1、范式理论
范式:表示一个关系内部各属性之间的联系的合理化程度,范式级别越高,表的设计就越标准。
参考网址:https://www.cnblogs.com/ktao/p/7775100.html
其实总结一点就是:为了降低冗余,拆分表,使属性之间的联系越紧密!!
2、关系建模和维度建模
关系建模:
面向应用,遵循第三范式,以消除数据冗余为目标的设计技术:
设计出来的样子应该是:

优点:降低了数据的冗余
缺点:查询大部分数据都需要join
维度建模:
①面向分析,为了提高查询性能可以增加数据冗余,反规范化的设计技术
②主要是按照事实表、维度表来构建数据仓库、数据集市,也就是说通过维度表对事实表进行注解!!
设计出来的样子应该是:

注:从关系建模的缺点来看,数据仓库是不适合关系建模方式的,因为大量的join会使得计算延迟,查询效率低。
3、维度建模
根据事实表和维度表的关系,又可将常见的维度模型分为星型模型、雪花型模型、星座模型。
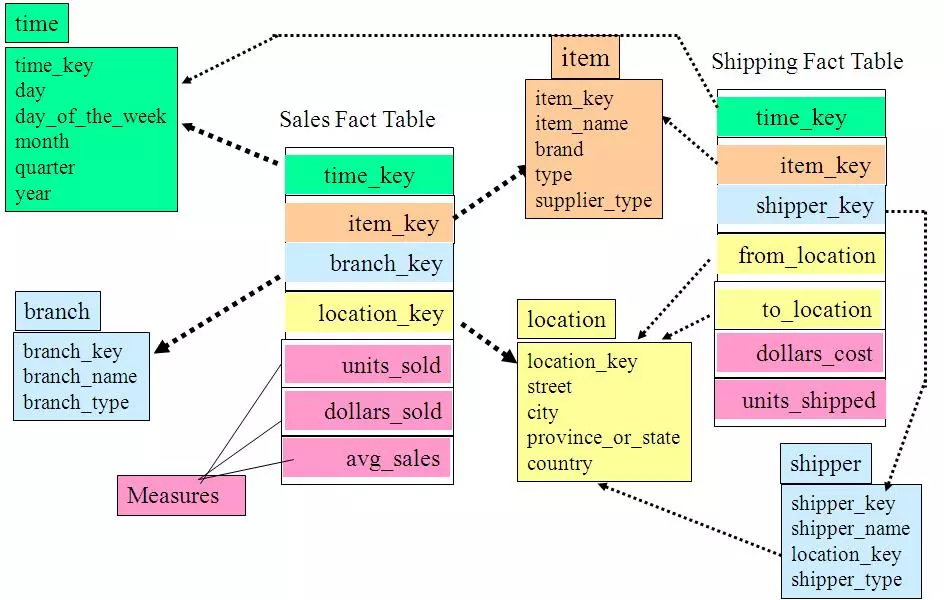
星型模型:
星型架构是一种非正规化的结构,多维数据集的每一个维度都直接与事实表相连接,不存在渐变维度,所以数据有一定的冗余
设计出来的样子应该是:
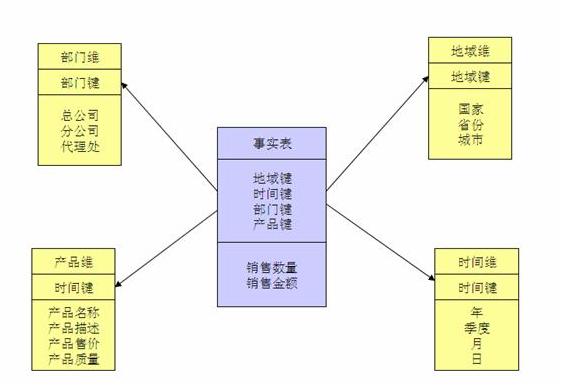
雪花模型:
星型模型因为数据的冗余所以很多统计查询不需要做外部的连接,因此一般情况下效率比雪花型模型要高。
星型结构不用考虑很多正规化的因素,设计与实现都比较简单。
雪花型模型由于去除了冗余,有些统计就需要通过表的联接才能产生,所以效率不一定有星型模型高
设计出来的样子应该是:
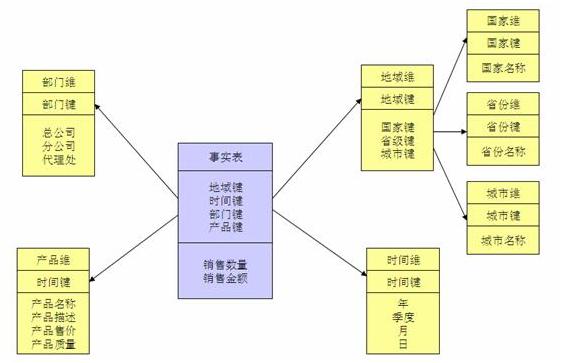
注:正规化也是一种比较复杂的过程,相应的数据库结构设计、数据的 ETL、以及后期的维护都要复杂一些。
因此在冗余可以接受的前提下,实际运用中星型模型使用更多,也更有效率。
星座模型
数据仓库由多个主题构成,包含多个事实表,而维表是公共的,可以共享,这种模式可以看做星型模型的汇集
设计出来的样子应该是: