二次代价函数
描述模型误差:二次代价函数表达式:
激活函数的梯度
越大,w的大小调整得越快,训练收敛得就越快。激活函数的梯度
越小,w的大小调整得越慢,训练收敛得就越慢。
sigmoid function函数:
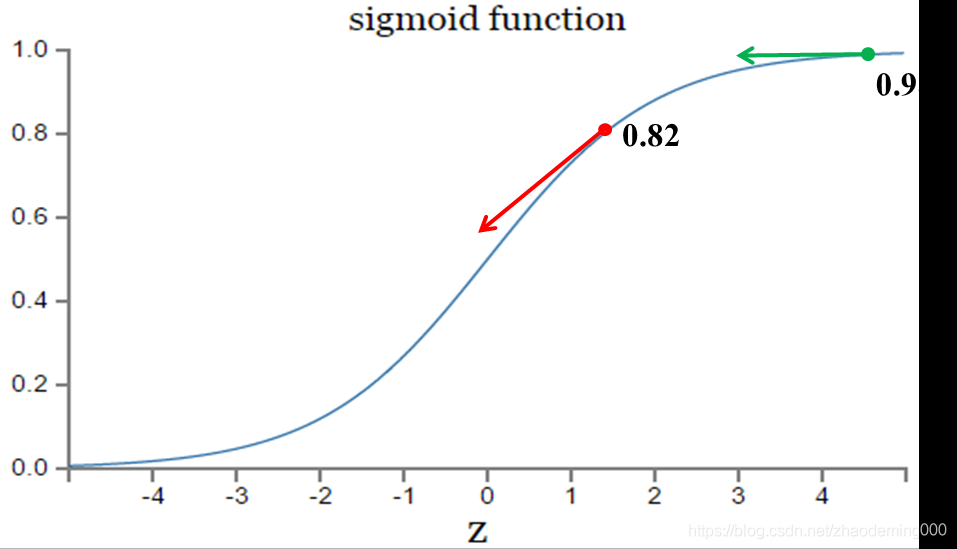
表明:只有在合适得位置上,函数收敛最佳。
交叉熵
在不改变激活函数时,改变代价函数,利用交叉熵代价函数:
由于sigmoid函数:
防止过拟合
1、增大数据集:随机裁剪、水平翻转、光照颜色抖动
2、early stopping:训练模型时,设置一个比较大的迭代次数。Early stopping是一种提前结束训练的策略防止过拟合。一般的做法是记录到目前为止最好的validation accuracy,当连续几次迭代没有达到最佳accuracy时,则认为accuracy不再提高,此时停止迭代,即为early stopping。
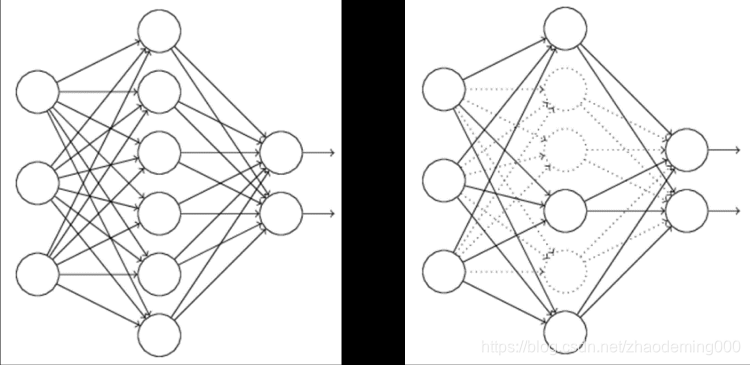
3、dropout:虚线代表神经元不参与更新和计算,每次训练时,随机选取一部分神经元不参与工作,选取百分比可以设置;
4、正则化项:在代价函数后面加上正则项,用于权衡正则项和
项的比重。
代表原始的代价函数,n代表样本的个数,
就是正则项系数,权衡正则项与
项的比重。
L1正则化:
L1正则化可以达到模型参数稀疏化的效果(稀疏化的含义是等于0)
L2正则化:
L2正则化可以使得模型的权值衰减,使模型参数值都接近于0。
有L1正则化和L2正则化,就是在代价函数中加入L1正则项和L2正则项,L1正则化是全部权重的绝对值平均,L2正则化是全部权重的均方,某些神经元的权重会被设置得特别小,甚至接近0,以减小过拟合情况。
交叉熵和tensorflow应用
// 载入数据集
mnist = input_data.read_data_sets("MNIST_data",one_hot=True)
// 对数据分批次
// 每个批次的大小
batch_size = 64
// 计算一共有多少个批次
n_batch = mnist.train.num_examples // batch_size
// 定义两个placeholder
// 代表的只是个占位符,在建立session,在会话中,运行模型时通过feed_dict函数向占位符喂入数据。
x = tf.placeholder(tf.float32,[None,784])
y = tf.placeholder(tf.float32,[None,10])
// 创建一个简单的神经网络
W = tf.Variable(tf.zeros([784,10]))
b = tf.Variable(tf.zeros([10]))
prediction = tf.nn.softmax(tf.matmul(x,W)+b)
// 交叉熵代价函数
# loss = tf.losses.mean_squared_error(y,prediction) // 二次代价函数
loss = tf.losses.softmax_cross_entropy(y,prediction) // 交叉熵代价函数
// 使用梯度下降法
train_step = tf.train.GradientDescentOptimizer(0.2).minimize(loss) // 优化器,有很多不同的类型
// 初始化变量
init = tf.global_variables_initializer()
// 结果存放在一个布尔型列表中
// tf.argmax(input, dimension, name=None)
// dimension=0 按列找
// dimension=1 按行找
// tf.argmax()返回最大数值的下标
// 通常和tf.equal()一起使用,计算模型准确度
// 判断,x, y 是不是相等,它的判断方法不是整体判断,而是逐个元素进行判断,如果相等就是True,不相等,就是False。
correct_prediction = tf.equal(tf.argmax(y,1),tf.argmax(prediction,1))
// argmax返回一维张量中最大的值所在的位置
// 求准确率
// tf.cast函数:将 x 的数据格式转化成 dtype
// tf.reduce_mean 函数用于计算张量tensor沿着指定的数轴(tensor的某一维度)上的的平均值,主要用作降维或者计算tensor(图像)的平均值。
accuracy = tf.reduce_mean(tf.cast(correct_prediction,tf.float32))
// 新建会话
with tf.Session() as sess:
// 会话初始化
sess.run(init)
// 迭代次数
for epoch in range(21):
for batch in range(n_batch):
// 获取batch_size大小的数据集,然后放在batch_xs中,把数据的标签放在batch_ys中
batch_xs,batch_ys = mnist.train.next_batch(batch_size)
sess.run(train_step,feed_dict={x:batch_xs,y:batch_ys})
acc = sess.run(accuracy,feed_dict={x:mnist.test.images,y:mnist.test.labels})
print("Iter " + str(epoch) + ",Testing Accuracy " + str(acc))
dropout
每次训练,隐藏层都只有部分神经元工作
# 初始化权重参数的时候采用截断正态分布,偏置项加常数,采用dropout防止过拟合,加三层隐层神经元
#定义三个placeholder
x = tf.placeholder(tf.float32,[None,784])
y = tf.placeholder(tf.float32,[None,10])
keep_prob=tf.placeholder(tf.float32)
# 784-1000-500-10 # 定义网络结构 dropout 训练的时候
# 从截断的正态分布中输出随机值
W1 = tf.Variable(tf.truncated_normal([784,1000],stddev=0.1))
b1 = tf.Variable(tf.zeros([1000])+0.1)
L1 = tf.nn.tanh(tf.matmul(x,W1)+b1)
L1_drop = tf.nn.dropout(L1,keep_prob) # dropout解决过拟合
W2 = tf.Variable(tf.truncated_normal([1000,500],stddev=0.1))
b2 = tf.Variable(tf.zeros([500])+0.1)
L2 = tf.nn.tanh(tf.matmul(L1_drop,W2)+b2)
L2_drop = tf.nn.dropout(L2,keep_prob)
W3 = tf.Variable(tf.truncated_normal([500,10],stddev=0.1))
b3 = tf.Variable(tf.zeros([10])+0.1)
prediction = tf.nn.softmax(tf.matmul(L2_drop,W3)+b3)
#交叉熵 交叉熵代价函数
loss = tf.losses.softmax_cross_entropy(y,prediction)
#使用梯度下降法 优化器
train_step = tf.train.GradientDescentOptimizer(0.5).minimize(loss)
# train_step = tf.train.AdamOptimizer(1e-2).minimize(loss) #使用adam优化器
#初始化变量
init = tf.global_variables_initializer()
#结果存放在一个布尔型列表中
correct_prediction = tf.equal(tf.argmax(y,1),tf.argmax(prediction,1))#argmax返回一维张量中最大的值所在的位置
#求准确率
accuracy = tf.reduce_mean(tf.cast(correct_prediction,tf.float32))
# 新建会话开始运行神经网络
with tf.Session() as sess:
sess.run(init)
for epoch in range(31):
for batch in range(n_batch):
batch_xs,batch_ys = mnist.train.next_batch(batch_size)
sess.run(train_step,feed_dict={x:batch_xs,y:batch_ys,keep_prob:0.5})
# keep_prob 百分比 对比上下程序结果,1 这个百分比的不是任何时候都可以的 2 这个百分比可以抵抗过拟合
test_acc = sess.run(accuracy,feed_dict={x:mnist.test.images,y:mnist.test.labels,keep_prob:1.0})
train_acc = sess.run(accuracy,feed_dict={x:mnist.train.images,y:mnist.train.labels,keep_prob:1.0})
print("Iter " + str(epoch) + ",Testing Accuracy " + str(test_acc) +",Training Accuracy " + str(train_acc))
正则项
正则化不一定会提供结果,复杂模型应用, 2 抵抗过拟合使用
正则化和Dropout应根据情况使用。。。交叉熵是肯定可以提高效果的
#正则项 的权值的累加
l2_loss = tf.nn.l2_loss(W1) + tf.nn.l2_loss(b1) + tf.nn.l2_loss(W2) + tf.nn.l2_loss(b2) + tf.nn.l2_loss(W3) + tf.nn.l2_loss(b3)
#交叉熵
loss = tf.losses.softmax_cross_entropy(y,prediction) + 0.0005*l2_loss
#使用梯度下降法
train_step = tf.train.GradientDescentOptimizer(0.5).minimize(loss)
优化器
tensorflow已经将常用优化算法封装,直接调用相应的优化器函数即可。
#交叉熵代价函数
# loss = tf.losses.softmax_cross_entropy(y,prediction) # 交叉熵代价函数
loss = tf.losses.mean_squared_error(y,prediction) # 二次代价函数
#使用梯度下降法
# train_step = tf.train.GradientDescentOptimizer(0.2).minimize(loss) # 梯度下降法优化器
train_step = tf.train.AdamOptimizer(0.001).minimize(loss) # aAdam优化器 更好
神经网络优化-自适应学习率
# 定义变量
lr = tf.Variable(0.001, dtype=tf.float32)
# adam优化器 进行训练 学习率是变量lr 随训练过程变化
train_step = tf.train.AdamOptimizer(lr).minimize(loss)
with tf.Session() as sess:
sess.run(init)
for epoch in range(21):
# 更新学习率
sess.run(tf.assign(lr, 0.001 * (0.95 ** epoch)))
for batch in range(n_batch):
batch_xs,batch_ys = mnist.train.next_batch(batch_size)
sess.run(train_step,feed_dict={x:batch_xs,y:batch_ys})
learning_rate = sess.run(lr)
acc = sess.run(accuracy,feed_dict={x:mnist.test.images,y:mnist.test.labels})
print ("Iter " + str(epoch) + ", Testing Accuracy= " + str(acc) + ", Learning Rate= " + str(learning_rate))
