使用hive时很容易接触到数仓建模,数仓建模是一个数仓工程师需要的必备的能力。优秀的分层设计能够让整个数据体系更易理解和使用。想要做数仓,需要补一补数仓分层,才能知道分层的意义。
分层很重要,说一下我的理解。
一、 分层基础
1.理清业务数据
随着数据量和业务数据表的不断扩张,需要我们理清数据作用域,这样可以清晰的找到数据来源。
2.避免重复计算
为了避免多次计算,多次关联多张表。分层可以保存中间结果,减小开发成本。避免每次查询都要从原始表计算。
3.增加数据使用便捷性
仓库层的设计,让数据能分析,好分析,能支持大部分的数据需求。每种需求都能从分层中找到自己需要的数据。
4.避免数据分歧
统一数据口径,保证数据质量,避免出现统一指标多种概念。
5.通用分层
比较通用的简单的维度建模分层,分为三层:
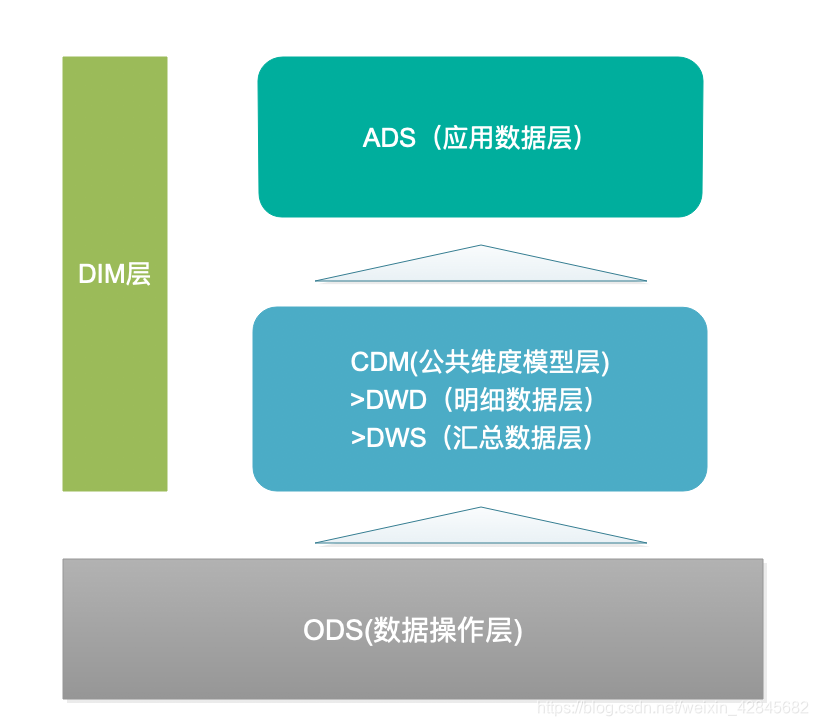
(图片来源于网络,侵删)
二、 ODS层,操作数据层
把操作系统的数据几乎无处理的存放在数仓中,主要有以下工作:
1.将业务结构化数据增量或全量的同步进来;
2.将日志等非结构化的数据结构化处理后落地到数仓中;
3.累计历史数据,根据数据业务需求、审计等要求保存历史数据、清洗数据,保留的数据快照也便于回溯问题。
二、CDM层,公共维度模型层
存放明细事实数据、维度数据及公共指标汇总数据,统一口径,保持数据一致性,减少数据重复计算,CDM层分为DWD层和DWS层。
1.DWD层,明细数据层
dwd层对业务数据进行清洗、规范化,例如去除作弊数据,对数据字段进行规范命名从而避免歧义化等,另外可采用维度退化手段,将维度退化到事实表中,减少事实表与维度表的关联,提高明细表的易用性。
2.DWS层,汇总数据层
dws层,加强指标的维度退化,采用更多的宽表化的手段构建公共指标数据层,提升公共指标的复用性,减少重复加工。
三、ADS层,应用数据层
ads层存放数据进行个性化的指标计算,不共用性、复杂性(指数型、比值型、排名型)等,会基于应用数据组装,像大宽表集市、横标转纵表、趋势指标串等,另外由于ADS某些指标具有个性化的特点,尽量不对外提供服务。
有点事,等会再写。
