反向传播(BP)算法:
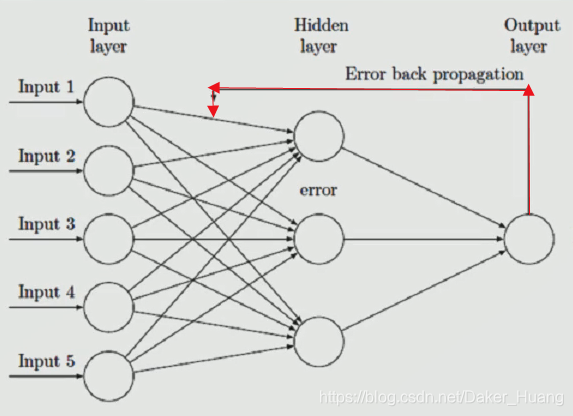
稍微明白神经网络是怎么回事的朋友都知道,神经网络分为三大层,输入层(input)、隐藏层(hidden)、输出层(output)。BP反向传播算法也就是多了上图中的红色箭头而已,这是一种简单的人工神经网络,当我们预测的值与真实值之间的差异较大时,我们就把这种差异附加到输入层与隐藏层之间的权重W和偏执项b上,通过每次更新W和b,产生不同的预测值,当预测值与真实值非常接近时,我们就可以停止这种迭代更新。
举例:
这是一张简单的三层神经网络图:
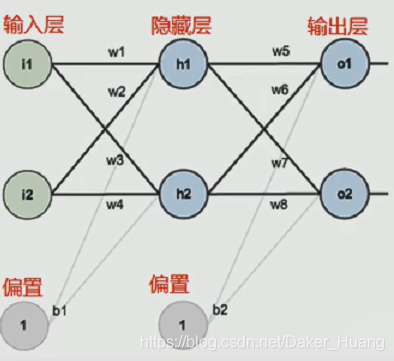
输入x为i1和i2,每条权重w为w1,w2,w3,w4,偏执项为b1,b2。
下面我们给这张图上的参数附上具体的数值:

先来看看h1:

然后对该结果使用激活函数,便是隐层的输出了。这个在后续文章会提到,这里主要使用sigmod函数:
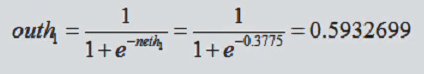
同样的道理,按照该逻辑,我们把上述每个节点的值计算出来,outh2的值:

然后利用outh1和outh2计算o1的值:

这样,简单的人工神经网络中就完成了。
那么,对于上图中的O1和O2,它本身就有一个真实值,而神经网络计算出来的值只是一个预测值,我们把这两项相减,即:
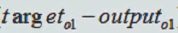
对与O1,整个神经网络的循环并不是只有一次,所有我们把它的所有误差相加,写成如下形式:

为什么要写成平方的形式并乘以(1/2)?,有时我们会对它进行最小二乘法求解操作,这样容易求导。而这仅仅是对于O1一个节点,输出节点并不是只有一个,所以,我们把所有节点的误差值相加,即:
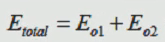
这个总的误差在进行第一次操作时,一点不会为0,如果为0,则说明这个神经网络没有搭建好,或者说这个神经网络已经是非常完美的,但是,目前领域内并没有这样的神经网络,不然,也不会出现几百层上千层的隐层,所以,该误差肯定是不为0的,既然如此,我们就需要把它尽可能的缩小。这是我们就反向更新,更新w和b的值,使得最终的误差越来越小:
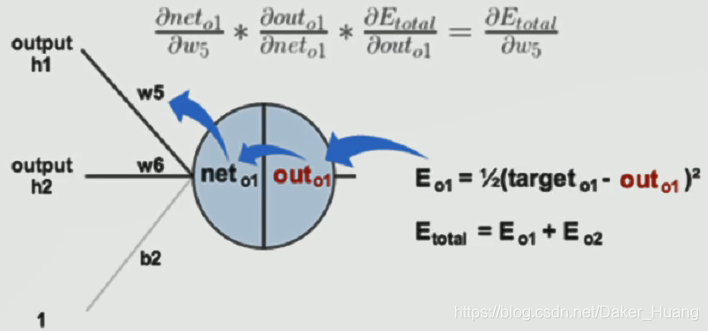
比如上图,我们想要更新w5和w6,就要用到这条偏导公式:
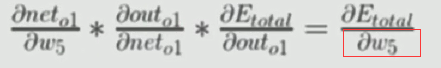
左式所有参数(左边的w5是上一次的值)都知道,右式总误差也知道,很容易的就能求出更新后的w5。比如,假定一些参数,计算得到:

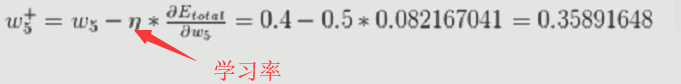
所以,最终w就更新完了。这里的“学习率”不能太高也不能太低,因为更新不能太快或太慢,否则过拟合或欠拟合就会很容易发生。
基于上述公式,我们一次一次的进行迭代更新,直到误差非常小(最好接近0)或迭代次数达到一定要求。而在tensorflow中已经帮我们做好了求导微分操作。
现在来实践一下,这里我使用minist数据集进行训练,下载网址:http://yann.lecun.com/exdb/mnist/
下载完之后解压,把所有文件放进项目包中,在pycharm中显示如下:
上图中的.gz文件不要解压,解压出来也不知道是个什么文件,直接放进去就好,tensorflow会自动解压。
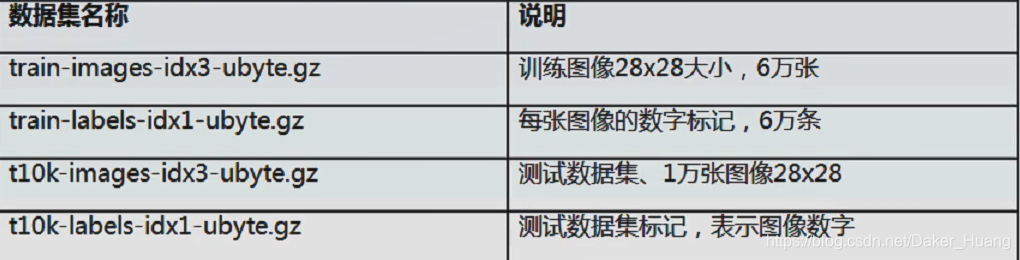
关于该数据集的说明:
下面再提一点:独热编码(one-hot):
因为是图片数据集,图片中的数字分别表示0-9,共10个数,所以,我们把它规定成如下形式:
| 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
|---|
上表中代表图片中的1,同理:
| 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
|---|
上表中代表图片中的2。从0开始,在表格中哪个位置就是几,这种方式被称为“one-hot”。
下面附上源码:
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
minist=input_data.read_data_sets(train_dir="minist/",one_hot=True) # one-hot开启
def gradient_bp():
number_hidden=50
x=tf.placeholder(shape=[None,784],dtype=tf.float32)
y=tf.placeholder(shape=[None,10],dtype=tf.float32)
'''---------第一层随机权重参数(w1,b1)-----------'''
w1=tf.Variable(tf.truncated_normal(shape=[784,number_hidden]))
b1=tf.Variable(tf.truncated_normal(shape=[1,number_hidden]))
'''---------第二层随机权重参数(w2,b2)-----------'''
w2 = tf.Variable(tf.truncated_normal(shape=[number_hidden, 10]))
b2 = tf.Variable(tf.truncated_normal(shape=[1, 10]))
'''---------也可以定义更多隐层,但对于人工神经网络来说,毫无意义,因为很容易发生过拟合或sigmod函数过饱和-----------------'''
nn1=tf.add(tf.matmul(x,w1),b1) # 第一次计算(输入层——>隐藏层)
h1=tf.sigmoid(nn1) #每一层计算后都需要使用一次激活函数
nn2=tf.add(tf.matmul(h1,w2),b2) # 第二次计算(隐藏层——>输出层)
out=tf.sigmoid(nn2)
diff=tf.subtract(y,out) # 真实值和预测值之间的差值
loss=tf.square(diff) # 把差值平方
step=tf.train.GradientDescentOptimizer(learning_rate=0.02) # 学习率
step=step.minimize(loss) # 最小化损失值
acc_mat=tf.equal(tf.argmax(y,1),tf.argmax(out,1)) # 求出真实值y、预测值out最大值的下标,tf.equal()求出真实值和预测值相等的数量,也就是预测结果正确的数量,tf.argmax()和tf.equal()一般是结合着用。
acc_ret=tf.reduce_sum(tf.cast(acc_mat,dtype=tf.float32))
with tf.Session() as sess:
sess.run(tf.global_variables_initializer()) # 初始化
for i in range(100000):
batch_xs,batch_ys=minist.train.next_batch(100) # 每一次批量读取30组数据,返回图片和标签
sess.run(step,feed_dict={x:batch_xs,y:batch_ys}) # 喂数据,并训练
if (i+1) % 10000==0:
'''-------------下面喂测试数据-------------'''
curr_acc=sess.run(fetches=acc_ret,feed_dict={x:minist.test.images[:1000],y:minist.test.labels[:1000]})
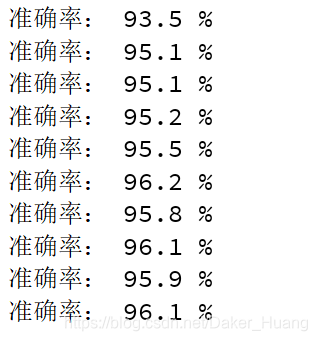
print("准确率:",(curr_acc/10),"%") #打印准确率
if __name__=="__main__":
gradient_bp()
有GPU的最好用GPU运算,这样速度快,没有的只能用CPU跑。
我训练10万次,最终的结果也才最高达到96%,而且中间有回落的情况。如下所示: