在CNN(1)和CNN(2)两篇文章中,主要说明的是CNN的基本架构和权值共享(Weight Sharing),本文则重点介绍卷积的部分。
首先,在卷积之前,我们的数据是4D的tensor(width,height,channels,batch),在CNN(1):Architecture一文中,曾经提到过。这里的通道,和之前所说的depth是一个概念,例如一张Grey Scale Image,其通道数为1;RGB图的通道数为3。
而事实上,kernel也是有channel的,并且其数量与输入tensor的通道数一致。如下图的RGB图像,有3个通道,在卷积过程中我们使用5个kernel。
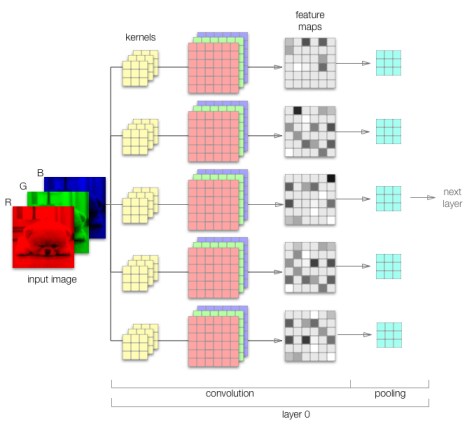
那么,到底有多少feature map?有很长一段时间,我的答案是15个feature map。但实际上,答案是5个(和kernel的数量一致)。如图示,Kernel也有3个通道,分别与RGB三个通道进行卷积后,生成了3个单通道卷积结果,而后三个结果相加得到feature map。而在此卷积层中,kernel是我们唯独需要“学习”的参数,也就是3*3*3*5=45个参数。实际上,通过训练kernel会学习到应该过滤图片中的哪些特征。