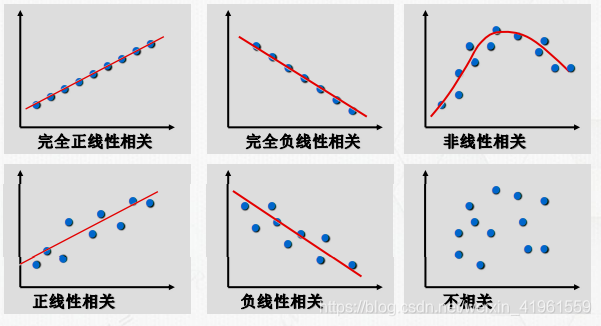
2.4 回归分析中的统计问题

3 机器学习角度看回归
3.1 数据分析问题的不同视角
- 统计视角
- 以数学模型为基础;
- 基于人类的既有经验和理论推导;
- 需要对问题场景和数据特征做出种种假设;
- 大数据时代的挑战:模型与现实存在一定鸿沟;大数据提供了直接从数据本身进行探索的可能。
- 机器学习视角
- 以算法为中心 ,算法就是处理数据的步骤和规则;
- 假设数据背后的理论结构是复杂和未知的,因而不太关注模型假设和统计检验;
- 致力于从算法结构上模拟数据的产生过程;
- 达到较好的预测效果;
- 缺陷:难以对模型背后的理论机制进行解释。
3.2 机器学习分类
- 有监督学习
- 训练集数据有标签
- 回归(输出变量连续)
- 分类(输出变量离散)
- 无监督学习
- 训练集数据无标签(只有输入变量)
- 聚类
- 降维
3.3 机器学习的流程
(1)定义问题
- 判断是否有人脸(目标检测,分类问题)
- 判断性别(分类,输出变量离散)
- 判断年龄(回归,输出变量连续)
(2)收集数据
- 大量数据
- 标注信息(是否为人脸/性别/年龄)
(3)特征设计

(4)训练模型
- 对象:训练集
- 任务:通常是调整拟合模型的参数
- 目标:拟合的总体偏差最小(通常需定义各种损失函数)
- 技术:基于梳理统计(传统);基于数值计算和优化技术(现代)
(5)测试模型
- 对象:测试集
- 实现:交叉验证、自助法等
本文主要根据个人学习(应用回归分析MOOC),并搜集部分网络上的优质资源总结而成,如有不足之处敬请谅解,欢迎批评指正、交流学习!
