Bitmap算法
与其说是算法,不如说是一种紧凑的数据存储结构。是用内存中连续的二进制位(bit),用于对大量整型数据做去重和查询。其实如果并非如此大量的数据,有很多排重方案可以使用,典型的就是哈希表。
实际上,哈希表为每一个可能出现的数字提供了一个一一映射的关系,每个元素都相当于有了自己的独享的一份空间,这个映射由散列函数来提供(这里我们先不考虑碰撞)。实际上哈希表甚至还能记录每个元素出现的次数,这样的数据结构完成这个任务有点“大材小用”了。
如果用HashSet或HashMap存储,每一个用户ID都要存成int,占4字节即32bit。而一个用户在Bitmap中只占一个bit,内存节省了32倍!
不仅如此,bitmap在做交集和并集的时候也有极大的便利
不过bitmap不支持非运算,要想实现非运算,就得多提供一个全量的bitmap
比如,在应对标签、用户的场景下,可以使用一个标签一个bitmap,bitmap上存储含有此标签的用户,这样有几个标签就有几个bitmap,极大地节省了空间。此外,要查询同时含有多个标签的用户,只需要让bitmap进行&运算,或运算同理。而非运算需要增加一个全量的bitmap,用这个来存储不包含的用户的id。这样要取非时只需要与这个bitmap进行异或运算即可。
JDK中的BitSet集合是对BitMap算法相对简单的实现,而谷歌开发的EWAHCompressedBitmap是一种更为优化的实现
如果对于一个很长的bitmap只存储少量的数据,那么会浪费一定的空间,所以谷歌的实现对这个空间进行了优化
然而Bitmap不是万能的,如果数据量大到一定程度,如64bit类型的数据,不能用Bitmap,2^64bit=2^61Byte=2048PB=2EB
Bitmap的好处在于空间复杂度不随原始集合内元素的个数增加而增加,而它的坏处也源于这一点——空间复杂度随集合内最大元素增大而线性增大。
布隆算法
是一种以bitmap集合为基础的排重算法,其应用场景如Url的排重,垃圾邮箱地址的过滤等邻域
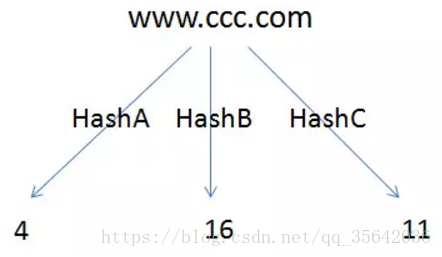
布隆算法的核心思想就是对url进行多次不同算法的hash,得到不同的hashcode,最后再将这些hashcode比较后映射到同一个bitmap上
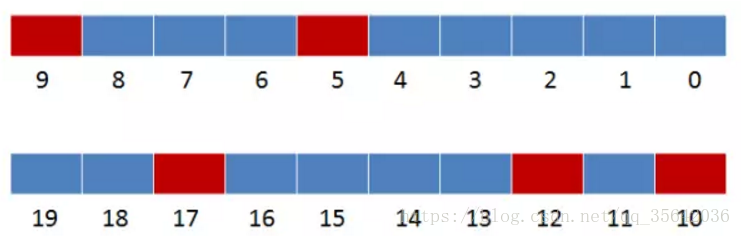
如下示例中,只要三个值在bitmap上不同时为红色,就可以插入,否则判断为重复url
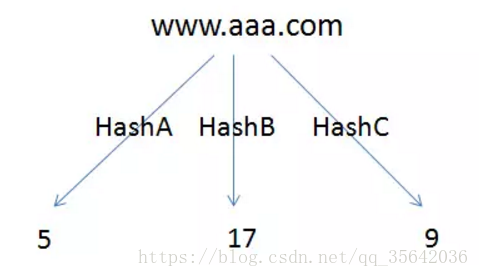
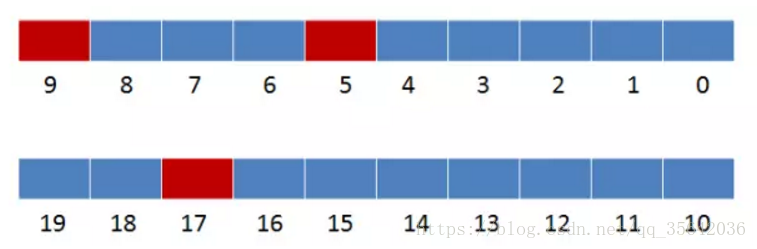

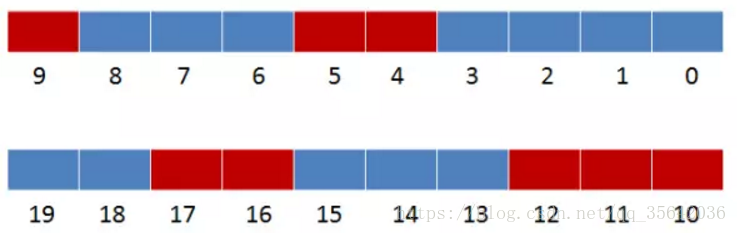
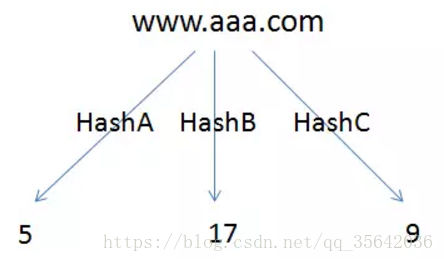
上图为重复url
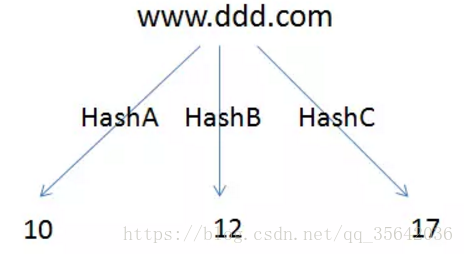
上图误判为重复url
为了减少误判的几率,可以让bitmap的空间更大一些,单个url所做的不同的hash更多一些(一般是8次),总之是在空间和准确率上做出取舍
bloom filter被用来检测一个元素是不是集合中的一个成员。如果检测结果是,该元素不一定在集合中;但如果检测结果为否,该元素一定不在集合中。主要思路是:将一个元素映射到一个 m 长度的阵列上,使用 k 个哈希函数对应 k 个点,如果所有点都是 1 的话,那么元素在集合内,如果有 0 的话,元素则不在集合内。 错误率:如何根据输入元素个数n,确定位数组m的大小及hash函数个数k,k=(ln2)*(m/n)时错误率最小,为。
参考链接:
如若读完本文还不是很清楚,墙裂建议再阅读以下文章