一、数仓建模理论
(一)前言
数仓建模就好比是图书馆的书能够分门别类的存放,不仅合理,齐全,而且易于查找。
数据模型就是数据组织和存储方法,强调从业务、数据存取和使用角度合理存储数据。只有将数据有序的组织和存储起来,数据才能高性能、低成本、高效率、高质量的使用。
高性能:能够帮助我们快速查询所需要的数据。
低成本:能减少重复计算,实现计算结果的复用,降低计算成本。
高效率:能极大的改善用户使用数据的体验,提高使用数据的效率。
高质量:能改善数据统计口径的混乱,减少计算错误的可能性。
数据仓库具有面向主题的特性,那么就会有主题的概念,数仓建设遵循纵向分层开发,横向划分主题域设计。
(二)数仓建设步骤
1. 业务调研
数仓开发是承上对接业务研发侧&承下对接数据分析侧,在数仓建设前期要对上游业务过程和对下游数据分析指标体系有所了解和熟知,然后拉齐上下游沟通数据口径和数仓搭建。
2. 数据域划分
数仓数据域就是公司业务中联系较为密切的的数据主题的集合,一般可以根据业务过程、业务部门、业务系统来划分(比如订单域、问诊域、挂号域),一个数据域包含多个主题。
3. 主题划分
主题域的概念
主题域是对实体的逻辑分组,我们以上帝视角去看企业的业务系统,梳理企业的业务实体,实体与实体之间的关系,将企业中的数据进行逻辑划分。相同主题域中的数据联系紧密,不同主题域之间的数据相互独立。所以主题域的划分没有任何的技术含义,只是一种概念,能帮助数据使用者快速找到数据的一种分类方法。就像图书馆的图书分类一样,图书分类共分为22个大类:分为军事、文学、艺术等,比如文学又包含:小说、散文、诗歌、戏剧等。这些就是图书的主题域。
数仓主题就是在较高层次上将企业生产上的各个系统中某一分析对象的数据进行整合(比如用户主题、商品主题、患者主题)、归纳并分析的一种范围,一个主题就是一个实体对象。
主要是识别出分析对象主题,做主题划分和主题域划分,从全局视角来看,先划分出主题域,再在主题域中划分主题。
主题域的划分要谨慎划分,一旦确定下来避免频繁变动,虽然数仓建设是迭代建设的,不能保证一次性初始化好,但我们的主题域划分和主题划分要尽可能地涵盖企业的所有业务,以及在新业务进来时能够无影响地被包含进来和可扩展主题域。
4. 输出总线矩阵
即业务过程和维度,组建成的矩阵,就是维度建模涉及到的业务过程(事实表)和维度表。
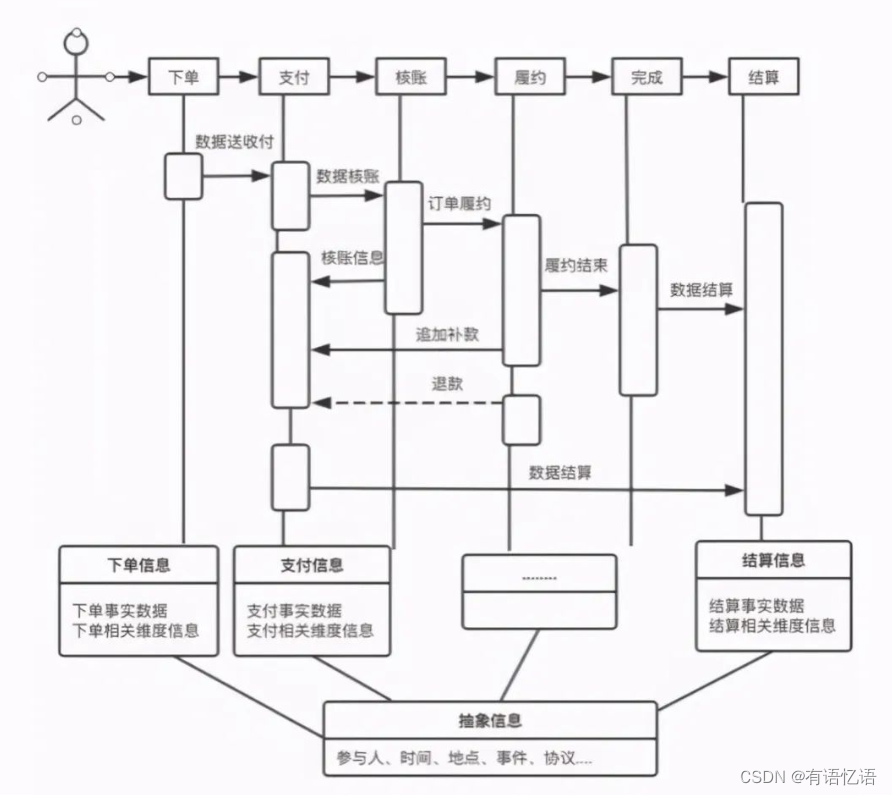

5. 数仓分层设计、模型表
看下文数仓分层、和模型表设计。
6. 数仓公共层表迭代升级
看下文介绍。
(三)数仓建模方法
1 关系模式范式
1.1 范式理论概述
关系型数据库设计时,遵照一定的规范要求,目的在于降低数据的冗余性,目前业界范式有:第一范式(1NF)、第二范式(2NF)、第三范式(3NF)、巴斯-科德范式(BCNF)、第四范式(4NF)、第五范式(5NF)。
范式的标准定义是:符合某一种级别的关系模式的集合,表示一个关系内部各属性之间的联系的合理化程度。通俗地讲,范式可以理解为一张数据表的表结构所符合的某种设计标准的级别。
使用范式的根本目的是:减少数据冗余,尽量让每个数据只出现一次,获取数据时通过join拼接出最后的数据。
1.2 范式基本概念
| 学号 |
姓名 |
系名 |
系主任 |
课名 |
分数 |
| 20170901176 |
王小强 |
计算机系 |
马小腾 |
C语言 |
95 |
| 20170901176 |
王小强 |
计算机系 |
马小腾 |
计算机基础 |
99 |
| 20170901176 |
王小强 |
计算机系 |
马小腾 |
高等数学 |
80 |
| 20170901179 |
李阳 |
经管系 |
王小石 |
经济学 |
95 |
| 20170901179 |
李阳 |
经管系 |
王小石 |
管理学 |
92 |
| 20170901186 |
张小俊 |
数学系 |
钱小森 |
高等数学 |
89 |
| 20170901186 |
张小俊 |
数学系 |
钱小森 |
线性代数 |
96 |
1) 函数依赖
若在一张表中,在属性(或属性组)X的值确定的情况下,必定能确定属性Y的值,那么就可以说Y函数依赖于X,写作 X → Y。
也就是说,在数据表中,如果符合函数依赖,那么不存在任意两条记录,它们在X属性(或属性组)上的值相同,而在Y属性上的值不同。这也就是“函数依赖”名字的由来,类似于函数关系 y = f(x),在x的值确定的情况下,y的值一定是确定的。
例如,对于表3中的数据,找不到任何一条记录,它们的学号相同而对应的姓名不同。所以我们可以说姓名函数依赖于学号,写作 学号 → 姓名。但是反过来,因为可能出现同名的学生,所以有可能不同的两条学生记录,它们在姓名上的值相同,但对应的学号不同,所以我们不能说学号函数依赖于姓名。
表中其他的函数依赖关系还有如:
系名 → 系主任
学号 → 系主任
( 学号,课名) → 分数
以下函数依赖关系则不成立:
学号 → 课名
学号 → 分数
课名 → 系主任
(学号,课名) → 姓名
2) 完全函数依赖
在一张表中,若 X → Y,且对于 X 的任何一个真子集(假如属性组 X 包含超过一个属性的话),X ' → Y 不成立,那么我们称 Y 对于 X 完全函数依赖,记做:

例如:
学号 F→ 姓名
(学号,课名) F→ 分数 (注:因为同一个的学号对应的分数不确定,同一个课名对应的分数也不确定)
3) 部分函数依赖
假如 Y 函数依赖于 X,但同时 Y 并不完全函数依赖于 X,那么我们就称 Y 部分函数依赖于 X,记做:

简单来说,(学号,课名)→ 系名,学号 → 系名,那么(学号,课名)p→ 系名。
4.)传递函数依赖
假如 Z 函数依赖于 Y,且 Y 函数依赖于 X ,且 Y不包含于 X,X 不函数依赖于 Y,那么我们就称 Z 传递函数依赖于 X,记做:

简单来说,系名 → 系主任,学号 → 系名,那么学号 T→ 系主任。
1.3 第一范式
一范式(1NF):域应该是原子性的,即数据库表的每一列都是不可分割的原子数据项。
不符合一范式的表格设计
| ID |
商品 |
商家ID |
用户ID |
| 001 |
5台电脑 |
XXX旗舰店 |
00001 |
很明显如图3-1所示的表格设计是不符合第一范式的,商品列中的数据不是原子数据项,是可以进行分割的,因此对表格进行修改,让表格符合第一范式的要求,修改结果如图所示:
| ID |
商品 |
数量 |
商家ID |
用户ID |
| 001 |
电脑 |
5 |
XXX旗舰店 |
00001 |
实际上,1NF是所有关系型数据库的最基本要求,你在关系型数据库管理系统(RDBMS),例如SQL Server,Oracle,MySQL中创建数据表的时候,如果数据表的设计不符合这个最基本的要求,那么操作一定是不能成功的。也就是说,只要在RDBMS中已经存在的数据表,一定是符合1NF的。
1.4 第二范式
二范式(2NF):在1NF的基础上,实体的属性完全函数依赖于主关键字(混合主键),不能存在部分函数依赖于主关键字(混合主键)。
如果存在某些属性只依赖混合主键中的部分属性,那么不符合二范式。
| 学生ID |
姓名 |
所属系 |
系主任 |
所修课程 |
分数 |
| 20170901176 |
王小强 |
计算机系 |
马小腾 |
000001 |
95 |
| 20170901176 |
王小强 |
计算机系 |
马小腾 |
000002 |
99 |
上述表格中是混合主键(学生ID + 所修课程),但是姓名、所属系和系主任这三个属性只依赖于混合主键中的学生ID这一个属性,因此,不符合第二范式。
如果有一天学生的所属系要调整,那么所属系和系主任这两列都需要修改,如果这个学生修了多门课程,那么表中的多行数据都要修改,这是非常麻烦的,不符合第二范式。
为了消除这种部分依赖,只有一个办法,就是将大数据表拆分成两个或者更多个更小的数据表。
表符合二范式的表格设计(1)
| 学生ID |
所修课程 |
分数 |
| 20170901176 |
000001 |
95 |
| 20170901176 |
000002 |
99 |
| 学生ID |
所属系 |
系主任 |
| 20170901176 |
计算机系 |
马小腾 |
| 学生ID |
姓名 |
| 20170901176 |
王小强 |
通过上述的修改,当一个学生的所属系需要调整时,不管学生修了多少门课程,都只需要改变上表中的一行数据即可。
1.5 第三范式
3NF在2NF的基础之上,消除了非主属性对于主键(复合主键)的传递依赖。
表3-6 不符合三范式的表格设计
| 订单ID |
商品ID |
商品颜色 |
商品尺寸 |
商家ID |
用户ID |
| 001 |
0001 |
深空灰 |
300*270*40 |
XXX旗舰店 |
00001 |
很明显,表3-7中,商品颜色依赖于商品ID,商品ID依赖于订单ID,那么非主属性商品颜色就传递依赖于订单ID,因此不符合三范式,解决方案是将大数据表拆分成两个或者更多个更小的数据表。
表3-7 符合三范式的表格设计(1)
| 订单ID |
商品ID |
商家ID |
用户ID |
| 001 |
0001 |
XXX旗舰店 |
00001 |
| 商品ID |
商品颜色 |
商品尺寸 |
| 0001 |
深空灰 |
300*270*40 |
2 ER实体关系模型
2.1 基本理论
ER模型是数据库设计的理论基础,当前几乎所有的OLTP系统设计都采用ER模型建模的方式。
在信息系统中,将事物抽象为“实体”、“属性”、“关系”来表示数据关联和事物描述;其中,实体:Entity,关系:Relationship,这种对数据的抽象建模通常被称为ER实体关系模型。
实体:通常为参与到过程中的主体,客观存在的,比如商品、仓库、货位、汽车,此实体非数据库的实体表;
属性:对主体的描述、修饰即为属性,比如商品的属性有商品名称、颜色、尺寸、重量、产地等;
关系:现实的物理事件是依附于实体的,比如商品入库事件,依附实体商品、货位,就会有“库存”的属性产生;用户购买商品,依附实体用户、商品,就会有“购买数量”、“金额”的属性产品。
2.2 实体之间的对照关系
实体之间建立关系时,存在对照关系:
1:1,即1对1的关系,比如实体人、身份证,一个人有且仅有一个身份证号;(A->B:相互完全依赖,知道A一定确定B,知道B一定确定A)。
(动静分离:在数据库设计时,会将动态属性(年龄、地址、偏好、...)和静态属性(姓名、性别、身份证号、...)进行分离,剥离为两张表,一张父表,一张子表,从而提高性能)。
1:n,即1对多的关系,比如实体学生、班级,对于某1个学生,仅属于1个班级,而在1个班级中,可以有多个学生;(一张学生表,一张班级表,通过班级ID这个外键进行关联)。
n:m,即多对多的关系,比如实体学生、课程,每个学生可以选修多门课程,同样每个课程也可以被多门学生选修;(一张学生表,一张课程表,一张选课表)。
2.3 ER建模的图形表示
在日常建模过程中:
“实体”:使用矩形表示;
“关系”:使用菱形表示;
“属性”:使用椭圆形表示;
所以ER实体关系模型也称作E-R关系图。
3 ER实体建模实例
3.1. 场景
学生选课系统,该系统主要用来管理学生和选修课程,其中包括课程选修、学生管理功能,现需要完成数据库逻辑模型设计。
3.2. 实现步骤
1. 抽象出主体 —— 学生,课程;
2. 梳理主体之间的关系 —— 选修;(学生与选修课程是一个多对多的关系)
3. 梳理主体的属性;
4. 画出E-R关系图;
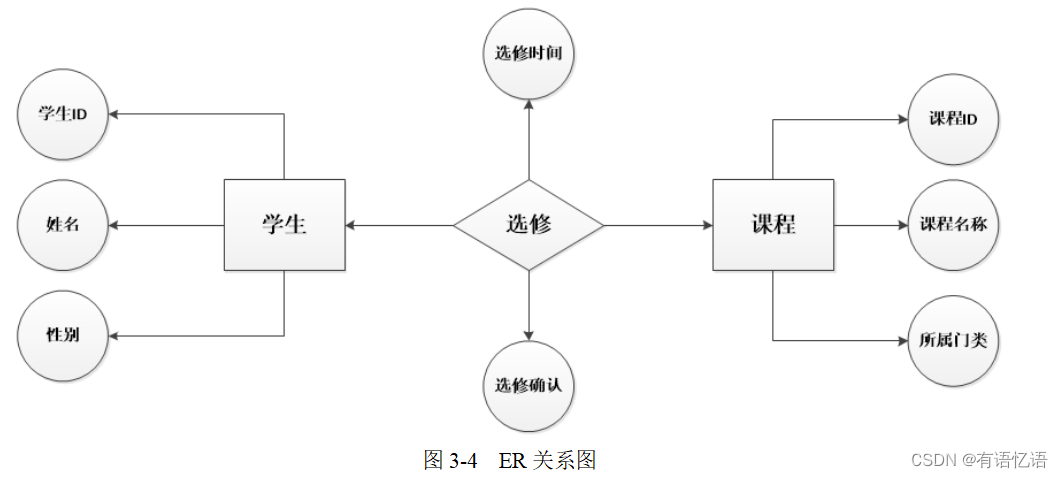
使用ER模型构建数据仓库的成功率是比较低的,因为涉及到“抽象出实体”这个过程,这就涉及到将企业所有业务系统中的所有实体都抽象出来,这需要先梳理出所有的业务系统实体,再梳理实体之间的关系,这是一个非常复杂的过程,可能你把公司所有的实体梳理清楚了,可能业务又要调整了。
这种建模方法的出发点是整合数据,其目的是将整个企业的数据进行组合和合并,并进行规范处理,减少数据冗余性,保证数据的一致性。这种模型并不适合直接用于分析统计。
4 维度模型
维度建模的理论由Ralph Kimball提出,他提出将数据仓库中的表划分为事实表和维度表两种类型。
维度建模源自数据集市,主要面向分析场景。
“事实表”,用来存储事实的度量(measure)及指向各个维的外键值。
“维度表”,用来保存该维的元数据,即维的描述信息,包括维的层次及成员类别等。
简单的说,维度表就是你观察该事物的角度(维度),事实表就是你要关注的内容。例如用户使用滴滴打车,那么打车这件事就可以转化为一个事实表,即打车订单事实表,然后用户对应一张用维度表,司机对应一张司机维度表。
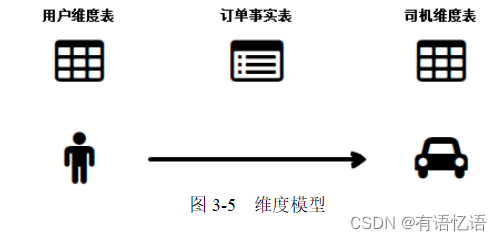
- 事实表
在现实世界中,每一个操作型事件,基本都是发生在实体之间的,伴随着这种操作事件的发生,会产生可度量的值,而这个过程就产生了一个事实表,存储了每一个可度量的事件。
发生在现实世界中的操作性事件所产生的可度量数值,存储在事实表中。从最低的粒度级别来看,事实表行对应一个度量事件,反之亦然。因此,事实表的设计完全依赖于物理活动,不受可能产生的最终报表的影响。除数字度量外,事实表总是包含外键,用于关联与之相关的维度,也包含可选的退化维度键和日期/时间戳。查询请求的主要目标是基于事实表展开计算和聚集操作。
事实表往往包含三个重要元素:
1. 维度表外键
2. 度量数据
3. 事件描述信息
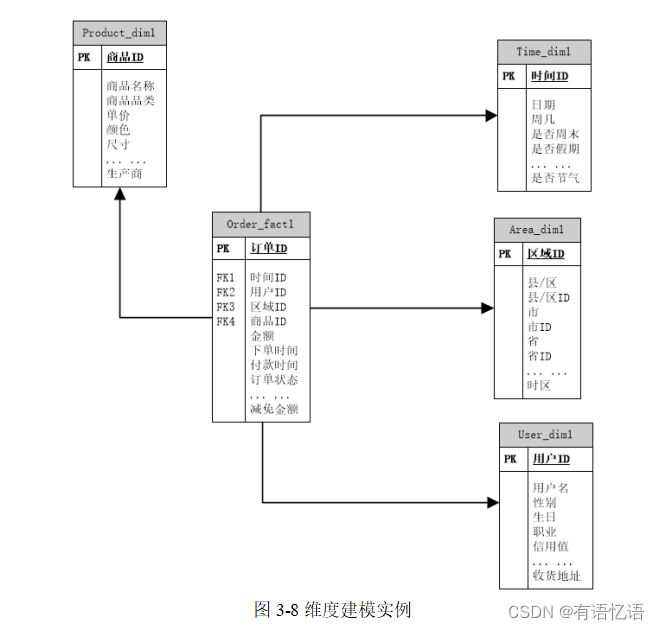
例如在电商场景中的一次购买事件,涉及主体包括客户、商品、商家,产生的可度量值包括商品数量、金额、件数等。

- 维度表
每个维度表都包含单一的主键列。维度表的主键可以作为与之关联的任何事实表的外键,当然,维度表行的描述环境应与事实表行完全对应。维度表通常比较宽,是扁平型非规范表,包含大量的低粒度的文本属性。
比如商品,单一主键为商品ID,属性包括产地、颜色、材质、尺寸、单价等,但并非属性一定是文本,比如单价、尺寸,均为数值型描述性的,日常主要的维度抽象包括:时间维度表、地理区域维度表等。

综上所述,如果针对用户的下单行为(单一商品)进行维度建模,我们可以得到如下模型:
(二)横向分层开发设计

(三)纵向划分主题域设计
数据仓库模型设计除横向的分层外,通常也需要根据业务情况进行纵向划分数据域。
划分数据域的意义是便于数据的管理和应用。
通常可以根据业务过程或者部门进行划分,本项目根据业务过程进行划分,需要注意的是一个业务过程只能属于一个数据域。
| 数据域 |
业务过程 |
| 交易域 |
加购、下单、取消订单、支付成功、退单、退款成功 |
| 流量域 |
页面浏览、启动应用、动作、曝光、错误 |
| 用户域 |
注册、登录 |
| 互动域 |
收藏、评价 |
| 工具域 |
优惠券领取、优惠券使用(下单)、优惠券使用(支付) |