Lec 24 - Hashing
终于讲到了Hashing。早在leetcode第一题twoSum就见到了Hashing Table,但是一直不知道为什么它这么优秀,这次课终于学习了原理。
Data Index Arrays
我们上几次课实现的结构,最优只能实现O(log N)的查找复杂度。还能不能再快呢?
和之前的UnionFind类似,要用数组的Index代表存储的值,寻找某个值时,就只有O(1)的复杂度。(不过这样实现的是Set,无法存储顺序)

但是这样做还有很多优化的地方。首先,每次需要建一个特别庞大的数组。其次,只能存储数字。
English String Set
延续之前的思路,能否用Index代表字符串呢?
可以的!每个char都对应着一个ASCII码。再将每个char视作一位,以126进制就理论上可以表示任何字符串。
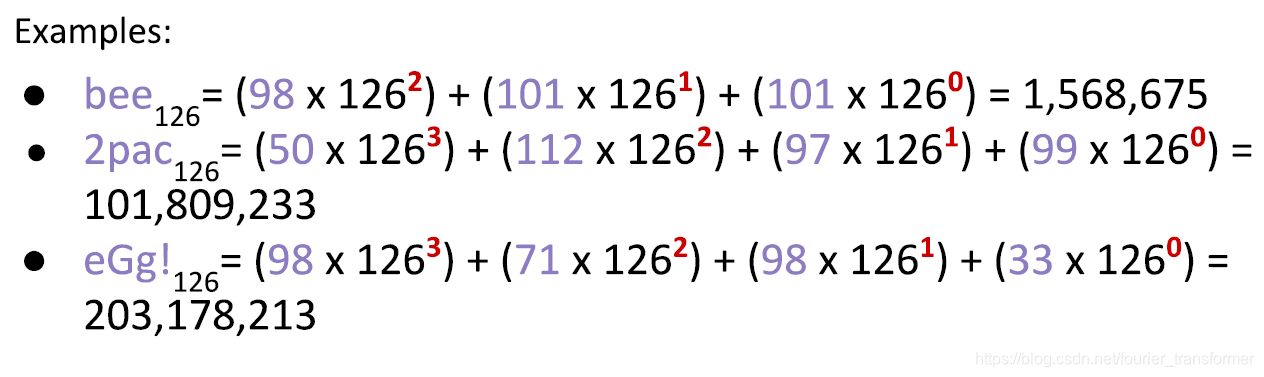
Integer Overflow and Hash Codes
现在需要考虑int类型溢出的问题。

比如上图中的例子,两个不同的字符串通过ASCII码126进制转化为整形,均超出了整形范围,就会发生溢出,变成同样的值,称之为Collision。
事实上,Collision是无法避免的,因为字符串的个数是无穷的,没有一种数据类型能穷尽所有,因此需要另外想解决办法。
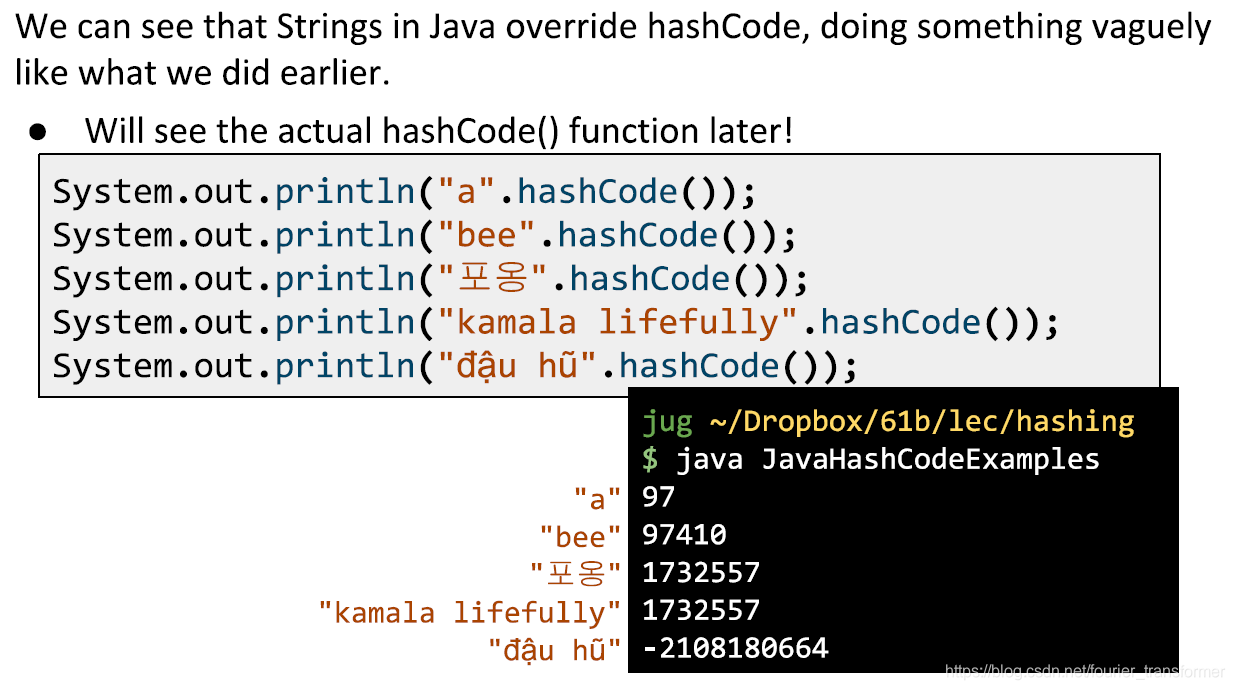
对于每个字符串,java有一套自己的转化方法,称之为Hash Code。
Hash Tables: Handling Collisions
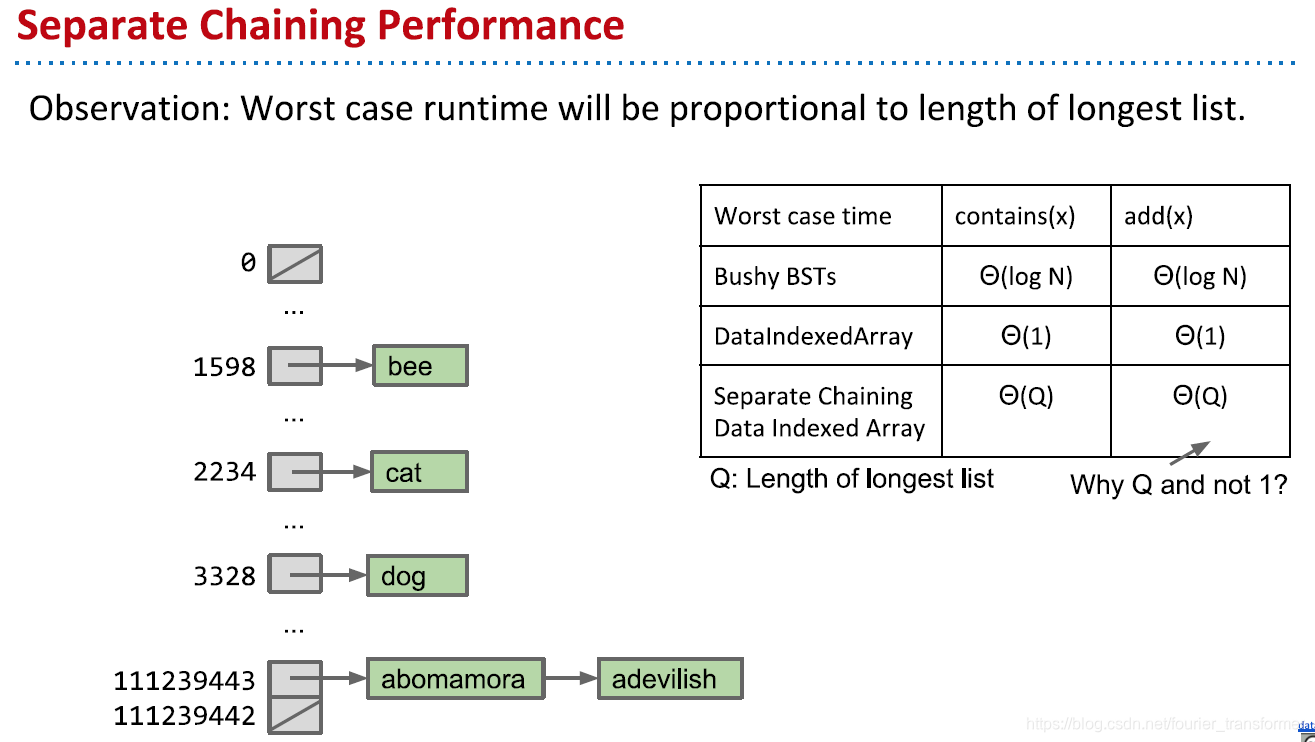
实际上,处理Collisions的方式是这样的:一个坑放很多值,也就是一个坑放一个list。

某x需要放到h位置,就是将x加入位于h的list中。比如上图例子,abomamora和abevilish的hash code都是111239444,那么该处就会有一个包含他们两个的list。
值得一提的是,查找或者插入操作,复杂度都为O(Q), Q为最长的list,并不是O(1)。这是因为必须遍历list,才能确定有无x或者需不需要插入x。
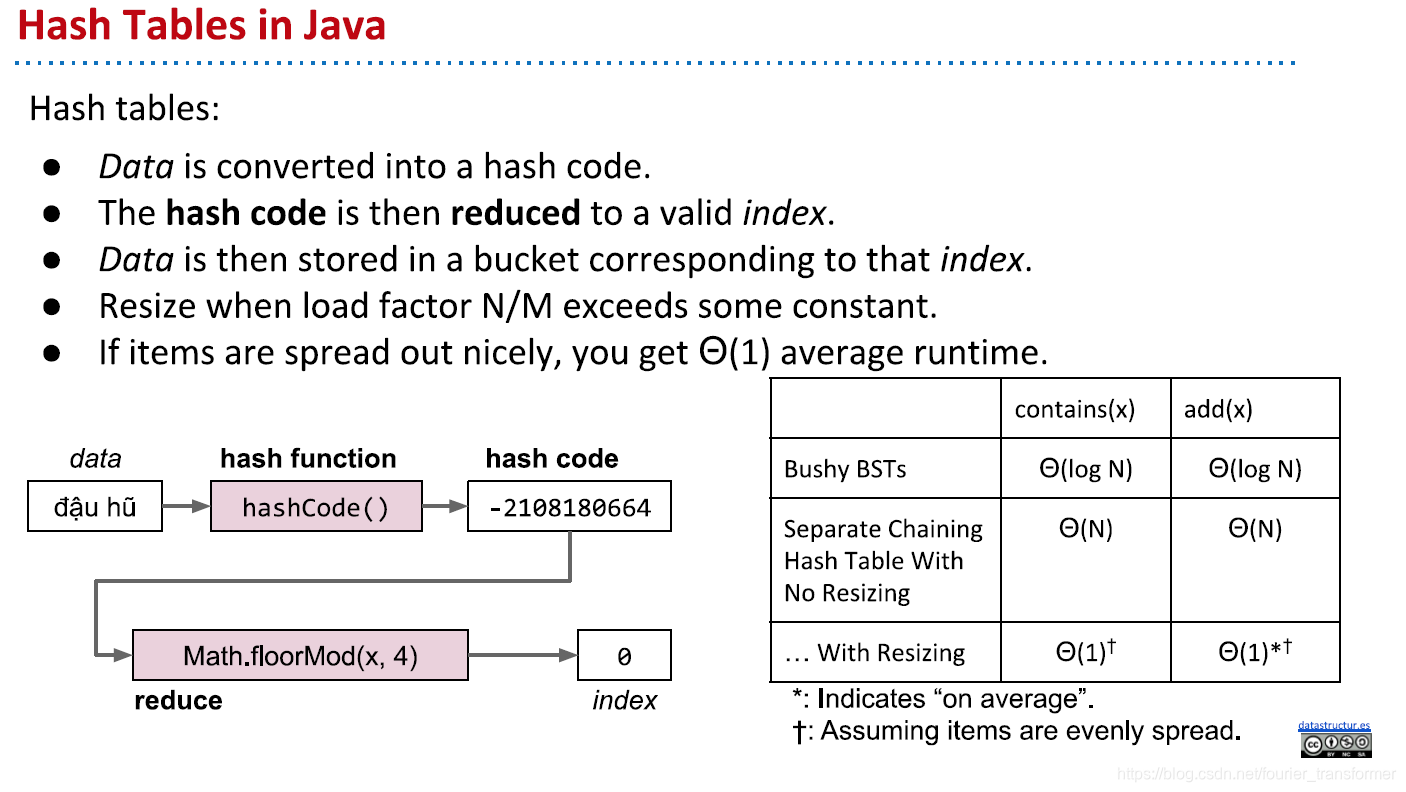
下面再优化一下另一个问题:开始新建的数组太大,占用内存空间。方法是取余,如下图,先新建一个大小为10的数组。一个字符串计算的Hash Code是2348762878,那么将它除以十取余,放到数组中,之后再插入字符串,按照上面的list方法操作。这就是Hash Table。
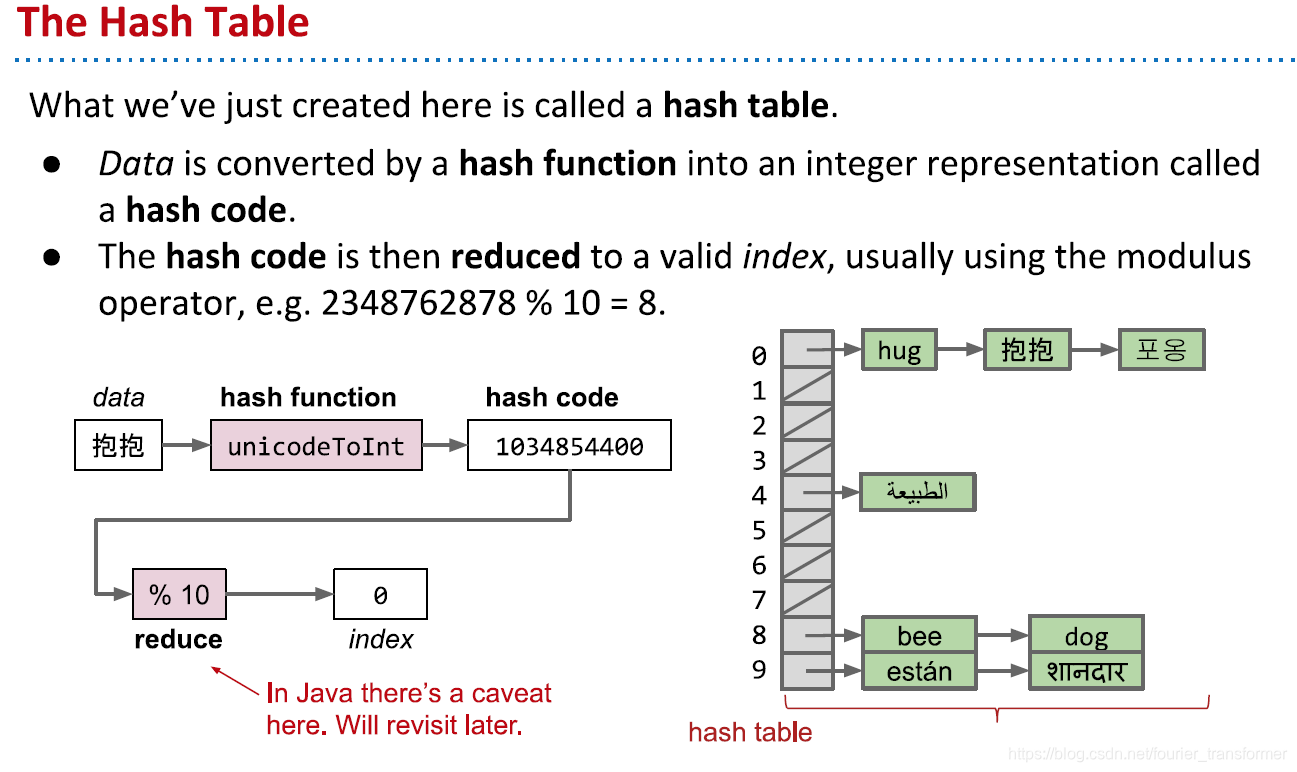
当然,这样会使list变得很长,明显需要resize。
Hash Table Performance

如图,如果初始的数组大小只有5,那么当加入N个数据时,Q最小是N/5, 最大是N,查找复杂度达到了O(N),这不是一个理想的复杂度。解决方法就是resize。
设定当前数组的长度是M,插入的数据数量为N,那么当N/M > 1.5时,将数组大小翻倍,变成2M。这样无论何时,N/M永远是一个常数,也就是达到了O(1)的最佳查找时间。注意是最佳状态,最坏情况仍然是O(N)。
值得注意的是,resize之后,所有的数据都要重新分配位置,因为每次是计算hash code - 除以M取余 - 放入指定位置这样的过程。M变化,数据的位置就会变,可见resize需要的操作不少。但是同ArrayList一样,即便加入resize,平均复杂度仍然是O(1),之后会有讨论。
Hash Tables in Java
上面提到,最佳的hash table的复杂度是O(1),但是最坏的情况下,即有一堆hash code相同的数据,复杂度仍然能达到O(N),因此hash code计算也是很重要的一环。下面看看java中实际是如何计算的。
我们之前学习过,Java中所有的类都继承了Object类,而Object类中就包含一个hashCode()方法。就是说,对所有的类,java都有一个相对应的hash code。

String类中Override了hashCode方法,很像之前提到的进制计算方法。
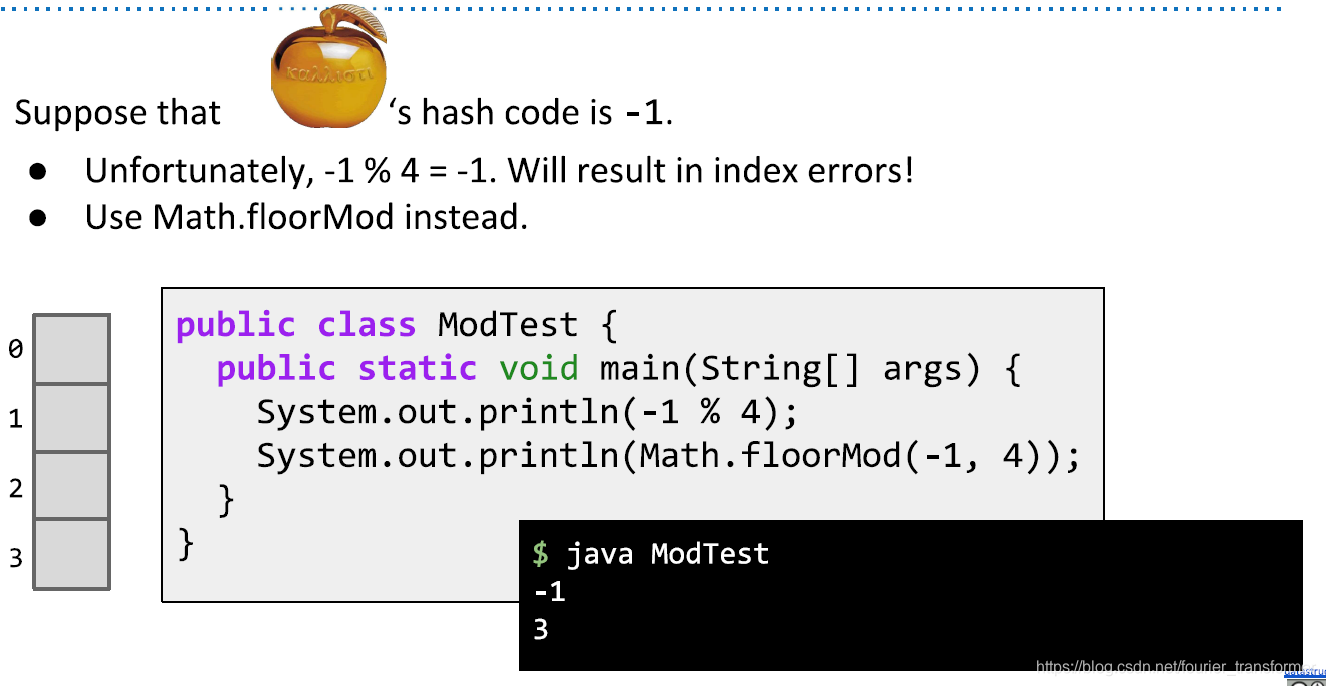
实际的hashCode方法中会计算出负数,为了增大范围,下面看一个问题。如果金苹果的hashCode是-1,那么把他放在0, 1, 2, 3哪个位置呢?

应该放在3,原因如上图。-1和0相邻,所以此时-1取余,会计算出-1,结果不对,此时应该取模,java中使用floorMod来实现的。

两点注意事项:
- 不要在HashSet和HashMap中存储可变的类。如果类中变量改变,则HashCode就变了,可能造成数据丢失
- 不要单独override equals方法,必须和hashCode方法一起override。
Java 8中String类的hashCode方法。有两点不同:
- 以31为模
- 用一个变量:cachedHashValue保存了计算所得的hashCode,作为缓存,再调用hashCode方法时,就不用重新计算一遍了。

为什么以31为模?答案是以126为模,虽然包括了全部的ASCII码,显得每个数据都是独立的,减少了数据的hash code重复的概率。然而,通过list以及resize方法,unique就不那么重要,以126为模造成的大量的数据溢出问题才是重点。溢出之后会产生大量相同的hash code,list长度很大,复杂度就升高了。因此,取一个小点的模效果会更好,更接近"randomness"。
并且,还要保证模是质数。(这个还要查查资料)

Summary
这节课内容还是挺多的。