在进行本节实战之前,希望您对requests库以及正则表达式有所了解。
运行平台:windows
Python版本: Python3.x
一、依赖库的安装
在本节实战之前,请确保已经正确安装了requests库
requests库的安装
pip3 install requests如果您使用的是conda环境,可以选择使用以下安装方法
conda install requests二、抓取分析
猫眼电影TOP100的目标站点为http://maoyan.com/board/4?offset=0
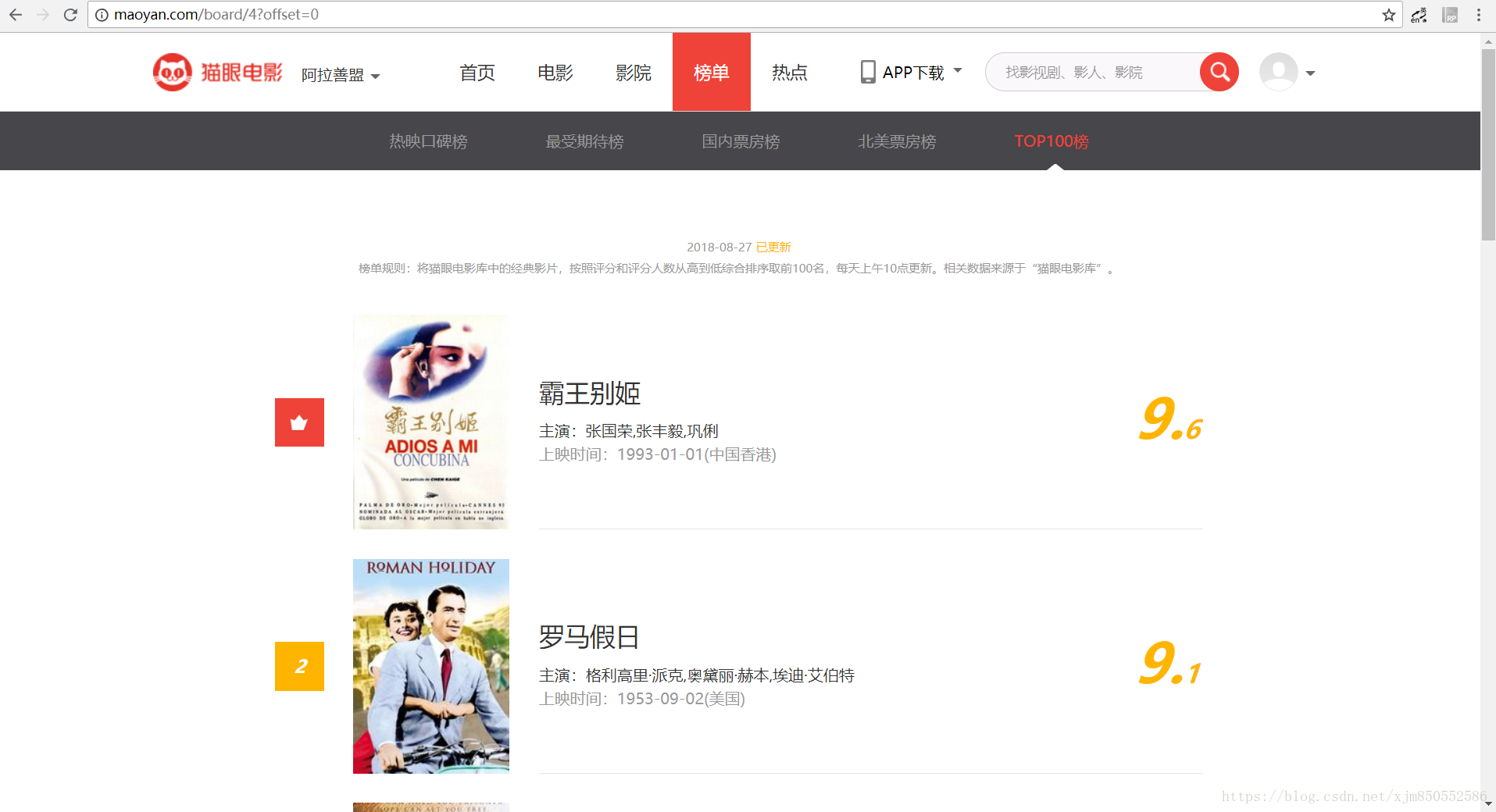
将网页滚动到最下方,点击第二页。
当网页跳转后,发现页面的URL发生如下变化
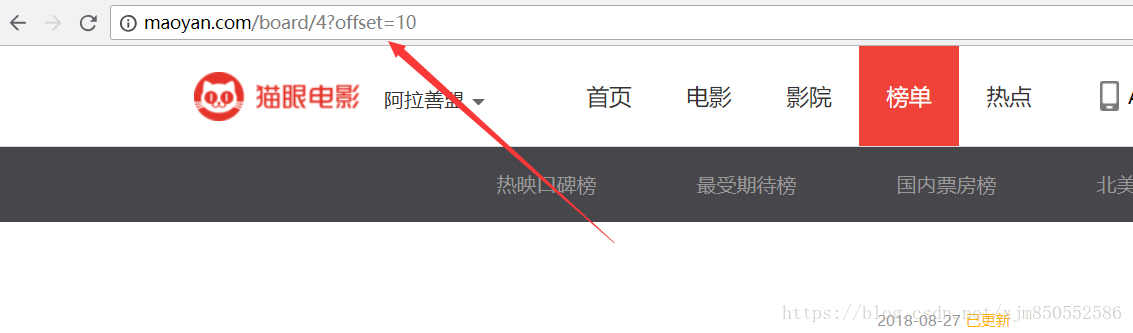
每一页显示的电影排名数目为10,而offset便代表着偏移量。
根据我们的推测,点击第三页后,网页URL中offset的值便会变成20,检验后没有问题。
因此,我们想获得TOP100的电影信息,只需要分开请求10次,而这10次的offset参数分别设置为0,10,20….90即可。这样获取不同的页面之后,利用正则表达式提取相关信息,即可爬取电影排行榜电影信息。
三、实战进行中
首先,我们引入我们需要的库文件
import requests
import re
import json
import time
from requests.exceptions import RequestException爬取首页
def get_one_page(url):
try:
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.62 Safari/537.36'}
response = requests.get(url,headers=headers)
if response.status_code == 200:
return response.text
return 0
except RequestExceptrion:
return 0添加headers报头进行爬虫伪装,利用requests.get函数发起请求
如果网页返回码为200(成功),则return response.text,返回页面源代码
我们来输出一下网页的源代码看以下
print(get_one_page('http://maoyan.com/board/4?offset=0'))运行后,如下图所示
说明我们爬取成功,接下来我们只需要从网页源代码里匹配我们需要的信息即可。
正则提取
【前提:了解贪婪匹配/非贪婪匹配】
利用开发者模式下的Network监听组件可以查看网页的真实源代码
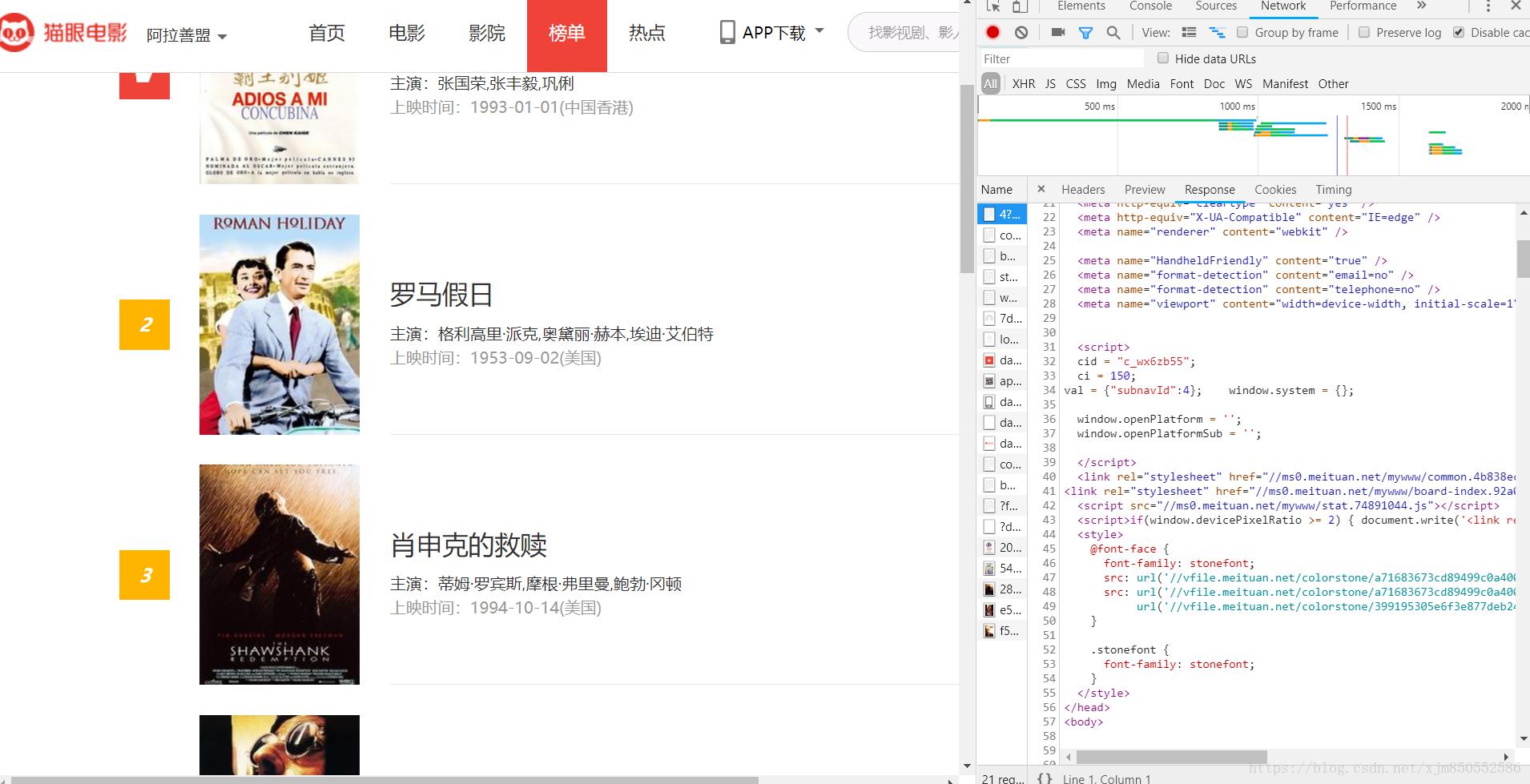
我们可以看到,一部电影对应的源代码便是一个dd节点,我们利用正则表达式来提取里面的电影信息。
正则表达式写法不唯一,只要能够提取到信息即可,在这里我主要使用的是.*?匹配方法。
举个例子:
<dd>.*?board-index.*?>(.*?)</i>()里的信息便是我们匹配的信息,在这里我们匹配了排名,同样的,电影名称、演员表等信息的匹配与之相同。
最后,正则表达式如下(不唯一,自己写比较方便):
<dd>.*?board-index.*?>(.*?)</i>.*?title="(.*?)".*?img data-src="(.*?)".*?<p class="star">(.*?)</p>.*?releasetime">(.*?)</p>.*?integer">(.*?)</i><i class="fraction">(\d+).*?</dd>在这里我们匹配了电影排名,电影名称,电影封面图,演员表,上映时间,评分。
compile()
在进行后续操作前,先简单讲解一下compile()方法,这个方法可以将正则字符串编译成正则表达式对象,以便在后续的匹配中复用。
因此,我们使用compile()方法编译对象:
pattern = re.compile(
'<dd>.*?board-index.*?>(.*?)</i>.*?title="(.*?)".*?img data-src="(.*?)".*?<p class="star">(.*?)</p>.*?releasetime">(.*?)</p>.*?integer">(.*?)</i><i class="fraction">(\d+).*?</dd>',re.S
)re.S是修饰符:使.匹配包括换行符在内的所有字符
因此解析页面的函数实现如下:
def parse_one_page(html):
pattern = re.compile(
'<dd>.*?board-index.*?>(.*?)</i>.*?title="(.*?)".*?img data-src="(.*?)".*?<p class="star">(.*?)</p>.*?releasetime">(.*?)</p>.*?integer">(.*?)</i><i class="fraction">(\d+).*?</dd>',re.S
)
items = re.findall(pattern,html)
print(items)此时,我们将代码合并,便是如下
import requests
import re
import json
import time
from requests.exceptions import RequestException
def get_one_page(url):
try:
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.62 Safari/537.36'}
response = requests.get(url,headers=headers)
if response.status_code == 200:
return response.text
return 0
except RequestExceptrion:
return 0
def parse_one_page(html):
pattern = re.compile(
'<dd>.*?board-index.*?>(.*?)</i>.*?title="(.*?)".*?img data-src="(.*?)".*?<p class="star">(.*?)</p>.*?releasetime">(.*?)</p>.*?integer">(.*?)</i><i class="fraction">(\d+).*?</dd>',re.S
)
items = re.findall(pattern,html)
print(items)
html = get_one_page('http://maoyan.com/board/4?offset=0')
parse_one_page(html)运行结果如下

可以看到,我们已经成功爬取了本页内电影的信息,但是数据比较杂乱,因此我们需要将匹配结果处理以下,遍历提取结果并生成字典。
此时parse_one_page函数改下如下:
def parse_one_page(html):
pattern = re.compile(
'<dd>.*?board-index.*?>(.*?)</i>.*?title="(.*?)".*?img data-src="(.*?)".*?<p class="star">(.*?)</p>.*?releasetime">(.*?)</p>.*?integer">(.*?)</i><i class="fraction">(\d+).*?</dd>',re.S
)
items = re.findall(pattern,html)
for item in items:
yield{
'index':item[0],
'title':item[1],
'image':item[2],
'actor':item[3].strip()[3:] if len(item[3]) > 3 else '',
'time':item[4].strip()[5:] if len(item[4]) > 5 else '',
'score':item[5].strip()+item[6].strip(),
}
输入以下代码运行
html = get_one_page('http://maoyan.com/board/4?offset=0')
for item in parse_one_page(html):
print(item)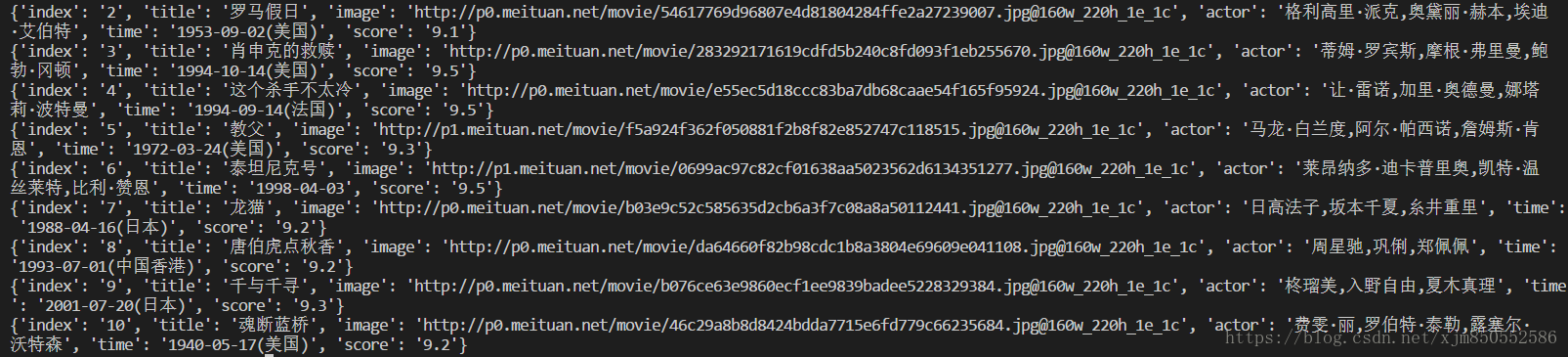
这样每个电影的信息便会成为一个个字典,形成结构化数据。
写入文件
写入文件我们分为txt写入和csv文件写入。
首先我们来讲txt文件写入。
txt
通过JSON库的dumps()方法实现字典的序列化,并指定ensure_ascii参数为FALSE,这样可以保证输出结果是中文形式而不是Unicode编码
def write_to_file(content):
with open('maoyanSpider.txt','a',encoding='utf-8')as f:
f.write(json.dumps(content,ensure_ascii=False)+'\n')csv
写入csv文件的话,我们还需要引入csv库。
import csv
def write_to_file(content):
with open('maoyanSpider.csv','a+',newline='')as csvfile:
writer = csv.writer(csvfile)
values = list(content.values())
writer.writerow(values)使用content.values()方法读取json数据,然后转换成列表。
接着使用writerow()将values数据一次一行的写入csv中
在open中newline=’ ‘是为了防止写入数据后多出空白行。
分页爬取
这也是爬虫的最后一步了,我们之前的操作都是爬取一个页面,而我们需要抓取的TOP100中含有10个页面,所以还需要遍历一下。
def spider(offset):
url = 'http://maoyan.com/board/4?offset='+str(offset)
html = get_one_page(url)
for item in parse_one_page(html):
write_to_file(item)
if __name__=='__main__':
for i in range(10):
spider(offset=10*i)
time.sleep(1)四、完整代码
爬取猫眼电影排行榜并存放于txt
import requests
import re
import json
import time
from requests.exceptions import RequestException
def get_one_page(url):
try:
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.62 Safari/537.36'}
response = requests.get(url,headers=headers)
if response.status_code == 200:
return response.text
return 0
except RequestExceptrion:
return 0
def spider(offset):
url = 'http://maoyan.com/board/4?offset='+str(offset)
html = get_one_page(url)
for item in parse_one_page(html):
print(item)
write_to_file(item)
def parse_one_page(html):
pattern = re.compile(
'<dd>.*?board-index.*?>(.*?)</i>.*?title="(.*?)".*?img data-src="(.*?)".*?<p class="star">(.*?)</p>.*?releasetime">(.*?)</p>.*?integer">(.*?)</i><i class="fraction">(\d+).*?</dd>',re.S
)
items = re.findall(pattern,html)
for item in items:
yield{
'index':item[0],
'title':item[1],
'image':item[2],
'actor':item[3].strip()[3:] if len(item[3]) > 3 else '',
'time':item[4].strip()[5:] if len(item[4]) > 5 else '',
'score':item[5].strip()+item[6].strip(),
}
def write_to_file(content):
with open('maoyanSpider.txt','a',encoding='utf-8')as f:
f.write(json.dumps(content,ensure_ascii=False)+'\n')
if __name__=='__main__':
for i in range(10):
spider(offset=10*i)
time.sleep(1)爬取猫眼电影排行榜并存放于csv
import requests
import re
import json
import time
from requests.exceptions import RequestException
import csv
def get_one_page(url):
try:
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.62 Safari/537.36'}
response = requests.get(url,headers=headers)
if response.status_code == 200:
return response.text
return 0
except RequestExceptrion:
return 0
def spider(offset):
url = 'http://maoyan.com/board/4?offset='+str(offset)
html = get_one_page(url)
for item in parse_one_page(html):
write_to_file(item)
def parse_one_page(html):
pattern = re.compile(
'<dd>.*?board-index.*?>(.*?)</i>.*?title="(.*?)".*?img data-src="(.*?)".*?<p class="star">(.*?)</p>.*?releasetime">(.*?)</p>.*?integer">(.*?)</i><i class="fraction">(\d+).*?</dd>',re.S
)
items = re.findall(pattern,html)
for item in items:
yield{
'index':item[0],
'title':item[1],
'image':item[2],
'actor':item[3].strip()[3:] if len(item[3]) > 3 else '',
'time':item[4].strip()[5:] if len(item[4]) > 5 else '',
'score':item[5].strip()+item[6].strip(),
}
def write_to_file(content):
with open('maoyanSpider.csv','a+',newline='')as csvfile:
writer = csv.writer(csvfile)
values = list(content.values())
writer.writerow(values)
if __name__=='__main__':
for i in range(10):
spider(offset=10*i)
time.sleep(1)