假设检验,又称统计假设检验,是用来判断样本与样本、样本与总体的差异是由抽样误差引起还是本质差别造成的统计推断方法。
显著性检验是假设检验中最常用的一种方法,也是一种最基本的统计推断形式,其基本原理是先对总体的特征做出某种假设,然后通过抽样研究的统计推理,对此假设应该被拒绝还是接受做出推断。常用的假设检验方法有Z检验、t检验、卡方检验、F检验等。
这里我们只学习Z检验和 t 检验。
目录
1、学习目标
- 熟知假设检验的概念及意义。
- 熟知检验假设的步骤,P-Value与显著性水平。
- 能够在Python中使用 t 检验进行数据分析。
2、假设检验
2.1、 假设检验概述
首先我们来看一个练习:
某车间用一台包装机包装葡萄糖。袋装糖的净重是一个随机变量,它服从正态分布。当机器正常时,其均值为0.5kg,标准差为0.015kg。某日开工后,为检验包装机是否正常,随机的抽样取它所包装的糖9袋,称得净重为(kg)
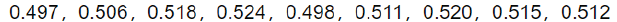
问机器是否正常?
import numpy as np
a = np.array([0.497,0.506,0.518,0.524,0.498,0.511,0.520,0.515,0.512])
a.mean()
结果:0.5112222222222224
我们计算的值大于机器正常的净重均值(0.5kg),因此,我们认为,此时机器是不正常的。请问这样认为正确吗?
答案是不正确的。因为机器的总体均值是0.5kg,而我们算的均值是样本的均值,我们不可以认为总体的均值不等于样本的均值就认为他是不正确的,因为抽样总会带来一定的误差。
首先我们要清楚,机器正常时的均值,是总体的均值,而我们统计的,只是总体中的一部分抽样(样本)而已。因此,我们一次抽样统计的均值,并不能代表总体的均值。
那我们这个时候应该怎么进行操作呢?
我们通过样本可以求出样本的均值进而来推断总体的均值它可能是多少,或者说它能够处在怎样的一个合理的区间之内。然后我们来推断这个合理的区间是否能够包含0.5kg,如果能把0.5kg包含进去,那么就意味着样本背后总体的均值可能就是0.5kg,但是如果我们通过样本算出来的均值没有包含在这个区间之内,也就意味着样本背后总体的均值就不是0.5kg。
我们可以使用区间进行验证:
a = np.array([0.497,0.506,0.518,0.524,0.498,0.511,0.520,0.515,0.512])
#总体的均值与标准差
mean,std = 0.5,0.015
#计算样本均值
sample_mean = a.mean()
#计算标准误差
se = std / np.sqrt(len(a))
#计算置信区间(95%置信度)
left,right = sample_mean - 1.96 * se,sample_mean + 1.96 * se
print(f"置信区间:({left:.3f},{right:.3f})")
代码解析:
.3f 的意思是保留位小数,这里计算不明白的可以点击这里进行学习。
结果:
置信区间:(0.501,0.521)
结果意味着,总体均值有95%的可能是会在区间(0.501,0.521)之内的。
但是根据题目可知当机器正常时,其均值为0.5kg。0.5不在这个(0.501,0.521)之内,我们通过可视化查看下:
import matplotlib.pylab as plt
plt.rcParams["font.family"] = "SimHei"
plt.rcParams["axes.unicode_minus"] = False
plt.plot(mean,0,marker="*",color="orange",ms=15,label="总体均值")
plt.plot(sample_mean,0,marker="o",color="r",label="样本均值")
plt.hlines(0,xmin=left,xmax=right,colors="b",label="置信区间")
plt.axhline(left,0.4,0.6,color="r",ls="--",label="左边界")
plt.axhline(right,0.4,0.6,color="g",ls="--",label="右边界")
plt.legend()

通过可视化结果我们可以看到,总体均值在95%置信度的置信区间(0.501,0.521)之外了,说明我们样本背后总体的均值不是机器正常的均值,因为没有将样本背后总体的均值包含进区间内。
我们可以得出什么结论呢?
总体的均值不在置信区间中,当前机器有95%的概率运作不正常。
中心极限定理中我们说过,只有在样本容量n足够大的时候才会服从正态分布,但是上面的这个例子样本容量n=9,9<30,那这个时候它还能服从正态分布吗?
答案是可以。为什么呢?
因为对于例子中的总体来说,它本身就是正态分布的。所以说在中心极限定理中:
补充说明:
(1)当总体服从正态分布时,样本容量很小时进行无数次抽样也可以形成正态分布,所以样本容量小也没关系;
(2)在不知道总体是什么分布或者不是正态分布时,必须满足样本容量n>=30,这时候我们进行无数次抽样得到的样本均值才能够服从正态分布。
现在我们换一种思路去解决。那就是,我们假设机器是运行正常的,然后在这个假设下去进行推断,会得到怎样的结论呢?这就是我们本篇博客要学习的假设检验内容。
2.1.1、 假设检验概念
假设检验:
也称为显著性检验,是通过样本得到统计量,来判断与总体参数之间是否存在差异(差异是否显著)。即我们对总体参数进行一定的假设,然后通过收集到的数据,来验证我们之前作出的假设(总体参数)是否合理。在假设检验中,我们会建立两个完全对立的假设,分别为原假设(零假设)H0与备择假设(对立假设)H1。然后根据样本信息信心分析判断,是否接受(维持)原假设还是拒绝原假设(接受备择假设)。
假设检验基于“反证法”。首先,我们会假设原假设为真,如果在此基础上,得出了违反逻辑与常理的结论,则表明原假设是错误的,我们就接受备择假设。否则,我们就没有充分的理由推翻原假设,此时,我们选择去维持原假设。
例如,在上面的例子中,我们可以建立两个假设,原假设为机器运行正常,备择假设为机器运行不正常。然后假设原假设为真,并以此为依据进行推导,如果产生不正常的结论,就拒绝原假设,即认为机器运作不正常。反之,如果没有产生不正常的结论,则接受原假设,即认为机器运作是正常的。
2.1.2、 小概率事件
什么是小概率事件?
小概率事件是一个事件的发生概率很小,那么它在一次试验中是几乎不可能发生的,但在多次重复试验中是必然发生的。
在概率论中我们把概率很接近于0(即在大量重复试验中出现的频率非常低)的事件称为小概率事件。
在假设检验中,违反逻辑与常规的结论,就是小概率事件。我们认为,小概率事件在一次试验中是不会发生的。一旦小概率事件发生,则我们就有理由拒绝原假设。
假设检验遵循“疑罪无从”的原则,接受原假设,并不代表假设一定是正确的,只是我们没有充分的证据,去证明原假设是错误的,因此只能维持原假设。
2.1.3、 P-Value与显著性水平
为了便于量化,我们可以计算一个概率值(P-Value),该概率值可以认为就是支持原假设的概率。
因为在假设检验中,通常假设为等值假设,因此,P-Value也就是表示样本统计量与总体参数无差异的概率。然后,我们预先设定一个阈值,这个阈值就是显著性水平(使用α表示),通常α的取值为0.05(1-α 为置信度)。当P-Value的值大于α时,支持原假设,否则,拒绝原假设。
P > 0.05 支持原假设,拒绝备择假设。
P < 0.05 支持备择假设,拒绝原假设。
假设检验与置信区间具有一定的关联性,只不过置信区间是通过正面的方式,来计算总体参数可能得到值(区间),而假设检验就是从反证的角度来判断,是接收原假设还是拒绝原假设。
2.2、 假设检验的步骤
假设检验的步骤:

2.3、常用假设检验
2.3.1、Z检验
Z检验用来判断样本均值是否与总体均值具有显著性差异。
Z检验是通过正态分布的理论来判断差异发生的概率,从而比较两个均值的差异是否显著。
Z检验适用于:
- 总体呈正态分布。
- 总体方差已知。
- 样本容量较大(一般>=30)
Z统计量计算方式如下:


查看Z的偏移程度是否在 -1.96 < Z > 1.96 倍的标准差之内,即判断是在接收域内还是在拒绝域内。
如果超过1.96倍的标准差,我们就可以判定它是小概率事件发生了,我们就可以拒绝原假设。
我们通过假设检验来求解上面的机器运作事例:

from scipy import stats
a = np.array([0.497,0.506,0.518,0.524,0.498,0.511,0.520,0.515,0.512])
#总体的均值与标准差
mean,std = 0.5,0.015
#计算样本均值
sample_mean = a.mean()
#计算标准误差
se = std / np.sqrt(len(a))
#计算Z统计量(样本均值-假设总体的均值)
Z = (sample_mean - mean) / se
print("统计量Z:",Z)
#计算P值
P = 2 * stats.norm.sf(abs(Z))
print("P-Value的值:",P)
代码解析:
P = 2 * stats.norm.sf(abs(Z)) 中的stats.norm是正态分布,sf括号里的值就是统计量,偏移均值几倍的标准差,及两边围成的面积。
abc 取绝对值。

结果:
统计量Z: 2.244444444444471
P-Value的值: 0.02480381963225589
从结果可以看出统计量Z的值大于1.96倍的标准差,超过置信区间,这种情况下就落在了拒绝域中(1-95%的范围),这个时候我们假设的总体均值就不可靠了,所以我们就拒绝原假设,支持备择假设,即机器运作是不正常的。

由结果可知,Z值偏离超过了2倍的标准差,P值也就是小于0.05。因此,在显著性水平α =0.05下,P<αloha,故我们拒绝原假设,接受备择假设,即我们认为机器运作是不正常。
2.3.2、t 检验
t 检验与Z检验类似,用来判断样本均值是否与总体均值具有显著性差异。不过,t 检验是基于t 分布的。
t 检验适用于:

不过,随着样本容量的增大(样本容量达到30以上时),t 分布逐渐接近于正态分布。此时,t检验也就近似应用于Z检验。

t 统计量计算方式如下:

我们通过一个事例来了解一下t分布:
鸢尾花的平均花瓣长度是3.5cm,请问,这种说法正确吗?

具假设检验的步骤,进行解决:
1、设置原假设与备择假设。
- 原假设:μ = μ0 = 3.5cm(设总体均值即假设总体均值为3.5cm)
- 备择假设:μ != μ0 != 3.5cm
2、设置显著性水平。
- 设置α = 0.05
3、根据问题选择假设检验的方式。
- 鸢尾花呈现正态分布,总体标准差未知,选择t 检验。
4、计算统计量,并通过统计量获取P值。
5、根据P值与α值,决定接受原假设还是备择假设。
import pandas as pd
from sklearn.datasets import load_iris
iris = load_iris()
data = pd.DataFrame(iris.data,columns=["sepal_length", "sepal_width", "petal_length", "petal_width"])
#计算样本均值
mean = data['petal_length'].mean()
#计算样本标准差
std = data["petal_length"].std()
print("样本均值:",mean)
print("样本标准差:",std)
#计算t 统计量
t = (mean - 3.5)/(std/np.sqrt(len(data)))
print("t 统计量:",t)
#计算P值
#df:自由度,即变量可以自由取值的个数
P = 2 * stats.t.sf(abs(t),df = len(data["petal_length"])-1)
print("P-Value值:",P)
结果:
样本均值: 3.7580000000000027
样本标准差: 1.7652982332594667
t 统计量: 1.7899761687043467
P-Value值: 0.07548856490783468
自由度是指变量可以自由取值的度数。样本容量减一(n-1)
通过结果我们可以得出的结论是:
在α = 0.05下,没有充分理由证明鸢尾花的平均花瓣长度不是3.5cm。
我们也可以通过scipy提供的相关方法来进行 t 检验的计算,无需自行计算。
stats.ttest_1samp(data["petal_length"],3.5)
结果:
Ttest_1sampResult(statistic=1.7899761687043318, pvalue=0.07548856490783705)
t 统计量和P值与上面计算的一致(忽略小数存储的误差)。
t 检验与Z检验的区别:

2.4、 双边检验与单边检验
2.4.1、概念



2.4.2、右边假设检验
假如现在我们换一种说法:
鸢尾花的平均花瓣长度不超过3.5cm。(<=3.5cm)
这就是一个右边假设的问题。

import pandas as pd
from sklearn.datasets import load_iris
iris = load_iris()
data = pd.DataFrame(iris.data,columns=["sepal_length", "sepal_width", "petal_length", "petal_width"])
#计算样本均值
mean = data['petal_length'].mean()
#计算样本标准差
std = data["petal_length"].std()
#计算t 统计量
t = (mean - 3.5)/(std/np.sqrt(len(data)))
print("t统计量:",t)
#计算P值
P = stats.t.sf(t,df = len(data["petal_length"])-1)
print("P-Value值:",P)
结果:
t统计量: 1.7899761687043467
P-Value值: 0.03774428245391734

从结果可知:P<α,因此拒绝原假设,即鸢尾花的平均花瓣长度超过3.5cm。
2.4.3、 左边假设检验
我们再换种说法:
鸢尾花的平均花瓣长度不小于3.5cm。(>=3.5cm)
那么这就是一个左边假设的问题:

import pandas as pd
from sklearn.datasets import load_iris
iris = load_iris()
data = pd.DataFrame(iris.data,columns=["sepal_length", "sepal_width", "petal_length", "petal_width"])
#计算样本均值
mean = data['petal_length'].mean()
#计算样本标准差
std = data["petal_length"].std()
#计算t 统计量
t = (mean - 3.5)/(std/np.sqrt(len(data)))
print("t统计量:",t)
#计算P值
P = stats.t.cdf(t,df = len(data["petal_length"])-1)
print("P-Value值:",P)
结果:
t统计量: 1.7899761687043467
P-Value值: 0.9622557175460826

从结果可知:P>α,因此维持原假设,即鸢尾花平均花瓣长度不小于3.5cm是正确的。
3、 总结
- 假设检验的概念与应用
- 假设检验的步骤
- 双边检验与单边检验
