布隆过滤器的概念和原理
概念:布隆过滤器是一种空间效率较高的数据结构,它利用位数组表示一个集合。可以很容易的判断一个元素是否属于这个集合。但是它的这种高效有一定的代价:再判断一个元素是否属于这个集合时,有可能将不属于这个集合的元素误认为属于这个集合,因此,布隆过滤器不适合那些“零错误”的场景,而在能忍受低错误率的情况下,布隆过滤器通过极少的错误率换取存储空间的极大节省。
实现原理:在初始化时,布隆过滤器是一个包含m位的数组,而且将每一位都置为0。

为了表示S={x1,x2,x3,...,xn}这样n个元素的集合,布隆过滤器使用k个相互独立的哈希函数,它们分别将集合中的每一个元素映射到{1,2,3,...,m}的范围内。对于任意一个元素x,第i个哈希函数映射的位置hi(x)就被设置为1。注意:如果某一位置已经被设置为1,那么只有在第一次会起作用。
下图是一个被hash函数映射的例子:

在判断一个数字Y是否属于这个集合时,我们对Y应用k次哈希函数,如果所有的hi(y)的位置都是1,那么就可以认为Y是该集合里面的元素,否则不是该集合里的元素。
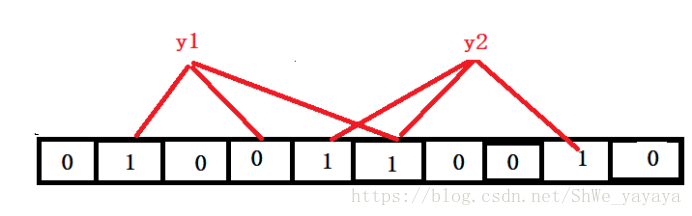
由图可看到y1在映射过程中有1位对应的是0,故y1不在集合内,y2的每一个映射对应的位都是1,故y2在该集合里面。
错误率:设P为数组中0的概论,则错误率为(1-P)^k。表示一个值每一个应用hash函数后对应位置的值都是1。
哈希函数个数k:如果哈希函数多,那么对一个不属于集合的元素进行查询后得到的0的概论就大。但是如果哈希函数少,那么位数组中不同数值哈希后落入同一位的概论就大,错误率就提高了。(最好保持让位数组还有一半还空着)K=(ln2)*(m/n);m表示位数组的大小,m位;n表示集合中元素个数。
位数组m的大小:m>=nlg(1/E)*1.44。(lg表示以2为底的对数,E表示错误率。
应用场景:查重、判断元素是否在一个集合中
总结:
布隆过滤器=位数组+k个哈希函数。
优点:插入和查询的时间都为常数
缺点:有错误率,删除一个元素可能会导致其他元素受到影响。
扩展:需要删除一个元素的话,就用一个整型数组代替位数组,数组下标代表位下标,用count记录该下标被映射的次数。
参考博客:
https://blog.csdn.net/v_JULY_v/article/details/6685894