什么是bit,什么是byte?
bit中文名称是位,音译“比特”,是用以描述电脑数据量的最小单位。在二进制数系统中,每个0或1就是一个位(bit)。
bit 来自binary digit (二进制数字),1byte=8bit,byte是计算机里面的基本单位,1mb=1024*1024bit。
假设当我们需要在一千万个整数(整数的范围在1-1亿之间)里面快速查找某个整数是否存在于其中的话,如何快速查找进行判断会比较方便呢?
1.散列表
通过散列表来实现该功能当然是可以的,但是散列表里面除了需要存储对应的数字以外,还需要存储对应的链表指针,每个数字都采用int类型来进行存储的话,光是数字占用的内存大小大概是40mb左右,如果是加上了指针的存储空间的话,那么存储的内存大小大概是80mb左右了。
2.布尔类型的数组
通过使用布尔类型的数组来进行存储。首先创建一个一千万长度的布尔类型数组,然后根据整数,定位到相应的下标赋值true,那么以后在遍历的时候,根据相应的下标查找到指定的变量,如果该变量的值是true的话,那么就证明该数字存在。布尔类型变量在存储的时候只有true和false存在,但是在数组中存储的时候实际上是占用了1个字节,该类型的变量在被编译之后实际上是以int类型的数据0000 0000和0000 0001存储的,因此还是占用了较多的内存空间。
3.bitmap
例如说一个长度是10的bitmap,每一个bit位都存储着对应的0到9的十个整形数字,此时每个bitmap所对应的位都是0。当我们存入的数字是3的时候,位图3的位置会变为1。
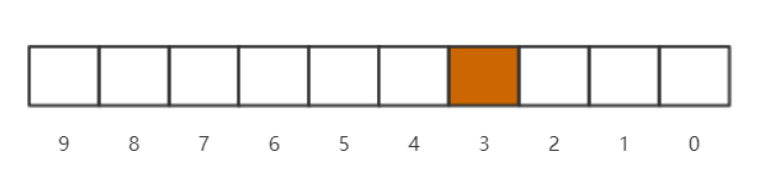
当我们存储了多个数字的时候,例如说存储了4,3,2,1的时候,那么位图结构就会如下所示:
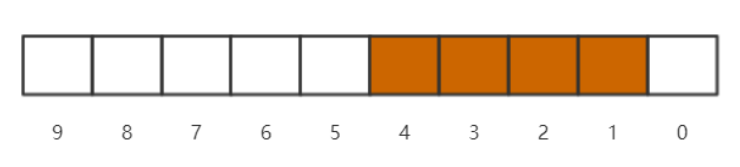
那么这个时候你可能就会疑惑了,到底在代码上边该如何通过计算来获取一个数字的索引定位呢?
首先我们将核心思路的代码先贴上来:
public void set(int number) {
//相当于对一个数字进行右移动3位,相当于除以8
int index = number >> 3;
//相当于 number % 8 获取到byte[index]的位置
int position = number & 0x07;
//进行|或运算 参加运算的两个对象只要有一个为1,其值为1。
bytes[index] |= 1 << position;
}
为了方便理解核心思想,所以还是通过图例来理解会比较好:
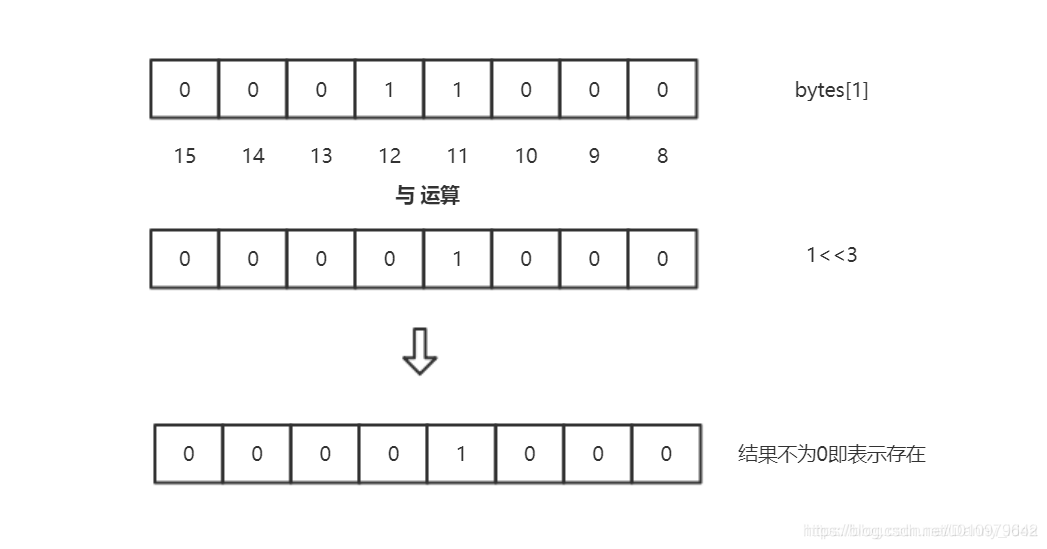
例如说往bitmap里面存储一个数字11,那么首先需要通过向右移位(因为一个byte相当于8个bit),计算出所存储的byte[]数组的索引定位,这里计算出index是1。由于一个byte里面存储了八个bit位,所以通过求余的运算来计算postion,算出来为3。
这里假设原有的bitmap里面存储了4和12这2个数字,那么它的结构如下所示:
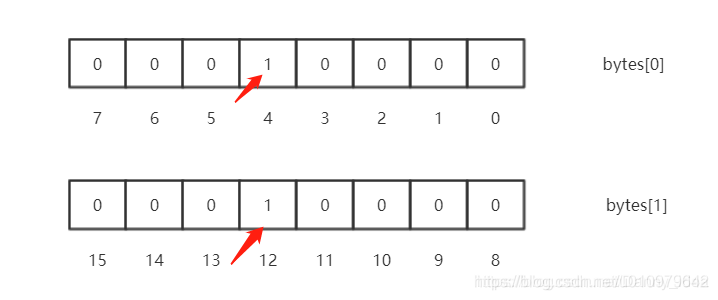 这个时候,我们需要存储11进来,那么就需要进行或运算了。
这个时候,我们需要存储11进来,那么就需要进行或运算了。
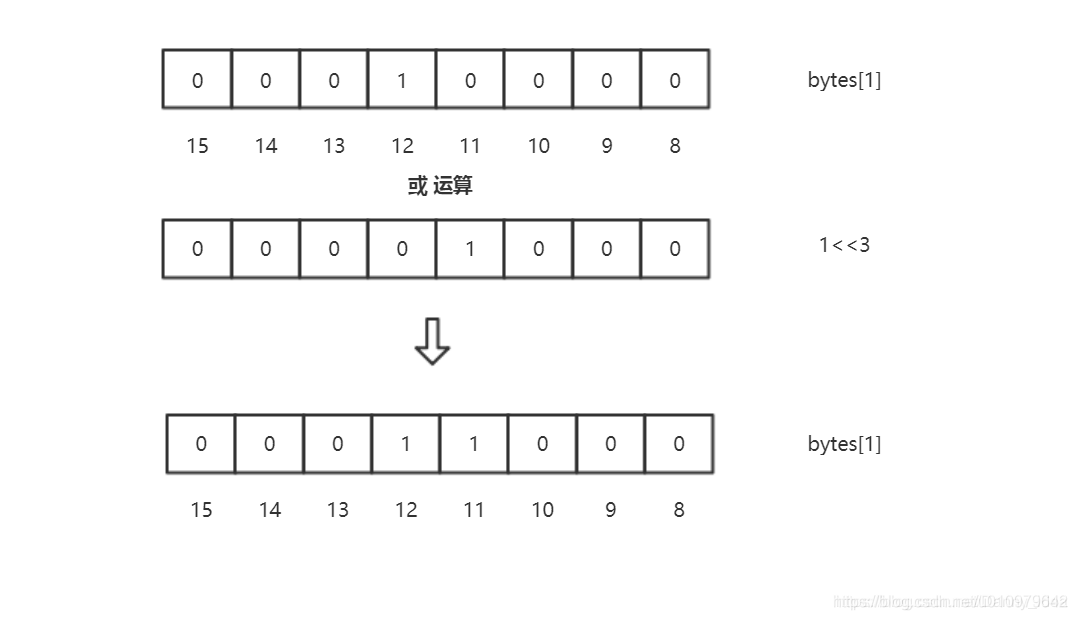
同理,当我们判断数字是否存在的时候,也需要进行相应的判断,代码如下:
public boolean contain(int number) {
int index = number >> 3;
int position = number & 0x07;
return (bytes[index] & (1<<position)) !=0;
}
 整合一下,简单版的一个bitmap代码如下:
整合一下,简单版的一个bitmap代码如下:
/**
* @author idea
* @data 2019/4/1
*/
public class MyBitMap {
private byte[] bytes;
private int initSize;
public MyBitMap(int size) {
if (size <= 0) {
return;
}
initSize = size / (8) + 1;
bytes = new byte[initSize];
}
public void set(int number) {
//相当于对一个数字进行右移动3位,相当于除以8
int index = number >> 3;
//相当于 number % 8 获取到byte[index]的位置
int position = number & 0x07;
//进行|或运算 参加运算的两个对象只要有一个为1,其值为1。
bytes[index] |= 1 << position;
}
public boolean contain(int number) {
int index = number >> 3;
int position = number & 0x07;
return (bytes[index] & (1 << position)) != 0;
}
public static void main(String[] args) {
MyBitMap myBitMap = new MyBitMap(32);
myBitMap.set(30);
myBitMap.set(13);
myBitMap.set(24);
System.out.println(myBitMap.contain(2));
}
}
从刚刚位图结构的讲解中,你应该可以发现,位图通过数组下标来定位数据,所以,访问效率非常高。而且,每个数字用一个二进制位来表示,在数字范围不大的情况下,所需要的内存空间非常节省。
比如刚刚那个例子,如果用散列表存储这 1 千万的数据,数据是 32 位的整型数,也就是需要 4 个字节的存储空间,那总共至少需要 40MB 的存储空间。如果我们通过位图的话,数字范围在 1 到 1 亿之间,只需要 1 亿个二进制位,也就是 12MB 左右的存储空间就够了。
但是实际应用中,却并非如我们所想象的那么简单,假设我们的实际场景进行改变一下:
还是刚刚的那个情况:
还是一千万个数字,但是数字范围不是 1 到 1 亿,而是 1 到 10 亿,那位图的大小就是 10 亿个二进制位,也就是 120MB 的大小,消耗的内存空间反而更加大了,而且在bitmap里面还会有部分空间浪费的情况存在。
假设我们对每一个数字都进行一次hash计算,然后通过hash将计算后的结果范围限制在1千万里面,那么就不需要再定义10亿个二进制位了。但是这样子还是会有相应的弊端,例如说hash冲突。那么这个时候如果我们采用多个hash函数来进行处理的话,理论上是可以大大降低冲突的概率的。于是就有了下边所说的布隆过滤器一说。
布隆过滤器

布隆过滤器通过使用多次的hash计算来进行数值是否存在的判断,虽然大大降低了hash冲突的情况,但是还是存在一定的缺陷,那就是容易会有误判的情况。例如说如下如所示:
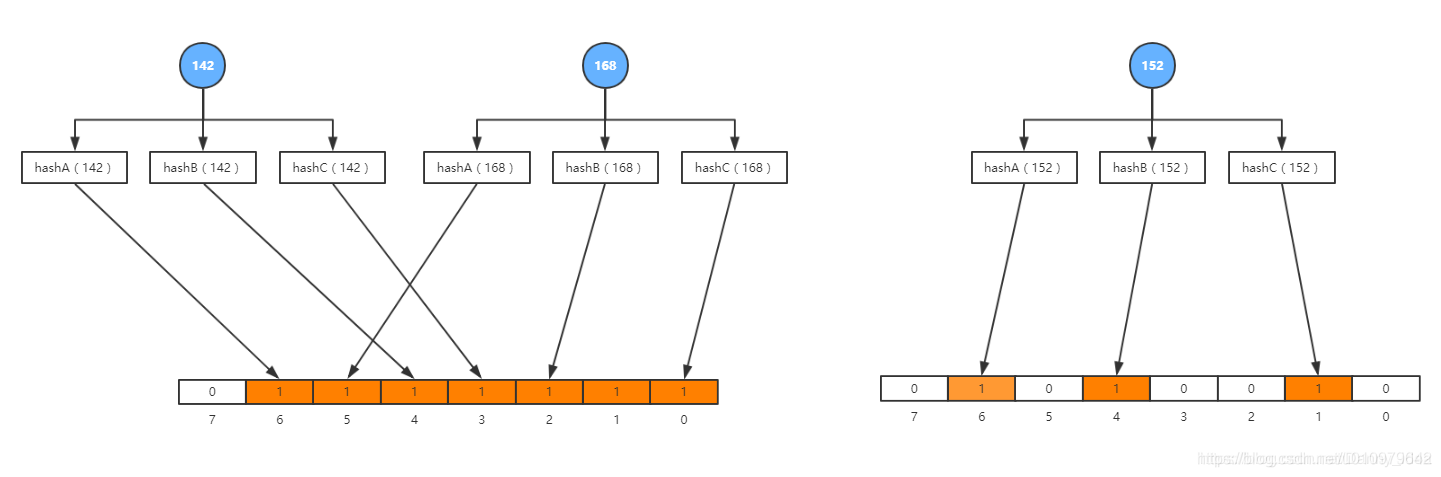
布隆过滤器的误判有一个特点,那就是,它只会对存在的情况有误判。如果某个数字经过布隆过滤器判断不存在,那说明这个数字真的不存在,不会发生误判;如果某个数字经过布隆过滤器判断存在,这个时候才会有可能误判,有可能并不存在。不过,只要我们调整哈希函数的个数、位图大小跟要存储数字的个数之间的比例,那就可以将这种误判的概率降到非常低。
尽管说布隆过滤器在使用的时候会有误判的情况发生,但是在对于数据的准确性有一定容忍度的情况下,使用布隆过滤器还是会比较推荐的。
在实际的项目应用中,布隆过滤器经常会被用在一些大规模去重,但又允许有小概率误差的场景中,例如说我们对一组爬虫网页地址的去重操作,或者统计某些大型网站每天的用户访问数量(需要对相同用户的多次访问进行去重)。
实际上,关于bitmap和布隆过滤器这类工具在大型互联网企业上已经受到了广泛使用,例如说java里面提供了BitSet类,Redis也提供了相应的位图类,Google里面的guava工具包中的BloomFilter 也已经实现类布隆过滤器。