BitMap算法
1、概念
BitMap算法就是创建一个数组,将要存入的数据当作一个数组索引,去该索引下将该值设置为1,BitMap使用bit位来存储数据,也就是说每一位的值只能是0或1,能够节省大量的存储空间。
2、原理
1、空间大小
BitMap与频次数组相似,不同的是频次数组的每一个元素一般使用int来存储,而BitMap使用bit来存储。在Java中int、byte和bit的关系:
1 int =4 byte
1byte = 8 bit
假如我们要对0----7,8个数字进行排序,我们使用BitMap时,只需要用1byte即8个bit存储:
bit[] bit=new bit[8];
bit[1]= 1; bit[2]= 1;
bit[3]= 1; bit[4]= 1;
bit[5]= 1; bit[6]= 1;
bit[7]= 1; bit[8]= 1;
而用int存储时需要用8个int即256个bit存储。32位机器上的自然数一共有4294967296个,如果用一个bit来存放一个整数,1代表存在,0代表不存在,那么把全部自然数存储在内存只要4294967296 / (8 * 1024 * 1024) = 512MB(8bit = 一个字节),而这些自然数存放在文件中,一行一个数字,需要20G的容量。所以当数据量巨大的时候,BitMap能够节省大量的空间。设置时候时间复杂度O(1)、读取时候时间复杂度O(n),操作是非常快的。 二进制数据的存储,进行相关计算的时候非常快而且方便扩容。
2、存储转换
由于BitMap是以bit位存储的,而需要存储的数为整数,所以涉及到一个10进制转换为2进制的问题。假设需要排序或则查找的数的总数N=100000000,BitMap中1bit代表一个数字,1个int = 4Bytes = 4*8bit = 32 bit,那么N个数需要N/32 int空间。所以我们需要申请内存空间的大小为int a[1 + N/32],其中:a[0]在内存中占32为可以对应十进制数0-31,a[1]在内存中占32为可以对应十进制数32-63,a[2]在内存中占32为可以对应十进制数64-95,依此类推.
- 十进制在对应数组a中的区域
十进制对应的在bit数组的下标为十进制数0-31,对应在数组a[0]中,32-63对应在数组a[1]中,64-95对应在数组a[2]中,即n在数组a中的下标为:a[n/32] - 十进制在数组a[i]中的具体位置
十进制数1在a[0]的下标为1,十进制数31在a[0]中下标为31,十进制数32在a[1]中下标为0。 在十进制0-31就对应0-31,而32-63则对应也是0-31,即给定一个数n可以通过模32求得在对应数组a[i]中的下标。 - 具体计算
对于一个十进制数n,对应在数组a[n/32][n%32]中,由于数组a为一维数组,所以使用位运算来实现:
//n模上32相当于n向右移动5位
n/32 = n>>5
//将1向左移n % 32位,代表n%32的数在二进制数组中存在,即为1。后与本身的存储空间a[n>>5]相与,保持之前存储的数据不变。
a[n>>5]=a[n>>5] | 1<<n
3、自定义BitMap
public class BitMap {
private static final int N = 10000000;
private int[] a = new int[N / 32 + 1];
/**
* 设置所在的bit位为1
*
* @param n
*/
public void addValue(int n) {
//n模上32相当于n向右移动5位
int row = n >> 5;
//将1左移n%32位,且与自身或运算,保持之前存储的数据不变。
a[row] |= 1 << n;
}
// 判断所在的bit为是否为1
public boolean exits(int n) {
int row = n >> 5;
return (a[row] & 1 << n) != 0;
}
public void display(int row) {
System.out.println("BitMap位图展示");
for (int i = 0; i < row; i++) {
List<Integer> list = new ArrayList<Integer>();
int temp = a[i];
for (int j = 0; j < 32; j++) {
list.add(temp & 1);
temp >>= 1;
}
System.out.println("a[" + i + "]" + list);
}
}
public static void main(String[] args) {
int num[] = {1, 5, 30, 32, 64, 56, 159, 120, 21, 17, 35, 45};
BitMap map = new BitMap();
for (int i = 0; i < num.length; i++) {
map.addValue(num[i]);
}
int temp = 5;
if (map.exits(temp)) {
System.out.println("temp:" + temp + "has already exists");
}
map.display(5);
}
}
4、BitMap具体实现
1、Java的BitSet工具类
在Java中使用BitSet实现了BitMap算法,使用的是Long数组,也就是每一个元素占用64bit。所以它的每一项都可以存储64位数。对BitSet的部分源码解析:
public BitSet() {
initWords(BITS_PER_WORD);
sizeIsSticky = false;
}
public BitSet(int nbits) {
// nbits can't be negative; size 0 is OK
if (nbits < 0)
throw new NegativeArraySizeException("nbits < 0: " + nbits);
initWords(nbits);
sizeIsSticky = true;
}
private BitSet(long[] words) {
this.words = words;
this.wordsInUse = words.length;
checkInvariants();
}
BitSet提供三种初始化方式,第一种创建不指定长度,传入第一个参数时初始化数组,长度为该参数对应右移6位之后的长度。第二种是传入指定长度。第三种是传入一个long型数组。其中sizeIsSticky为是否由用户指定长度。
private static int wordIndex(int bitIndex) {
return bitIndex >> ADDRESS_BITS_PER_WORD;
}
给定一个索引,返回他属于哪个long数组下标。其中ADDRESS_BITS_PER_WORD的值为6,因为Long为64位,所以参数bitIndex需要模上64,即向右移6位。
private void expandTo(int wordIndex) {
int wordsRequired = wordIndex+1;
if (wordsInUse < wordsRequired) {
ensureCapacity(wordsRequired);
wordsInUse = wordsRequired;
}
}
判断数组长度是否大于当前需要存储所计算出来的长度,如果原有长度小,则进行扩容,扩容的方式如下:
private void ensureCapacity(int wordsRequired) {
if (words.length < wordsRequired) {
int request = Math.max(2 * words.length, wordsRequired);
words = Arrays.copyOf(words, request);
sizeIsSticky = false;
}
}
默认扩容得机制为取之前长度的两倍与需要存储的新的值得长度进行比较,取大值进行扩容。
public void set(int bitIndex) {
if (bitIndex < 0)
throw new IndexOutOfBoundsException("bitIndex < 0: " + bitIndex);
int wordIndex = wordIndex(bitIndex);
expandTo(wordIndex);
words[wordIndex] |= (1L << bitIndex); // Restores invariants
checkInvariants();
}
set操作中前部分代码中讲过,其中words[wordIndex] |= (1L << bitIndex)中的1L << bitIndex为移位操作,与自身相或是为了保持元素中之前的数据。最后checkInvariants()检查数组长度是否异常。
public boolean get(int bitIndex) {
if (bitIndex < 0)
throw new IndexOutOfBoundsException("bitIndex < 0: " + bitIndex);
checkInvariants();
int wordIndex = wordIndex(bitIndex);
return (wordIndex < wordsInUse)
&& ((words[wordIndex] & (1L << bitIndex)) != 0);
}
get操作中先对长度进行异常排查,然后使用(words[wordIndex] & (1L << bitIndex)操作,检查当前的数在数组元素中是否存在,如果不存在,那么words[wordIndex]位上的数字肯定为0,相与结果必然也为0。
public int length() {
if (wordsInUse == 0)
return 0;
return BITS_PER_WORD * (wordsInUse - 1) +
(BITS_PER_WORD - Long.numberOfLeadingZeros(words[wordsInUse - 1]));
}
bitSet对lenth方法进行了封装,总长度等于右移6位后的数乘以当前使用的元素的长度加上数组最后一部分的长度。
2、Redis的BitMap结构
redis中的高级数据类型BitMap实现了BitMap算法,他提供setbit、getbit、bitcount等相关命令完成对BitMap的操作。
- 获取指定key对应偏移量上的bit值
getbit key offset
- 设置指定key对应偏移量上的bit值,value只能是1或0
setbit key offset value
- 对指定key按位进行交、并、非、异或操作,并将结果保持到destKey中。
bitop xx destkey key1 [key2...]
xx中可填写值:
- and:交
- or:并
- not:非
- xor:异或
- 统计指定key中1的数量
bitcount key [start end]
5、BitMap的应用
1、现在有五十亿个int类型的正整数,要从中找出重复的数并返回,对去重后的数字进行排序。
public class Test {
//使用BitSet实现查重和排序
public static Set<Integer> bitCount(int[] arr) {
Set<Integer> res = new HashSet<>();
BitSet bitSet = new BitSet(arr.length);
StringBuffer string = new StringBuffer();
//如果存在则加入到set集合中,不存在则存入bitSet
for (int i = 0; i < arr.length; i++) {
if (bitSet.get(arr[i])) {
res.add(arr[i]);
} else {
bitSet.set(arr[i]);
}
}
//遍历bitSet,依次取出有值的索引,内部封装了length和get方法。
for (int i = 0; i < bitSet.length(); i++) {
if (bitSet.get(i)) {
string.append(i).append(",");
}
}
System.out.println(string.toString());
return res;
}
//模拟实现bitSet查重和排序
public static Set<Integer> bitCountTwo(int[] arr) {
Set<Integer> res = new HashSet<>();
long[] bitSet = new long[arr.length];
StringBuffer string = new StringBuffer();
for (int i = 0; i < arr.length; i++) {
int element = arr[i];
//当前元素属于long数组第几个
int row = element >> 6;
//如果存在放入set中
if ((bitSet[row] & 1 << element) != 0) {
res.add(element);
} else {
//不存在放入bitSet中
bitSet[row] |= (1 << element);
}
}
//第一次遍历先取到long数组的元素
for (int i = 0; i < bitSet.length; i++) {
//第二次遍历取到元素后遍历找到64位中有值的位数。
for (int j = 0; j < 64; j++) {
//使用1L左移,因为必须64位。(用1搞了老半天,debug发现左移33位时又回到最右边重新左移)
if ((bitSet[i] & 1L << j) != 0) {
//i*64中i为当前元素所在区间,64为之前每个区间有64个值。当前值等于i*64+j
string.append(i * 64 + j).append(",");
}
}
}
System.out.println(string.toString());
return res;
}
public static void main(String[] args) {
//演示十万个十万以内的数查重和排序
int[] rom = new int[100000];
Random random = new Random();
for (int i = 0; i < 100000; i++) {
rom[i] = random.nextInt(100000);
}
Set<Integer> t2 = bitCountTwo(rom);
System.out.println(t2);
}
}
2、统计网站的日活跃量、连续几天登录用户
public void bitCount() {
Jedis jedis = new Jedis("192.168.1.195");
int userId=1;
//load:2020-03-27 为load网站在2020-03-27年的用户访问数据。
jedis.setbit("load:2020-03-27",1,true);
jedis.setbit("load:2020-03-27",23,true);
jedis.setbit("load:2020-03-28",1,true);
jedis.setbit("load:2020-03-28",8,true);
jedis.setbit("load:2020-03-29",1,true);
jedis.setbit("load:2020-03-29",23,true);
//全天共有多少用户访问过
Long bitCount = jedis.bitcount("load:2020-03-27");
//id为1的用户是否连续三天登录(具体业务:连续三天登录送福利)
jedis.bitop(AND, "threeDailyLoad", "load:2020-03-27", "load:2020-03-28","load:2020-03-29");
Boolean threeDailyLoad = jedis.getbit("threeDailyLoad", 1);
jedis.close();
}
6、布隆过滤器
1、概念
布隆过滤器顾名思义,就是一个过滤工具,常常用于判断是否重复并去重,常规的数据结构如HashMap、Set也能完成去重,但是插入和查询效率远远不如布隆过滤器。
2、原理
布隆过滤器与BitMap结构一样,也是由一个个bit元素组成的bit数组,当我们要映射一个值到布隆过滤器中时,我们不再是使用取模移位操作,而是使用哈希函数,一个值往往对应生成多个不同的hash函数,多个hash对应的索引共同决定这个值是否重复。
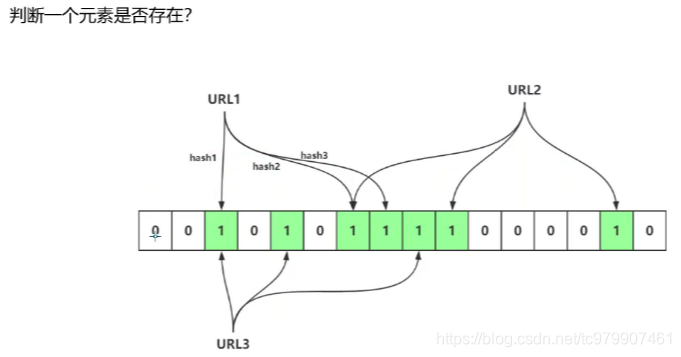
如上图中,URL1、URL2、URL3分别有三个hash值,当三个hash值对应的索引都有值时,该值可能重复。否则一定不重复。为什么是可能重复呢?因为hash值可能冲突,如果刚好你要存储的值的三个hash索引刚好被别的值得hash占用了,那么即使该值没有重复,也会被布隆过滤器误认为已经重复。所以一个值对应得hash个数不一定是越多越好,hash函数的个数与误报率如下图:

所以,需要根据实际的业务需求选取合适个hash函数。
3、布隆过滤器的应用
布隆过滤器可以爬虫去重URL、黑名单等问题。如解决Redis缓存穿透问题。在使用redis时,将各种数据的id先放入布隆过滤器中,相当于设置了数据白名单,布隆过滤器中有该值时放行,没有该数据时拦截。Guava中有布隆过滤器的依赖包。(//TODO 源码分析)。
以下演示布隆过滤器误判率的问题:
public void bloomFilter(){
//期望的误判率。 误判率不能为0,因为不可能达到。
double fpp=0.05;
BloomFilter<Integer> bloomFilter=BloomFilter.create(Funnels.integerFunnel(),1000000,fpp);
for (int i = 0; i < 100000; i++) {
bloomFilter.put(i);
}
int count=0;
for (int i = 100000; i < 200000; i++) {
if (bloomFilter.mightContain(i)) {
count++;
System.out.println(i + "误判了");
}
}
System.out.println("误判条数"+count);
}
- 当误判期望为0.05时,10000条数据误判条数为1。
- 当误判期望为0.5时,10000条数据误判条数为6500。
可以通过设置误判期望来调整布隆过滤器的数据结构和hash个数实现具体的业务需求。
