1 引言
生存分析是一套统计方法,用来解决诸如“多长时间后,某个特定事件发生”这样的问题; 换句话说,也可以称之为事件时间分析。 这种方法被称为生存分析,是由于主要是由医学研究人员开发的,他们更感兴趣的是寻找不同群体患者的预期寿命(例如: 用药物a治疗的组群1和用药物b治疗的组群2)。这种分析不仅可以应用于传统的死亡事件,还可以应用于不同商业领域中的许多不同类型的事件。
2 定义
如上所述,生存分析也称为事件时间分析。因此,从名称本身来看,事件和时间的定义对于生存分析是至关重要的。为了理解时间和事件,本文将为一些事例定义时间和事件。
(1)机械操作中的预测性维护:生存分析应用于机械部件/机器,以预测“机器能够运行的时长? ”。预测性维护是其应用之一。
- 事件:机器出现故障的时间点。
- 初始时间:连续作业时机器启动的时间。
- 时间的尺度:可以是周、天、小时。
- 事件发生所需时间:事件发生的时间点和初始时间的差。
(2)客户分析(客户留存):通过生存分析,专注于那些高收益但低留存的客户,进行流失预防工作。这种分析也有助于计算客户生命时间价值。
- 事件:客户流失的时间点。
- 初始时间:客户与公司开始服务 / 订阅的时间。
- 时间尺度:几个月/几周。
- 事件发生所需时间:事件发生的时间点和初始时间的差。
(3)营销分析(同期群分析):生存分析评估每个营销渠道的留存率。
- 事件:客户取消订阅某个营销渠道的时间点。
- 初始时间:客户开始该营销渠道的服务 / 订阅的时间。
- 时间尺度:几个月/几周。
(4)精算:给定人群的风险,生存分析评估该人群在特定时间范围内死亡的概率。这种分析有助于保险公司对保费进行评估。
3 数学直观
假设有一个非负连续随机变量T,代表直到某些事件发生的时间。例如,T可能表示:
- 从客户订阅到客户流失的时间。
- 从机器启动到故障的时间。
- 从诊断出一种疾病到死亡的时间。
T是非负连续型随机变量,因此可以取任何非负实数值(包括0)。
对于这样的随机变量,通常使用概率密度函数和累积分布函数描述它们的分布特征。
假设该随机变量的概率密度函数f(t)和累积分布函数F(t)。

简单来说,
定义的形式:
h(t) = [(S(t) -S(t + dt))/dt] / S(t) (limit dt->0)
从上面的公式中可以看出它有两个部分
瞬时事件发生率: (s(t) - s(t + dt)) / dt;也可以看作生存曲线任意点t的斜率,或任意时刻t的死亡率。
举例来说:
-
假设总人口为P。在这里,s(t) - s(t + dt),这个差值给出了dt时间内死亡人数的比例:
- 在t时刻存活的人数是s(t)*P;在t + dt时刻存活的人数是s(t + dt)*P。
- 在时刻死亡的人数是(s(t) - s(t + dt))*p,在t时的瞬时死亡率是(s(t) - s(t + dt))*p / dt。
- t时刻的存活率:s(t);t时刻的存活种群:s(t)*p。
-
因此,将在dt时间内死亡的人数,除以在t时间内存活的人数,得到危险率函数作为衡量在t时刻存活的人的死亡风险的方法。
危险率函数不是密度或概率。然而,假定受试者一直存活到t时刻,可以把它看作是在(t)和(t + dt)之间一个无穷小时间周期内的失败概率。从这个意义上说,危险是一种风险的度量: 在t1和t2时刻间的危险越大,那么在这个时间间隔内失败的风险越大。
因为(s(t) - s(t + dt)) / dt = f (t),则h(t) = f(t) / S(t);这个函数的美妙之处在于,生存函数可以由危险率函数导出,反之亦然。在Cox比例风险模型(本文最后一部分)中,当从给定的危险率函数导出一个生存函数时,这种方法的作用将更加明显。
这些是理解生存分析所需的最重要的数学定义和公式。下面,本文将向前推进到生存曲线的估计。
4 Kaplan-Meier 估计
在上面的数学公式中,假设了pdf函数,从而从中推导出了生存函数。由于无法得到真正的种群生存曲线,因此从数据中估计生存曲线将是最好的选择。
估计生存曲线主要有两种方法。
- 第一种方法是参数方法。这种方法假设一个参数模型,这个模型基于一定的分布,如指数分布,然后估计参数,最后推导出生存函数的估计量。
- 第二种方法是一种强有力的非参数方法,称为 Kaplan-Meier估计。本文将在这一部分讨论它,并尝试手动得到Kaplan-Meier 曲线,以及使用Python库(lifelines)。
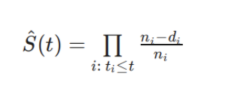
这里,定义ni为在ti时刻前处于危险状态的人口;定义di为在ti时刻之前发生事件的数量。通过下面的例子,这些概念将变得更加清晰。
本文将使用一个非常小的自创数据,以了解Kaplan Meier估计曲线的创建,以及python库的使用。
示例的事件、时间和时间尺度定义:
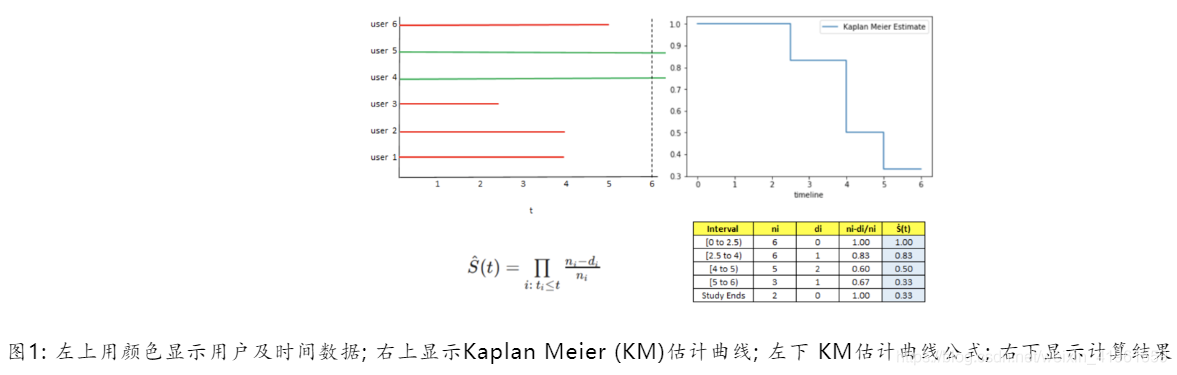
- 下面的例子(见下图)显示了某网站6个用户的数据。这些用户访问该网站,并于几分钟后离开。
- 因此,关注的事件是用户在网站停留的时间。初始时间定义为用户打开网站的时间,时间尺度以分钟为单位。这项研究从t=0开始,到t=6分钟时结束。
截尾:
- 这里值得注意的是,在研究期间, 6个用户中有4个发生事件(红色显示),而另两个用户(绿色显示)仍在继续,直到研究结束也未发生事件;这样的数据称为截尾数据。
- 在出现截尾的情况下,比如案例中的用户4和用户5,不知道事件将在什么时候发生,但仍然使用这些数据来估计生存的可能性。如果选择剔除截尾数据,那么估计结果很有可能有较大偏差并且被低估。与其他许多统计技术相比,包含截尾数据来计算估计值,使得生存分析非常强大。
知识KM曲线的计算和解释:
-
创建KM曲线所做的计算(见下图)。在图中,Kaplan Meier估计曲线,x轴为事件发生的时间,y轴是估计的生存概率。
-
从t=0到t<2.5即t∈[0, 2.5),在t=0时刻处于危险中的用户数(ni)为6,在 t=0时刻发生的事件数(di)为0,因此对于这个区间内的所有时间t,估计s(t)为1。根据事件的定义,用户打开网站和退出网站之间的时间大于2.499…的概率为100%。
-
从t=2.5到t<4即t∈[2.5, 4),在时间t=2.5(2.4999…分钟) 之前的时间段,处于危险中的用户数(ni)为6,在时间 t=2.5时刻发生的事件数(di)为1,因此在这个时间段内,估计s(t)为0.83。根据事件的定义,用户打开网站和退出网站之间的时间大于3.999…的概率为83%。
-
从t=4到t<5即t∈[4,5],在时间t=4(3.999…分钟)前处于危险状态的用户数(ni)为5,在时间t=4时刻发生的事件数(di)为2,因此在这个时间段内,估计s(t)为0.5。这一结果也可用简单的数学理论,相对频率数学加以验证。对于任意t∈[4,5],假设 t=4.5,初始用户总数为6,剩余用户总数为3。因此,用户在网站上花费超过4.5分钟(或任何时间t∈[4,5])分钟的概率为(3 / 6),即50%。
-
类似地,可以估计其他时间间隔的概率(见图1中的表计算)。
数学上,对于任意时刻t∈[t1,t2],有:S(t) = P( [0, t1]时间内存活) × P( [t1, t]时间内存活 | [0, t1]时间内存活)
# Python code to create the above Kaplan Meier curve
from lifelines import KaplanMeierFitter
## Example Data
durations = [5,6,6,2.5,4,4]
event_observed = [1, 0, 0, 1, 1, 1]
## create a kmf object
kmf = KaplanMeierFitter()
## Fit the data into the model
kmf.fit(durations, event_observed,label='Kaplan Meier Estimate')
## Create an estimate
kmf.plot(ci_show=False) ## ci_show is meant for Confidence interval, since our data set is too tiny, thus i am not showing it.
如前所述,生存分析可用于队列分析。因此,这里使用电信客户流失数据集,来深入了解不同群体中客户的生命(https://www.kaggle.com/blastchar/telco-customer-churn)
代码:https://github.com/anurag-code/Survival-Analysis-Intuition-Implementation-in-Python
根据客户是否订阅了流媒体电视,创建两个客户群。目的是了解哪个群体拥有更好的顾客留存率。
kmf1 = KaplanMeierFitter() ## instantiate the class to create an object
## Two Cohorts are compared. Cohort 1. Streaming TV Not Subscribed by users, and Cohort 2. Streaming TV subscribed by the users.
groups = df['StreamingTV']
i1 = (groups == 'No') ## group i1 , having the pandas series for the 1st cohort
i2 = (groups == 'Yes') ## group i2 , having the pandas series for the 2nd cohort
## fit the model for 1st cohort
kmf1.fit(T[i1], E[i1], label='Not Subscribed StreamingTV')
a1 = kmf1.plot()
## fit the model for 2nd cohort
kmf1.fit(T[i2], E[i2], label='Subscribed StreamingTV')
kmf1.plot(ax=a1)

存在有两个生存曲线,每个客户群一个。从曲线可以看出,订购了流媒体电视的客户比没有订购流媒体电视的客户有更好的客户留存率。在时间线上任意一点,都可以看到蓝色客户的生存率小于红色客户的生存率。对于蓝色,前10个月存活率呈下降趋势,后10个月存活率呈上升趋势,而红色的存活率下降趋势相对稳定。因此,对于没有订购流媒体电视的人来说,应对留存率不稳定的前10个月加强关注。
可以对不同群组的生存曲线进行更多的群组分析。这种群组分析有限地表明了生存分析的潜力,因为我们将其用于聚合级别的数据,甚至可以根据基线生存曲线上协变量的影响为单个用户创建生存曲线。
5 Cox比例风险模型
群组中个体发生事件的时间对于总体的生存曲线非常重要;然而在现实生活中,除了事件数据外,还有该个体的协变量(其他特征)。在这种情况下,了解协变量对生存曲线的影响是非常重要的。如果知道相关的协变量值,这将有助于预测个体的生存概率。
例如,在上面讨论的电信客户流失示例中,除了得到每个客户流失的时间(事件时间t),还会有客户的性别、月费、合伙人和电话服务等。其他变量是本例中的协变量。了解这些协变量如何影响生存概率密度函数是很重要的。
在这种情况下,条件生存函数S(t|x) = P(T > t|x)。x表示协变量。在示例中,生存函数即,S(留存时间>t | (性别,月费,合伙人,电话服务 等))。
Cox比例风险模型是协变量和生存函数相结合的模型。首先是对危险函数进行建模。

该模型背后的思想是,个体的对数风险是其静态协变量的线性函数,以及随时间变化的总体水平基线风险。 [来源: lifelines文档]
根据上述方程式,还可以推导出累积条件危险函数:
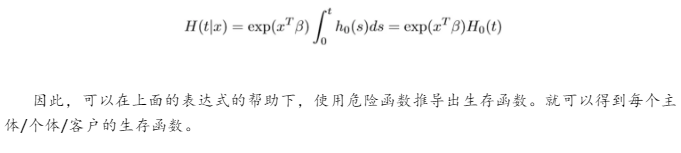
基本的 python 实现:
在lifelines库的帮助下讨论其在python中的基本实现。使用相同的电信客户流失数据集,运行python代码来预测客户(个人)级别的生存函数。
from lifelines import CoxPHFitter
## My objective here is to introduce you to the implementation of the model.Thus taking subset of the columns to train the model.
## Only using the subset of the columns present in the original data
df_r= df.loc[:['tenure', 'Churn', 'gender', 'Partner', 'Dependents', 'PhoneService','MonthlyCharges','SeniorCitizen','StreamingTV']]
df_r.head() ## have a look at the data

## Create dummy variables
df_dummy = pd.get_dummies(df_r, drop_first=True)
df_dummy.head()

# Using Cox Proportional Hazards model
cph = CoxPHFitter() ## Instantiate the class to create a cph object
cph.fit(df_dummy, 'tenure', event_col='Churn') ## Fit the data to train the model
cph.print_summary() ## HAve a look at the significance of the features
cph.plot()

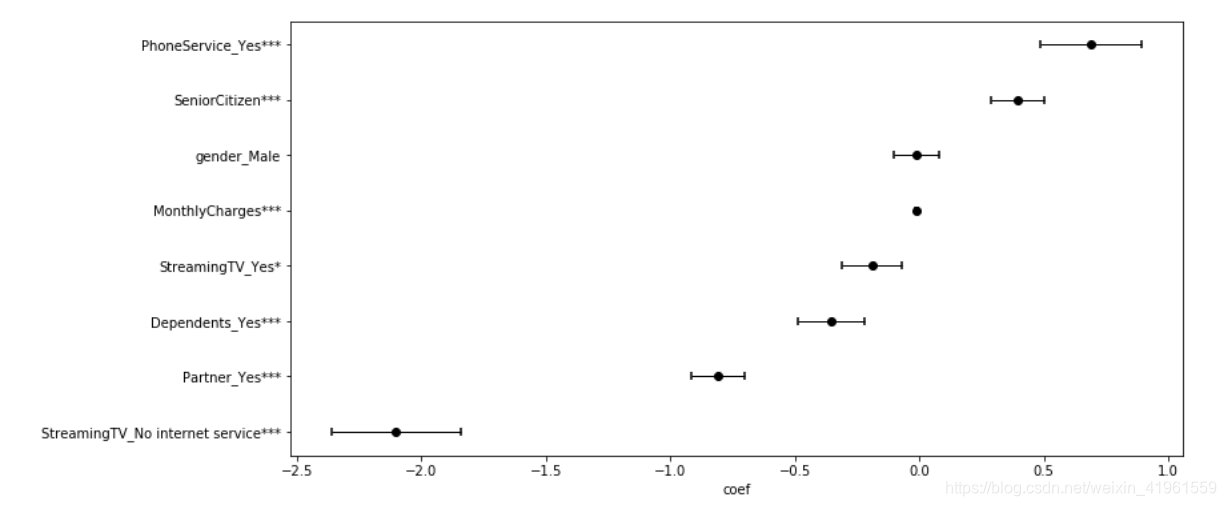
以上的统计摘要表明了协变量在预测客户流失风险方面的重要性。性别在流失预测中并未起到重要作用,而其他所有的因素都是重要的。
这里需要注意的有趣的一点是,月费和性别协变量的 β (coef)值大约为零(~-0.01),但是月费仍然在预测波动中起着重要作用,而后者则无关紧要。原因是,月费是连续值,可以从数十、数百到数千不等,当乘以小coef (β =- 0.01)时,它就变得很重要了。另一方面,性别只能取值0或1,在两种情况下[exp(-0.01 * 0),exp(-0.01*1)]都是无关紧要的。
## We want to see the Survival curve at the customer level. Therefore, we have selected 6 customers (rows 5 till 9).
tr_rows = df_dummy.iloc[5:10, 2:]
tr_rows

## Lets predict the survival curve for the selected customers.
## Customers can be identified with the help of the number mentioned against each curve.
cph.predict_survival_function(tr_rows).plot()

上图显示了客户层面的生存曲线。它显示了5号、6号、7号、8号和9号顾客的生存曲线。
在客户层面创建生存曲线可以为时间线上不同的生存风险部分的高价值客户创建量身定制的策略。
6 总结
尽管,在生存分析中仍然有许多其他的东西需要了解,比如检查相称性假设,和模型选择;但是,只要对分析背后的数学有一个基本的理解,以及生存分析的基本实现(使用python中的lifelines库),在任何相关的业务用例中就都可以实现这个模型。
原文链接:https://towardsdatascience.com/survival-analysis-intuition-implementation-in-python-504fde4fcf8e
本文主要参考于:
知识分享 | 生存分析: 在 Python 中的实现(上篇)
知识分享 | 生存分析: 在 Python 中的实现(下篇)
相关笔记:
- Python相关实用技巧01:安装Python库超实用方法,轻松告别失败!
- Python相关实用技巧02:Python2和Python3的区别
- Python相关实用技巧03:14个对数据科学最有用的Python库
- Python相关实用技巧04:网络爬虫之Scrapy框架及案例分析
- Python相关实用技巧05:yield关键字的使用
- Scrapy爬虫小技巧01:轻松获取cookies
- Scrapy爬虫小技巧02:HTTP status code is not handled or not allowed的解决方法
- 数据分析学习总结笔记01:情感分析
- 数据分析学习总结笔记02:聚类分析及其R语言实现
- 数据分析学习总结笔记03:数据降维经典方法
- 数据分析学习总结笔记04:异常值处理
- 数据分析学习总结笔记05:缺失值分析及处理
- 数据分析学习总结笔记06:T检验的原理和步骤
- 数据分析学习总结笔记07:方差分析
- 数据分析学习总结笔记07:回归分析概述
- 数据分析学习总结笔记08:数据分类典型方法及其R语言实现
- 数据分析学习总结笔记09:文本分析
- 数据分析学习总结笔记10:网络分析
- 数据分析学习总结笔记11:空间自相关——空间位置与相近位置的指标测度
