水下目标检测算法赛方法总结与思路分享

我们团队在此分享下在 “2020年全国水下机器人(湛江)大赛 - 水下目标检测算法赛” 这一比赛中的实验过程及心得体会。不足之处,还望批评指正。
一、大赛简介
**「背景」**随着海洋观测的快速发展,水下物体检测在海军沿海防御任务以及渔业、水产养殖等海洋经济中发挥着越来越重要的作用,而水下图像是海洋信息的重要载体,本次比赛希望参赛者在真实海底图片数据中通过算法检测出不同海产品(海参、海胆、扇贝、海星)的位置。
 图1:训练数据集展示图
图1:训练数据集展示图
**「数据」**训练集是5543张 jpg 格式的水下光学图像与对应标注结果,A榜测试集800张,B榜测试集1200张。
**「评估指标」**mAP(mean Average Precision)
注:数据由鹏城实验室提供。
*以上内容均引用于比赛官网 [1]
二、比赛成员
团队(队伍名:想测水深)共三人:
-
李智敏:华中科技大学 研一
-
罗文斌:电子科技大学 研一
-
艾宏峰:曼彻斯特大学 应届研究生
*特别感谢南京会否网络科技有限公司提供硬件上的支持
三、比赛
**「时间」**2020.2.28 - 2020.4.11
**「配置」**AWS 四张16G Tesla T4显卡
**「排名」**30(A榜) / 31(B榜), 共1.3k支队伍。
1. 数据研究及处理
深度学习中,数据往往决定了性能的上限,算法只是不断地逼近上限。从官网下载数据后,首先对数据进行预处理,将xml文件转换为较为熟悉的coco的数据结构,常用pycocotools,mmcv,安装只需要pip install mmcv,可以方便操作json文件,同时还有部分封装更高层的图像处理算法。
(1) 统计标签类别

图2:标签类别
(2) 统计图像分辨率

图3:图片分辨率
图像呈多尺度分布,后续训练测试过程中,拟采用多尺度训练测试。
(3) 统计目标长宽比
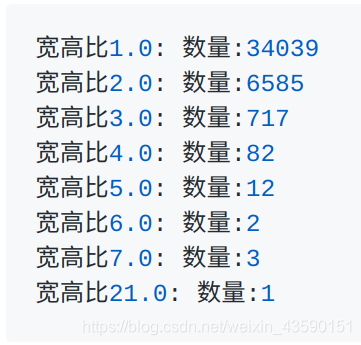
图4:目标长宽比
基于anchor的目标检测任务,需要分析目标长宽比,以选择最优的anchor比例。在考虑计算消耗的前提下,尽可能扩大感受野,保证anchor的分布尽可能与目标分布保持一致。所以最初我们选择anchor的ratio为[0.2,0.5,1,2,5]。
(3) 统计目标大小
应统计不同分辨率下目标与图像的面积比,再用训练测试使用的resize大小,推算出目标大小分布。以此选择具有最优感受野的模型。
(4) 训练集验证集划分
以0.85:0.15比例划分训练集测试集,常采用分层抽样,即根据标注类别保持标注类别比例抽样,但该任务数据集为多组视频段落的序列帧,分布呈连续性,相邻帧有较大的相似性,如果使用分层抽样,可能导致背景、目标分布不平衡,导致训练集与验证集分布有较大的gap。故采用固定间隔抽样,抽样后再次统计标注信息类别比例,大小分布,训练集与验证集分布相似,达到划分目的。
2. 模型
模型上,我们是基于@郑烨(选手名:斩风) 开源的baseline配置进行修改的,用的是mmdetection代码库中的Cascade R-CNN模型 [2],其中backbone是ResNeXt101-64x4d (64是基数Cardinality,X101的一个block的group数量。而4d是指bottleneck的宽度)。模型同时也搭配了FPN[3],增强模型对小目标的检测能力。
如下图所示,Cascade R-CNN模型其实就是传统Faster R-CNN模型的基础上用了三个不同IoU (0.5/0.6/0.7) 的heads。
图5:Cascade R-CNN结构示意图
在论文 [2] 中提到,一般正常的检测器是用0.5的IOU阈值(用于提出正负样本)训练,但如果提高IOU阈值会降低检测器的表现。这有两个原因:(1)当训练时,高IOU阈值会减少提出的正样本,引发exponentially vanishing positive samples问题,使得模型过拟合。(2)在inference阶段,输入的IOU与输出的IOU不匹配也会导致精度的下降。注:其中的输入IOU是RPN输出proposal的IOU(控制正负样本),输出IOU是proposal经过bbox classification时的IOU(判断是否为正例)。而Cascade R-CNN先用iou=0.5训练RPN,然后再级联不同的检测器(IOU=0.5,0,6,0.7),H1预测结果框将被输入给下一个H2进行训练,依次后推此过程。再输入给下一个检测器前,输出结果会被normalization(即减去平均值再除方差),这样就能保证不同阶段下的目标框分布能保持稳定的一致性。从小IOU到大IOU避免了过拟合,而且normalization使得输入IOU与输出IOU有个较好的匹配。,所以它能产生更高的精度,很多选手也喜欢用它。
3. 实验设置
首先我们先整理了选手开源的baseline配置如下:
图6:郑烨选手开源的baseline配置
该baseline主要有下面几个特点:
- 训练和测试多尺度:增强模型鲁棒性,同时小图被放大后能利于被模型捕捉到。
- Soft NMS:对重叠目标的检测更加友好。
- HTC [4] 预训练模型权重:mAP高的预训练模型对于后续模型收敛有很好的帮助,同时好的预训练模型也能增加模型的鲁棒性,HTC预训练模型权重是在COCO和COCO-stuff数据集上完成,而且还使用了multi-scale进行训练,所以它是个很好的提分点。
此外,我们基于上面的baseline,进行了以下几点改进:
- 扩大短边上限:在mmdetection论文 [5] 中,作者有提到,在设置训练多尺度时,提高短边上限能带来提升,我们将原短边上限1000,提高到1400。同样地,测试尺度也相应变更为[(4096, 600), (4096, 1000), (4096, 1400)],模型有提升。这里设长边为4096,是为了放开Resize对长边的依赖,这样尺度的变化完全都是由短边进行控制的,尺度变化更加和谐些。具体的计算方法如图7所示:
图7:Resize完全依赖短边下,对长边下限的计算过程(这里只要长边大于2493就可以了)
- 放大学习率:我们是单gpu输入单张图片,四个GPU下的学习率应为0.005(计算过程见图8),但我们使用了0.01。
图8:学习率计算方法(0.00125是单卡单图输入下的基础学习率)
-
使用Albumentations数据增强:我们尝试了几个Albu手段,最有用的是:CLANE,IAASharpen, IAAAEmboss和RandomBrightnessContrast。
-
CLAHE(对比度受限的自适应直方图均衡):自适应直方图均衡化(AHE)用来提升图像的对比度的一种计算机图像处理技术。和普通的直方图均衡算法不同,AHE算法通过计算图像的局部直方图,然后重新分布亮度来改变图像对比度。因此,该算法更适合于改进图像的局部对比度以及获得更多的图像细节。AHE有过度放大图像中相同区域的噪音的问题,另外一种自适应的直方图均衡算法即限制对比度直方图均衡(CLAHE)算法,它能有限的限制这种不利的放大。
图9:CLAHE处理前后图
- IAASharpen:基于形态学的一种数据增强,图像锐化主要影响图像中的低频分量,不影响图像中的高频分量。图像锐化的主要目的有两个:(1)增强图像边缘,使模糊的图像变得更加清晰,颜色变得鲜明突出,图像的质量有所改善,产生更适合人眼观察和识别的图像;(2)希望通过锐化处理后,目标物体的边缘鲜明,以便于提取目标的边缘、对图像进行分割、目标区域识别、区域形状提取等,进一步的图像理解与分析奠定基础。IAASharpen锐化输入图像,并将结果与原始图像重叠。不仅保留了原有细节且使边缘更加鲜明。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-xHTPkwlb-1586779715366)(data:image/gif;base64,iVBORw0KGgoAAAANSUhEUgAAAAEAAAABCAYAAAAfFcSJAAAADUlEQVQImWNgYGBgAAAABQABh6FO1AAAAABJRU5ErkJggg==)]
图10:IAASharpen处理前后图
- IAAEmboss:基于形态学的一种数据增强,压印输入图像,并将结果与原始图像重叠。对图像执行某一程度浮雕操作,通过某一通道将结果与图像融合。其目的和锐化融合一个道理也是一种不错的数据增强的方法。
图11:IAAAEmboss处理前后图
- RandomBrightnessContrast:随机光照强度及对比度增强,这是一种将光照和对比度增强的方法融合到一起的方法,通过对比度和光照强度的一定范围内的随机改变增加图片的多样性,提高模型的泛化能力。
图12:RandomBrightnessContrast处理前后图
- 训练加入海草标注:由于在去海草数据集训练后,发现数据集中的海草常会被认为海胆(黑圆团海草)和海参(波浪边缘的条状海草),所以为了增加模型在海草和其他目标海产上的区分能力,把数据集中82个海草标注加入进行训练,最后预测结果对海草进行剔除即可。该方法给模型带来很大的提升,但由于原本数据集海草标注本身没有认真标注,这里带来的提升也可能是因为多了一个类别后,缓解了模型过拟合,增加了模型通用性。
四、尝试与想法
1. Libra R-CNN
由于数据集存在类别不平衡问题,而且在样本层的不平衡问题上,OHEM对噪声标签敏感且计算昂贵(我们数据就噪声标签)。Focal loss对单阶段模型有利,而双阶段模型由于常提出easy negatives,而使Focal loss在二阶模型上面没有提升。所以我们更好的解决类别不平衡问题,将Libra R-CNN [6] 中的IOU-balanced sampling,Balanced feature pyramid和Balanced L1 loss加入到模型中去,即使验证集上表现有所提升,但提交结果并不好,可能噪声数据被IOU-balanced sampling中hard negative samples多少还是放大了一些。
图13:Lirbra R-CNN三个主要构件(三种分别应对样本层,特征层和目标层上不平衡问题的方法)
2. 边缘检测
在之前数据研究发现,存在部分目标在图像边缘,因此为了加强对边缘附近的目标检测,将mmdetection模型配置文件修改allowed_border=-1(即指超过图片边界的anchor将不会被忽略),验证集有提高,但提交成绩没有提升,猜想原因是训练大尺度下,边缘目标也能很好的检测到,不需要额外放开限制。
3. 数据增强
我们主要做的数据增强工作如下:
- Mixup
- 实例平衡增强
- 模糊(Median Blur和 Motion Blur)
- Retinex
- 泊松融合
- 标签平滑
(1) Mixup
mixup [7] 将两张图像按照一定的比例混合在一起,对数据集进行增强,是常用的trick。在初期的实验中,使用了mixup,线上测评降低0.0003。
图14:Mixup [7]
(2) 实例平衡增强
由于原数据集存在类别不平衡问题(实例数量:海参4574,海胆18676,扇贝5554和海星5704),所以打算使用阿里之前提出的一个实例平衡增强方法 [8] 去增强数据解决不平衡问题,如图15,首先先把原图放大1.5倍,然后用原图原始尺寸大小作为滑窗大小,以滑窗形式水平平均地移动三次,垂直平均地移动三次,最后1张图会得到9张相当于shift和scale后的增强图片。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-taGgFDjY-1586779715369)(data:image/gif;base64,iVBORw0KGgoAAAANSUhEUgAAAAEAAAABCAYAAAAfFcSJAAAADUlEQVQImWNgYGBgAAAABQABh6FO1AAAAABJRU5ErkJggg==)]
图15:实例平衡增强示意图
在滑动中发现如果不对滑动窗口做限制,会加重类别不平衡,因为海胆数量太多,且滑动结果会有很多单张只有一个扇贝的情况从而导致扇贝很多。因此对滑动窗口进行限制:滑动窗口内含海胆就不要该窗口,滑动窗口内仅有一个扇贝的不要。最后增强数据和原数据合并后的实例数量是:海参13016,海胆18676,扇贝13287和海星12322。虽然类别平衡许多了且该增强模仿了水下手持拍摄设备从远到近的拍摄过程,但结果反而下降,原因是单纯的实例平衡增强其实有点像重复数据集操作,这一点在‘第一个epoch下验证集比之前实验都高,在第9个epoch验证集表现最好’能反映出来,但是图片并没有很大的变化,最多是解决了模型平移不变性的问题。阿里其实后面还对这些增强图片还加入了一种自动并行增强(Auto Affine Augmentation)方法,即旋转边界框,白平衡,按照x轴或y轴截断等,可能也因为我们没加多余的图片增强技术使得增强后的数据集还是过于单调了些。
(3) 模糊(Median Blur和 Motion Blur)
最先考虑使用中值模糊,是因为观察到图片有些本身就模糊,但没有带来明显提升(中值模糊,发生概率p=0.1,可能是模糊概率太小了)。后面又因为发现数据是视频拍摄某些连续帧下取得,因此拍摄设备的水下移动带来了动态模糊,为了模型在这种数据下获得更好的鲁棒性,在mmdet/datasets/pipelines下的transforms.py和__init__.py下添加了MotionBlur的数据增强手段。在我们实验中,动态模糊充分考虑到不同尺寸的数据集原图而单独赋予不同的模糊核大小(因为尺寸大的图像需要更大的模糊核大小):
-
w<=750, 核大小为10-20;
-
750<w<2000,核大小为20-60;
-
w>=2000, 核大小为100-140。
图16:中值模糊
图17:动态模糊
在验证集上,实验在海参和海星上有所提高,但是海胆和扇贝反而下降,这个可能涉及到不同海产在这种画面模糊的在分布情况不一致,原因也暂不明晰。而且发现动态模糊发生概率越大,验证集表现越差,虽然当时发生概率设置为0.3而不是常见的0.5,但最后提交分数反而下降。
(4) Retinex
之前做的目标检测任务通常在可见光下,本次任务为水下检测,水下成像的背景通常为蓝色或绿色。故水下图像要进行复原,修正图像色度,提升图像对比度,使图像拥有更加醒目的视觉效果,更加明显的图像细节。
图18:水下图像复原(图像来源:中国科学院光电技术研究所)
这里使用retinex算法进行图像增强,常用的有SSR(Singe Scale Retinex)、MSR、MSRCR。
SSR(Singe Scale Retinex):
简单来说,该算法认为成像器的成像通常是由入射光作用于反射物体的入射成像和反射物体的反射成像,入射成像直接决定了图像中像素所能达到的动态范围,而反射成像表示物体的反射性质图像,是图像的内在属性。Retinex就是通过某种方法,去除或者降低入射图像的影响,进而保留物体本质的反射属性成像。
该算法假设初始光照图像是缓慢变化的(即低频的,用低通滤波可得光照分量),光照图像是平滑的。入射成像可以看作图像的低频成分,使用高斯低通滤波器作用于成像图像,来模拟入射图像,再用成像图像减去入射图像,就可以得到表明图像内在属性的反射成像。
由于SSR函数中所选用的高斯函数特点,所以增强后的图像对动态范围大幅度压缩和对比度增强不能同时保证。其实就是高斯核函数的sigma常量的取值,与高斯核大小对成像有较大的影响:
- 不同的高斯kernel对图像的影响。sigma = 300,使用GIMP的MSRCR算法,单尺度,Dynamic = 2。
- 高斯模糊在这里主要起到模拟光照成像,认为光照的成像是稳定的,变化是缓慢的,是低频的,对应背景和轮廓。所以用低通滤波器。
- sigma确定时,kernel的size越小,生成的入射成像越清晰,频带更宽,通过了部分高频,原图-生成的图(滤掉少量的高频) =得到的就是滤过的少量的高频细节和噪声,相当于高通。
- sigma确定时,kernel的size越大,生成的入射成像越模糊,频带更窄,阻碍了高频,原图-生成的图(留下低频背景轮廓) = 得到的就是滤过的高频细节(剪掉轮廓,图像更清晰)。
总结:
- size越小,得到的低频混杂更多高频(高频阻碍的少)—> 模拟的低频稳定,光照杂质细节更多,相减就剩下了少量的细节
- size越大,得到的低频更纯净(高频阻碍的越多)-> 模拟的低频稳定光照成像更完美
不同的高斯kernel对图像的影响如下图所示:
图19:不同的高斯kernel对图像的影响
MSR(Multi Scale Retinex)
由于SSR无法同时保证动态范围和对比度增强,研究人员就研究了多尺度的Retinex(毕竟遇事不决ensemble),在高、中、低三个尺度上做SSR,再加权融合,得到最终成像,通常权重为1:1:1,高斯核尺度使用了[30,150,300]。
MSRCR
使用MSR增强后的图像需要进一步进行图像恢复,对多尺度的结果做色彩平衡、归一化、增益和偏差的线性加权,(具体可以参考GIMP公司使用的MSRCR算法)
总结MSRCR算法流程:
- 使用高斯函数对原始图像进行低通滤波
- 将原始图像与滤波后图像转换到对数域做差,得到对数域的反射图像
- 多尺度重复1,2步骤,将对数域的反射图像在像素层面上进行图像求和,得到MSR结果
- 颜色恢复:
- 在通道层面,对原始图像求和,作为各个通道的归一化因子
- 权重矩阵归一化,并转换到对数域,得到图像颜色增益。(原始图像乘以颜色修复的非线性因子,这里取2.0,再除以归一化因子)
- MSR结果按照权重矩阵与颜色增益重新组合(连乘)
- 图像恢复:颜色恢复后的图像乘以图像像素值改变范围的增益,加图像像素值改变范围的偏移量,得到最终结果
由于算法对速度的要求较高,使用较大的simga,根据3 sigma原则,会对应较大的滤波器尺寸,针对(1317,1079,3)的图,使用sigma=300,kernel_size=1801的滤波器,SSR处理时间为20.4s,使用自己的笔记本需要近50s,无法满足速度要求。最重要的是,需要补大量的padding,使图像失真。在这里尝试过,用GPU加速运算,将高斯滤波器当作kernel,定义一个torch的卷积,针对(1317,1079,3)的图,自定义高斯核大小,结果如下:
由于为了节省时间,sigma不变的情况下,修改了kernel_size的大小,改变了能量的分布,图像复原效果较差。
方法:给出任意大小的sigma值,都可以通过使用图像金字塔与可分离滤波器计算高斯卷积;
- 使用图像金字塔,使用5*5的高斯滤波器,逐层对高斯金字塔滤波,并下采样,下采样后,sigma减半,用于下一层滤波
- 不断递归,直到由sigma算出来的滤波器的size小于10
- 当递归到,滤波器的大小小于10后,分x轴y轴对对应的下采样图进行高斯运算,这个图是经过一次次高斯模糊降采样得到的。
- 反向逐层上采样,得到与输入原图同样分辨率,滤波结束
使用图像金字塔滤波与可分离滤波器,MSR只需要0.18199s,SSR只需要0.058s。然而,一顿操作猛如虎,反而降低0.5。在验证集上MAP降低了0.004,MAP50降低0.004,MAP75降低0.004,稳定降分。线上测试降低0.0006,但是海参的AP略有升高,扇贝的AP降低较多。Retinex算法超参较多,需要分析调试,在这上面花的时间较少。有论文提到可能是低质量的域导致高的跨域泛化能力,域内图像增强不利于模型泛化 [9]。算法可视化效果明显,增强算法的速度得到了提高,后续可深入挖掘。
图20:MSRCR增强前后对比图
(5) 泊松融合
在之前实验中发现海参检测效果差,受论文《UDD: An Underwater Open-sea Farm Object Detection Dataset for Underwater Robot Picking》[10] 启发:“海参和扇贝因为训练样本不足和数据类别不平衡问题导致很多模型表现不好”。因此使用了泊松融合 [11] 将海参融合进多个图片以增强海参数据量,希望能够提升海参的表现。
通过博客 [12],我们能得到泊松融合的大致步骤:
-
准备原图source和背景图target,用mask扣除原图中的ROI,需要点P指定这个ROI放到背景图某个位置,注意P点为ROI的中心点所在位置;
-
计算ROI和背景图target的梯度场;
-
计算个融合图像的梯度场,就是用ROI的梯度场替换背景图相应处的梯度场;
-
计算融合图的散度场Laplace;
-
用这个laplace和原图求解泊松等式,也就是求解Ax=b。这里A是由泊松方程得到的,b是散度,x就是融合图像的像素值。
图21:泊松融合的增强数据样本(框内目标为融合的海参)
实验针对宽高为720和405的图片进行海参目标的数据增强工作(采用该尺寸的图片有两点原因:一是图片第二大,处理速度快不像第一大尺寸的图片,处理慢且耗内存。二是单独对这类图片融合后背景差异不会太大,避免融合突兀)。由于海参问题严重,所以只针对抠取了900多个海参,然后选取单图标注数量不超过4的图片作为融合海参的背景图片(单图过多标注可能会影响放置粘贴目标和带来冗余的目标加重类别不平衡问题)。之后根据融合后可视化结果将2616张增强图人工剔除剩1441张融合较好的图加入到原始数据集中进行训练。最后增强后各类别数据是:海参(4574变到6991),海胆(18676到20818),扇贝(5554到5653)和海星(5704到6326)。模型最后的表现并没有提升,即使是海参的AP也没增加,猜测原因是:融合的还是有些许不自然,容易使模型过拟合,而且这里并没有使用新的背景图片,而是原数据的图片,这也导致一些背景和目标重复出现,影响模型通用性的提升。
(6) 标签平滑
论文 [7] 在介绍目标检测的一些小技巧时,谈及了标签平滑,简单说来就是,在实际softmax中,分子是不会等于分母的,但模型为了增大准度,它就会鼓励模型在预测上过度自信,从而易过拟合。而标签平滑让原本标签为0 0 0 1 0 0的独热编码,变为0.1 0.1 0.1 0.9 0.1 0.1的独热编码(这边只是随便举个例子,具体还得按照图22中公式3进行计算)。然后再进行交叉熵的计算。标签平滑能减缓模型过拟合现象。我们试了平滑指数为0.5, 0.005, 0.0001后发现,提交结果都会低点,而大的平滑指数会导致损失难下降。猜测原因是在易学性高的目标上不适用标签平滑增大模型的学习难度。
图22:论文 [7] 对标签平滑的阐述
4. 专家模型
为了提高海参检测能力,我们使用了海参专家模型,即单训海参,但尝试了多种模型,效果都不好。我们后面觉得其实不该这么训,应该使用全类训练集训海参专家模型,最后取海参在验证集上表现最好的海参预测结果对当前最优模型中海参结果进行结果替换。
5. 模型融合
在3月27日左右,很多选手分突然上了0.49,应该是得益于选手分享的:res50和se50均可以达到线上testA 46-47 mAP, 经过spytensor选手试验进行模型集成可以达到49+。在论文《Weighted Boxes Fusion: ensembling boxes for object detection models》[13] 里提到两种模型融合思路,一种是同一模型不同backbone的融合(也是选手@spytensor的推荐,且建议使用WBF(IOU=0.7)), 第二种是不同结构的模型进行融合,根据论文所述这种方法比前者提升更大。WBF的代码已开源地址 [14]。我们后面尝试了下,结果都不太好,实验结果如下:
图23:模型融合
图24:WBF计算过程及示意图
后续我们整理了以下对于WBF的一些发现和思考:
- WBF融合分为两块:框和置信度。各自聚类匹配框和其置信度的融合权重是score × weight。
- 如果WBF是在softNMS的结果上做融合,会因为某目标上存在冗余低分框拉低融合后的框分数,而框的位置也是平均了冗余框得到。解决方法有两个:
- 使用论文的方法,使用NMS输出的结果上实施WBF,@spytensor推荐NMS的score_thr = 0.001,这样NMS只是保留当前模型下唯一的高分框,这样最后平均融合后不会受冗余低分框影响。
- 在softNMS下,改置信度融合方法conf_type为max,这样在两个模型预测结果中选择其中最大的置信度作为平均融合框的置信度。
- 以上两种方法中,框坐标的融合都是采用score x weight然后平均的方式,只是置信度不一样,前者使用avg(NMS),后者max(SoftNMS)。需要注意的是以上两种方法不建议使用weights=[2,1],因为如果一个框0.9,一个框1.0,最后融合conf=(0.9x2+1.0)=1.4>1.0,分数会不正常。因此后续推荐使用weights=[1,1]。
- 如果模型1在某处预测了一个框(置信度为C),但模型2在某处没有预测到这个框,WBF代码会通过(C=C×某cluster上框数T/模型数量)降低其置信度,这里即融合后框的置信度是C/2。
- 作者在论文提到模型如果服从不同的概率分布,例如有些模型大部分会给0.8~0.9的置信度,而其他模型可能会给0.00008~0.00009,但它们是有相似的mAP的,因为mAP的计算个是使用框排序的方式,但融合后会影响分,这个问题可以通过confidence normalization进行结果(开源代码并没有加入这块内容)。
6. guided-anchoring
常见的检测任务,anchor的尺度和长宽比需要统计数据,针对不同的样本分布要有针对性的设计anchor大小,这是一个对性能影响比较大的超参,如果设置不合适可能导致recall不够高,或者anchor过多影响分类性能和速度,预先定义好的anchor形状不一定能满足极端大小或者长宽比悬殊的物体,所以我们期待的是稀疏、形状根据位置可变的anchor。论文 [15] 将anchor的概率密度分布分解为两个条件概率分布,也就是给定图像特征后anchor中心点的概率分布,和给定图像特征和中心点之后的形状概率分布。用网络去回归中心点,已知中心点再去回归w,h,以此生成anchor,再用于回归和分类。
我们将cascade的rpn-head换为guided-anchoring模块,按照论文的trick,我们在最高得分模型基础上,添加ga模块,使用0.002,0.0002,0.00002三个学习率,fine-tune3个epoch,感觉网络对ga模块不是很明显,线上测评得分降低了0.003。
7. 其它
除了以前的尝试,我们还做了很多其他的工作如下:
-
追加海草难样本标注:由于海草在全数据集上只有82个标注且很多海草并没有被认真标注,且存在海草被误认做海胆和海参,对此的猜测是海草标注不清楚带来了模型辨认上的困难。为了清除这个遗漏,我们先将当前最优模型预测训练集并可视化框在图上,之后将训练集中被误检成其他类且无标注的海草目标进行框的绘制,之后补充到原数据集中,5千多张图最后补充了额外800多个海草标注,提交结果比最优实验少了5w的标注。但最后模型提交结果并不是很好,可能是因为在减少误检和提高查全率(即检测出更多框)之间,mAP在此数据上更加偏向于后者。
-
结果替换:根据验证集表现,将不同类别上表现最好的模型结果进行拼凑,但提交结果都不太好。其实应该在上面第4点的专家模型提到的建议去做结果替换会有好的效果,但后面时间上来不及了。
-
cosine lr decay:我们使用后发现该方法下,损失下降的更加低了,说明在cosine学习率衰减策略下,模型收敛更好,但提交结果不好,可能是学习率放大后再用cosine lr decay导致了模型过拟合,由于时间紧凑,并没深入下去。
五、参赛心得
尽管没有拿到一个好的名次,但还是学到了不少东西,感谢队友们的相互努力,今日的试错会让以后少走很多弯路。那么多tricks用起来虽然不好,但可能是数据本身存在噪声的问题,期待前排大佬能分享如何在这种数据上获得稳健的高分模型。
项目开源代码地址:https://github.com/Wakinguup/Underwater_detection
微信公众号:

参考文献:
[1]https://www.kesci.com/home/competition/5e535a612537a0002ca864ac/content/
[2] Cai, Z., & Vasconcelos, N. (2018). Cascade r-cnn: Delving into high quality object detection. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 6154-6162).
[3] Lin, T. Y., Dollár, P., Girshick, R., He, K., Hariharan, B., & Belongie, S. (2017). Feature pyramid networks for object detection. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 2117-2125).
[4] Chen, K., Pang, J., Wang, J., Xiong, Y., Li, X., Sun, S., … & Loy, C. C. (2019). Hybrid task cascade for instance segmentation. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 4974-4983).
[5] Chen, K., Wang, J., Pang, J., Cao, Y., Xiong, Y., Li, X., … & Zhang, Z. (2019). MMDetection: Open mmlab detection toolbox and benchmark. arXiv preprint arXiv:1906.07155.
[6] Pang, J., Chen, K., Shi, J., Feng, H., Ouyang, W., & Lin, D. (2019). Libra r-cnn: Towards balanced learning for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (pp. 821-830).
[7] Zhang, Z., He, T., Zhang, H., Zhang, Z., Xie, J., & Li, M. (2019). Bag of freebies for training object detection neural networks. arXiv preprint arXiv:1902.04103.
[8]https://baijiahao.baidu.com/s?id=1652911649267060207&wfr=spider&for=pc
[9] Chen X , Lu Y , Wu Z , et al. Reveal of Domain Effect: How Visual Restoration Contributes to Object Detection in Aquatic Scenes[J]. 2020.
[10] Wang, Z., Liu, C., Wang, S., Tang, T., Tao, Y., Yang, C., … & Fan, X. (2020). UDD: An Underwater Open-sea Farm Object Detection Dataset for Underwater Robot Picking. arXiv preprint arXiv:2003.01446.
[11] Pérez, P., Gangnet, M., & Blake, A. (2003). Poisson image editing. In ACM SIGGRAPH 2003 Papers (pp. 313-318).
[12] https://blog.csdn.net/u014485485/article/details/89481501
[13] Solovyev, R., & Wang, W. (2019). Weighted Boxes Fusion: ensembling boxes for object detection models. arXiv preprint arXiv:1910.13302.
[14] https://github.com/ZFTurbo/Weighted-Boxes-Fusion
[15] Wang J , Chen K , Yang S , et al. Region Proposal by Guided Anchoring[J]. 2019.
