引言:
今天我们学习逻辑回归。我们都知道线性回归模型是
,我们对他进行变形,得到
,这就是“对数线性回归”(logit linear regression),就是我们所说的逻辑回归。再变形
,一般地,把
形式,叫做广义线性模型。
一、数学原理
因为X是连续的,所以
的结果也是连续的,为了能做二分类问题,我们借鉴单位阶跃函数。如下图:
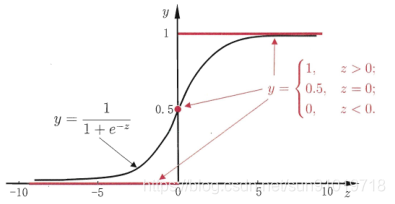
我们引入sigmoid 函数,逻辑回归形式是
。我们令y≥阈值,结果为正例,反之,为负例(阈值一般为1/2)。
注:逻辑回归借鉴了概率思维,但不是真正的概率,所以和贝叶斯算法有区别。
损失函数: ,我们在寻找最优的逻辑回归模型时,就是找到一组参数θ,使得损失函数J(θ)达到最小值。
二、代码实现
1、手工代码实现
实现过程:
①、定义sigmoid方法,使用sigmoid方法生成逻辑回归模型;
②、定义损失函数,并使用梯度下降法得到参数;
③、将参数代入到逻辑回归模型中,得到概率;
④、将概率转化为分类。
在这里插入代码片
2、sklearn实现
上一篇文章,我们学习了正则化,可以提高模型的泛化能力。sklearn的逻辑回归算法是直接加入正则化的,参数是penalty,默认是L2。另外新增一个超参数C。即损失函数形式是
参考文献:《机器学习 周志华著》第3章线性模型 3.2节、3.3节
参考文章:
https://mp.weixin.qq.com/s/xfteESh2bs1PTuO2q39tbQ
https://mp.weixin.qq.com/s/nZoDjhqYcS4w2uGDtD1HFQ
https://mp.weixin.qq.com/s/ex7PXW9ihr9fLOjlo3ks4w
https://mp.weixin.qq.com/s/97CA-3KlOofJGaw9ukVq1A
https://mp.weixin.qq.com/s/BUDdj4najgR0QAHhtu8X9A
