Python 深度学习
文章目录
挑战与常规套路
图像分类:计算机视觉核心任务
图像在计算机中长什么样?
 导入一张图片,如何知道他是什么?首先,要知道图像是什么样子,一张图片被表示成三维数组的形式。 例如:300 x 100 x 3
导入一张图片,如何知道他是什么?首先,要知道图像是什么样子,一张图片被表示成三维数组的形式。 例如:300 x 100 x 3

3 表示:在图像中存在颜色通道:R、G、B,所有的颜色都是由RGB组成的,此时的3表示的就是颜色通道。
数组中的每个数值表示像素点,图片就是由这样一个一个像素点组成的(像素点的取值范围0 ~ 255)如果一个像素点的值越高,他的颜色的亮度越高。(与亮度挂钩)
挑战:照射角度、光照强度、形状改变、部分遮蔽、背景混入
正方向的角度可能比较容易识别,如果变换了一个角度进行拍摄是否还可以识别出?

光照强度不同也可以使最终的结果发生该改变。

在自动驾驶的技术中,如果路边有一只猫躺着,趴着…是否还能检测出来?

这是现在要解决的最核心的问题。在密集人群当中的,半个脸能否检测出来呢?

常规套路:
- 收集数据并给定标签
- 训练一个分类器
- 测试、评估
def train(train_images, train_labels):
# build a model for images -> labels..
return model
def predict(model, test_images):
# predict test_labels using the model..
return test_labels
用 k - 近邻来进行分类
k - 近邻算法:
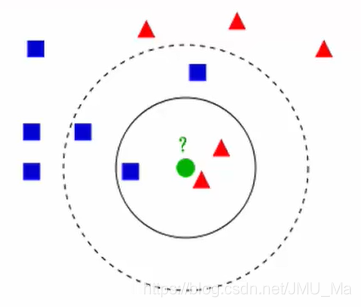
- 如果k = 3, 绿色圆点的最近的3个邻居是2个红色三角和1个蓝色方格,少数从属多数,基于统计的方法,判定绿色的这个待分类点为红色三角一类。
- 如果 K = 5,绿色圆点的最近的5个邻居是2个红色三角和3个蓝色方格,少数从属多数,基于统计的方法,判定绿色的这个待分类点为蓝色方格一类。
对于未知类别属性数据集中的点
- 计算已知类别数据集中的点与当前点的距离
- 按照距离依次排序
- 选取与当前点距离最小的K个点
- 确定前K个点所在类别的频率
- 返回前K个点出现频率最高的类别作为当前点预测分类
概述:
KNN算法本身简单有效,它是一种lazy - learning算法
分类器不需要使用训练集进行训练,训练时间复杂度为0
KNN.分类的计算复杂度和训练集中的文档数目成正比,也就是说,如果训练集中文档总数为n,那么KNN的分类时间复杂度为O(n)
数据集样例:CIFAR - 10

数据集为什么这么小?大家可以很轻松的进行预测,复杂度较小,适合练习。
如何计算的呢:
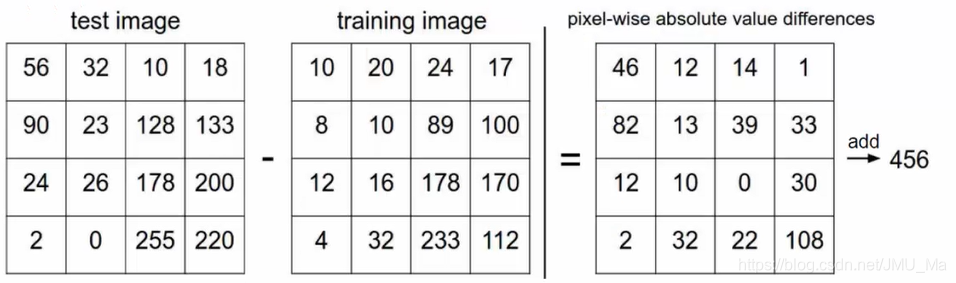
最近邻代码
import numpy as np
class NearestNeighbor:
def __init__(self):
pass
def train(self, X , y):
self.Xtr = X
self.ytr = y
def predict(self, X):
num_test = X.shape[0]
Ypred = np.zeros(num_test, dtype = self.ytr.dtype)
for i in xrange(num_test):
distances = np.sum(np.abs(self.Xtr - X[i, :]), axis = 1)
min_index = np.argmin(distances)
Ypred[i] = self.ytr[min_index]
return Ypred超参数与交叉验证:
超参数:
L1(Manhattan)distance L2(Euclidean)distance
超参数是指在训练的过程中可以进行改变的。
问题
- 对于距离如何设定?
- 对于K近邻的K该如何选择?
- 如果有的话,其他的超参数该怎么设定?

多次用测试数据试验,找到做好的一组参数组合?
错误的想法,测试数据只能最终用
测试结果:
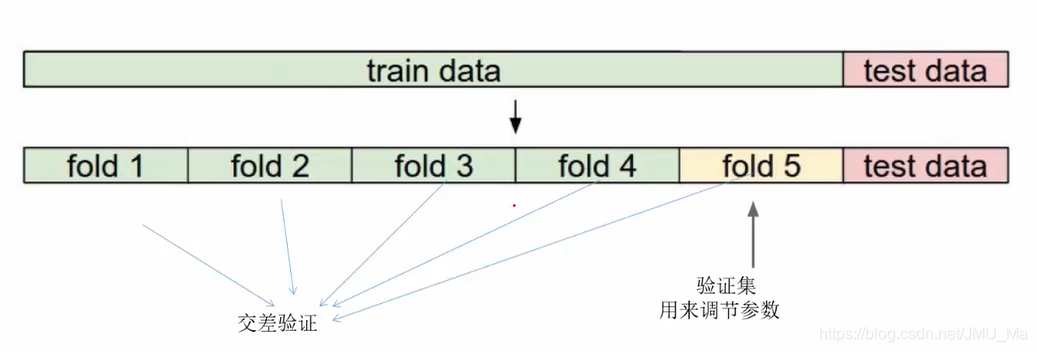
迭代地进行测试。例如
第一次进行1、2、3、4 ->5
第二次进行1、3、4、5 ->2
为什么还要再分成五份?
因为数据不一定那么纯,训练集和测试集可能会出现偏差。例如一组测试集中全部为1,出现一个不是1的数就可能导致出现较大的偏差。
背景主导:

图像的主体所占的部分,背景所产生的影响。例如蓝天下的汽车和蓝天下的飞机。就会造成物体的识别不对。所以在算法当中不能只用K-近邻来完成。

(不同的变换和原图具有相同的L2距离)
(尚待补充)