相应知识点回顾:
(一)内存单位的转换
1int = 4byte
1kb = 1024byte
1M = 1024kb
1G = 1024M 4G = 4*1024*1024*1024=42亿九千万
(二)逻辑运算
(1)按位与运算&: 只有对应的两个二进位均为1时,结果位才为1 ,否则为0
(2)按位或运算|:只要对应的二个二进位有一个为1时,结果位就为1。
(3)按位异或运算^: 两个对应的二进制位相异时,结果为1.
引入:
题目:给40亿不重复的无符号整数,没排过序,给一个无符号整数,如何判断一个数是否在这40亿个数中。
首先看到这个题目可能大部分同学会反应将这些数压入数组然后依次遍历。可是49亿个整型数在4G内存中,如果以整型方式存储是存不下的。这时候我们可以将40亿个整型转换为40亿个位,此时仅需要500M空间就可以存下这些数字的状态(1表示存在,0表示不存在)。
位图
位图:所谓bitset,就是用每一位来存放某种状态,适用于大规模数据,但数据状态不多的情况,通常是用来判断某个数据是否存在。
(1)开辟空间
BitSet(size_t range)
{
_bits.resize((range>>5)+1,0);
}开辟一个大小为(range/32)+1的数组,加1的原因是当数值范围小于32时,也要预留空间存放数据。
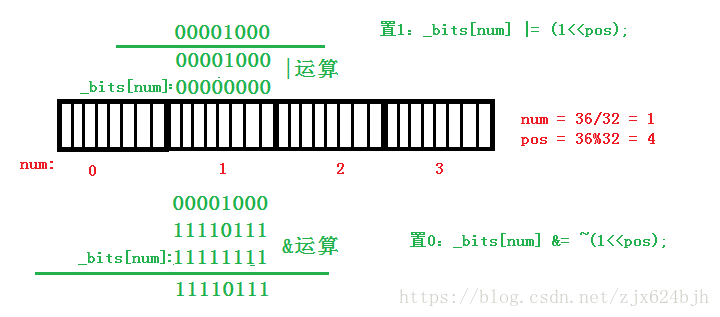
(2)置1操作
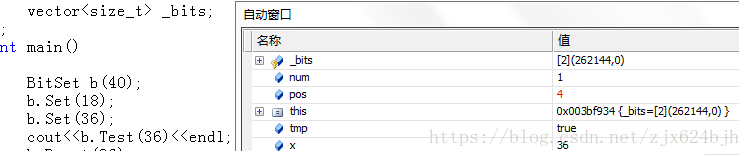
void Set(size_t x)
{
size_t num = x >> 5;
size_t pos = x % 32;
_bits[num] |= (1<<pos);
}给定一个数值,计算出该数字在数组中对应的下标以及下标中对应的位,或上1左移pos位,即可将对应位置为1.
(3)置0操作
void Reset(size_t x)
{
size_t num = x >> 5;
size_t pos = x % 32;
_bits[num] &= ~(1<<pos);
}
同上,只不过需要与上~(1 << bit),就完成置0操作
图解:
完整代码:
class BitSet
{
public:
BitSet()
{}
BitSet(size_t range)
{
_bits.resize((range>>5)+1,0);
}
void Set(size_t x)
{
size_t num = x >> 5;
size_t pos = x % 32;
_bits[num] |= (1<<pos);
}
void Reset(size_t x)
{
size_t num = x >> 5;
size_t pos = x % 32;
_bits[num] &= ~(1<<pos);
}
bool Test(size_t x)
{
size_t num = x >> 5;
size_t pos = x % 32;
bool tmp = _bits[num]&(1<<pos);
return tmp;
}
protected:
vector<size_t> _bits;
};再给个稍微复杂一点的情景:假如还是40亿个数字,我们现在要找出其中出现次数不少于三次的数字。有了上面的铺垫,这个题就很简单了。
第一题由于只需要表示存在或者不存在,所以一位二进制数就可以表示,但是这里需要找出出次数不少于三次的数字,所以需要两位二进制数,00表示不存在,01表示出现一次,10表示出现两次,11表示出现两次以上。
两位位图
class TwoBitSet
{
public:
TwoBitSet()
{}
TwoBitSet(size_t range)
{
_a.resize((range>>2)+1);
}
void Set(size_t x)
{
size_t num = (x>>2);
size_t pos = x%4*2;
bool first = _a[num]&(1<<pos);
bool second = _a[num]&(1<<pos+1);
if(!(first&&second))
_a[num]+=(1<<pos);
}
bool Test(size_t x)
{
int num = (x>>2);
int pos = x%4*2;
bool first = _a[num]&(1<<pos);
bool second = _a[num]&(1<<pos+1);
return first&& second ? true:false;//first second同时为1表示出现次数>=3 返回1
}
private:
vector<size_t> _a;
};布隆过滤器
基本原理:
底层使用的是位图。当一个元素被加入集合时,通过 K 个 Hash 函数将这个元素映射成一个位阵列(Bit array)中的 K个点,把它们置为 1。检索时,我们只要看看这些点是不是都是 1 就(大约)知道集合中有没有它了:如果这些点有任何一个0,则被检索元素一定不存在;如果都是1,则被检索元素很可能在。
优点:
空间效率和时间查询都大于一般算法,存储空间和查询/插入时间都是常数O(N)。
由于不需要存储数据本身,所以对于数据保密的场合非常有优势。
可以操作所有类型的数据,不存在类型限制。
缺点:
存在误判,存储元素越多,误判率越大。
但若存储元素较少还不如使用哈希。
不能随意删除元素,因为同一个位可能有多个数据标记了它。添加计数器的话计数器回绕也会造成问题。
什么是误判?
误判:判断这个元素是否在集合中,把这个元素作为K个哈希函数的输入,得到k个数组的位置,这些位置中只要有一个为0,元素肯定不在这个集合里。如果元素在集合中那么这些位置一定都会被置为1,如果这些位置都被置为1,要么元素在集合中。要么是其它元素在插入过程中被偶然置为1,导致误判。
代码实现:
//映射函数
template<class K>
struct __HashFunc1
{
static size_t BKDRHash(const char * str)
{
unsigned int seed = 131; // 31 131 1313 13131 131313
unsigned int hash = 0;
while (*str)
{
hash = hash * seed + (*str++);
}
return (hash & 0x7FFFFFFF);
}
size_t operator()(const K& key)
{
return BKDRHash(key.c_str());
}
};
template<class K>
struct __HashFunc2
{
size_t SDBMHash(const char *str)
{
register size_t hash = 0;
while (size_t ch = (size_t)*str++)
{
hash = 65599 * hash + ch;
//hash = (size_t)ch + (hash << 6) + (hash << 16) - hash;
}
return hash;
}
size_t operator()(const K& key)
{
return SDBMHash(key.c_str());
}
};
template<class K>
struct __HashFunc3
{
size_t APHash(const char *str)
{
register size_t hash = 0;
size_t ch;
for (long i = 0; ch = (size_t)*str++; i++)
{
if ((i & 1) == 0)
{
hash ^= ((hash << 7) ^ ch ^ (hash >> 3));
}
else
{
hash ^= (~((hash << 11) ^ ch ^ (hash >> 5)));
}
}
return hash;
}
size_t operator()(const K& key)
{
return APHash(key.c_str());
}
};
template<class K = string, class HashFunc1 = __HashFunc1<K>,class HashFunc2 = __HashFunc2<K>,class HashFunc3 = __HashFunc3<K>>
class Bloom
{
public:
Bloom(size_t num)
:_bm(num*5)
,_bitSize(num*5)
{}
void Set(const K& key)
{
size_t index1 = HashFunc1()(key);
_bm.SetBit(index1);//底层位图实现
size_t index2 = HashFunc2()(key);
_bm.SetBit(index2);
size_t index3 = HashFunc3()(key);
_bm.SetBit(index3);
}
bool Test(const K&key)
{
size_t index1 = HashFunc1()(key);
if(_bm.TestBit(index1)==false)
{
return false;
}
size_t index2 = HashFunc2()(key);
if(_bm.TestBit(index2)==false)
{
return false;
}
size_t index3 = HashFunc3()(key);
if(_bm.TestBit(index3)==false)
{
return false;
}
return true;//所有位都为真,它才很可能存在
}
private:
BitSet _bm;
size_t _bitSize;
};