有这么一种情况,如果说我训练了一个数据集,效果还不错,但总不能每次都要经过一次训练在拿来用吧,一次训练能达到上万次,对于普通电脑来说根本不可能训练,所以我们要把它保存成一个模型文件(检查点),用到的时候直接拿来用就好了。
保存模型文件很简单,只需要用下面2句话就行了:
saver = tf.train.Saver()
saver.save(sess,save_path="checkpoint_model/",global_step=10000) #保存训练模型
1、训练并保存模型
下面以CNN的模型训练为例:
mnist = input_data.read_data_sets("mnist/", one_hot=True)
x = tf.placeholder(shape=[None, 784], dtype=tf.float32)
x_image = tf.reshape(x, shape=[-1, 28, 28, 1]) # 把一维reshape成2维,[-1,28,28,1]分别表示batch_size,28*28(高,宽)大小,灰度图像
y = tf.placeholder(shape=[None, 10], dtype=tf.float32) # 输出值
'''----------初始化第一次卷积核----------'''
conv_w1 = tf.Variable(tf.truncated_normal(shape=[5, 5, 1, 32], stddev=0.1),
dtype=tf.float32) # 滤波器, [5,5,1,32]分别表示使用5*5的采样大小,因为是灰度图,所以通道是为1,32表示用32个卷积核采用成32个的特征平面
conv_b1 = tf.Variable(tf.truncated_normal(shape=[32], stddev=0.1), dtype=tf.float32) # 32个平面就有32个偏置项
conv1_out = tf.nn.conv2d(input=x_image, filter=conv_w1, strides=[1, 1, 1, 1],
padding='SAME') # 卷积运算,strides=[1,1,1,1],strides[0]和strides[3]都是固定的,中间两个1表示步长为1,向右向下都往走1步
relu_conv1 = tf.nn.relu(tf.add(conv1_out, conv_b1))
'''---------第一层池化计算-----------------'''
pool_conv1 = tf.nn.max_pool(relu_conv1, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1],
padding="SAME") # ksize是窗口大小(2*2),步长为2
'''----------初始化第二次卷积核----------'''
conv_w2 = tf.Variable(tf.truncated_normal(shape=[5, 5, 32, 64], stddev=0.1),
dtype=tf.float32) # 滤波器,[5,5,32,64]分别表示使用5*5的采样大小,32表示32张灰度图,64表示用32个卷积核采用成64个的特征平面
conv_b2 = tf.Variable(tf.truncated_normal(shape=[64], stddev=0.1), dtype=tf.float32) # 32个平面就有32个偏置项
conv2_out = tf.nn.conv2d(input=pool_conv1, filter=conv_w2, strides=[1, 1, 1, 1],
padding='SAME') # 卷积运算,strides=[1,1,1,1],strides[0]和strides[3]都是固定的,中间两个1表示步长为1,向右向下都往走1步
relu_conv2 = tf.nn.relu(tf.add(conv2_out, conv_b2))
pool_conv2 = tf.nn.max_pool(relu_conv2, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1],
padding="SAME") # ksize是窗口大小(2*2),步长为2
'''
一张28*28的图片,经过第一层卷积之后,图像变成32张28*28的大小,第一次池化之后变成14*14大小
经过第二次卷积之后,图像变成64张14*14大小,第二次池化之后变成7*7大小
'''
# -------下面就是人工神经网络的应用了-------------
'''--------------第一层全连接层-------------'''
hidden_num1 = 100
hidden_num2 = 50
drouout_value = tf.placeholder(dtype=tf.float32)
fc_w1 = tf.Variable(tf.truncated_normal(shape=[7 * 7 * 64, hidden_num1], stddev=0.1), dtype=tf.float32)
fc_b1 = tf.Variable(tf.truncated_normal(shape=[hidden_num1]), dtype=tf.float32)
pool_conv2 = tf.reshape(pool_conv2, shape=[-1, 7 * 7 * 64]) # -1表示所有图片,相当于None
# --------------计算第一层(隐层)神经网络--------------
nn1 = tf.add(tf.matmul(pool_conv2, fc_w1), fc_b1)
out1 = tf.nn.dropout(tf.nn.relu(nn1), keep_prob=drouout_value) # 激活函数,并且加入dropout
'''--------------第二层全连接层-------------'''
fc_w2 = tf.Variable(tf.truncated_normal(shape=[hidden_num1, hidden_num2], stddev=0.1), dtype=tf.float32)
fc_b2 = tf.Variable(tf.truncated_normal(shape=[hidden_num2]), dtype=tf.float32)
# --------------计算第二层(隐层)神经网络--------------
nn2 = tf.add(tf.matmul(out1, fc_w2), fc_b2)
out2 = tf.nn.dropout(tf.nn.relu(nn2), keep_prob=drouout_value) # 激活函数,并且加入dropout
'''--------------第三层全连接层-------------'''
fc_w3 = tf.Variable(tf.truncated_normal(shape=[hidden_num2, 10], stddev=0.1), dtype=tf.float32)
fc_b3 = tf.Variable(tf.truncated_normal(shape=[10]), dtype=tf.float32)
# --------------计算第二层(隐层)神经网络--------------
nn3 = tf.add(tf.matmul(out2, fc_w3), fc_b3)
# ----------------计算loss-------------------
loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits_v2(labels=y, logits=nn3))
step = tf.train.GradientDescentOptimizer(learning_rate=0.03).minimize(loss) # 梯度下降优化器
# ---------------准确率----------------------
acc_mat = tf.equal(tf.argmax(y, 1), tf.argmax(nn3, 1)) # 返回的是True和False
acc_ret = tf.reduce_sum(tf.cast(acc_mat, dtype=tf.float32))
init = tf.global_variables_initializer()
saver = tf.train.Saver()
with tf.Session() as sess:
batch_size = 128
sess.run(init)
for i in range(10000):
batch_xs, batch_ys = mnist.train.next_batch(batch_size)
sess.run(step, feed_dict={x: batch_xs, y: batch_ys, drouout_value: 0.6})
print("训练第" + str(i) + "次")
if (i + 1) % 100 == 0:
curr_acc, curr_loss = sess.run([acc_ret, loss],
feed_dict={x: mnist.test.images[:1000], y: mnist.test.labels[:1000],
drouout_value: 1.0})
print("第" + str((i + 1) // 100) + "次:", "准确值:", curr_acc / 10, "%", "损失值:", curr_loss)
saver.save(sess,save_path="checkpoint_model/",global_step=10000) #保存训练模型
运行结果:
可以看到,在项目中已经有了该文件夹。
2、获取要预测的图片
可以自己手写几张图片,但有点麻烦,这里从mnist的测试集中获取几张来预测,测试集并没有经过测试。这里需要把mnist数据集转成图片:
def image_show(): # 把mnist数据集中的测试集部分转化成图片
for i in range(100):
im = mnist.test.images[i:(i + 1)] # 只取100张
label = mnist.test.labels[i:(i + 1)]
index = np.argmax(label, 1)[0] # 取标签
im = np.reshape(im, [28, 28]) # 原来是经过了one-hot变成了1*784,现在要变回28*28
cv.normalize(im, im, 0, 255, cv.NORM_MINMAX)
cv.imwrite("F:/mnist_test_image/" + str(index) + "_" + str(i) + ".png", np.uint8(im))
运行结果:

3、使用模型文件进行预测
def test_and_use_checkpoint():
with tf.Session() as sess:
saver.restore(sess, save_path=tf.train.latest_checkpoint("checkpoint_model/")) # 使用保存的模型
'''------读测试图片的操作-------'''
path = "F:/mnist_test_image/" # 图片所在的目录
file = os.listdir(path) #放进数组中
predict=tf.argmax(nn3, 1) # 预测值
count=0
for f in file:
if os.path.isfile(os.path.join(path,f)): # 文件存在
splitext_f=os.path.splitext(f) # 获取文件全名,以便后面能分割扩展名
name,type=splitext_f # 返回两个值,一个是文件名,一个是扩展名
if type==".png":
input_data=cv.imread(os.path.join(path,f),0) #读取灰度图
input_x=np.reshape(input_data,newshape=[1,784])/255 #转成1行784列,归一化
predict_value=sess.run(predict,feed_dict={x:input_x,drouout_value:1.0})
print("预测值:",predict_value[0],"真实值:",name[0])
if str(predict_value[0])==name[0:1]:
count+=1
print("预测准确率为:%s"%(count/100))
运行结果:
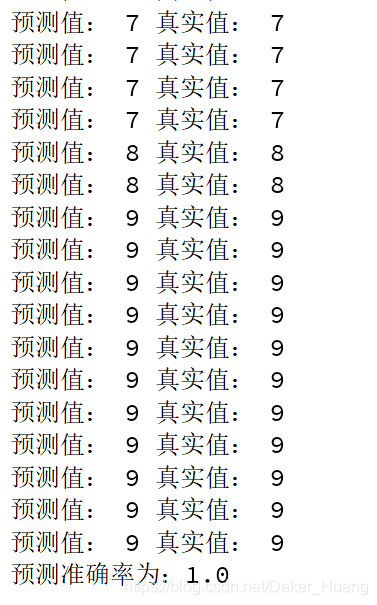
因为预只预测了100张,所以可能有偶然性,但是全部都识别了,准确率100%,读取模型进行预测不需要怎么耗时,0.5左右秒就能出结果。
附上所有源码:
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
import cv2 as cv
import numpy as np
import os
mnist = input_data.read_data_sets("mnist/", one_hot=True)
x = tf.placeholder(shape=[None, 784], dtype=tf.float32)
x_image = tf.reshape(x, shape=[-1, 28, 28, 1]) # 把一维reshape成2维,[-1,28,28,1]分别表示batch_size,28*28(高,宽)大小,灰度图像
y = tf.placeholder(shape=[None, 10], dtype=tf.float32) # 输出值
'''----------初始化第一次卷积核----------'''
conv_w1 = tf.Variable(tf.truncated_normal(shape=[5, 5, 1, 32], stddev=0.1),
dtype=tf.float32) # 滤波器, [5,5,1,32]分别表示使用5*5的采样大小,因为是灰度图,所以通道是为1,32表示用32个卷积核采用成32个的特征平面
conv_b1 = tf.Variable(tf.truncated_normal(shape=[32], stddev=0.1), dtype=tf.float32) # 32个平面就有32个偏置项
conv1_out = tf.nn.conv2d(input=x_image, filter=conv_w1, strides=[1, 1, 1, 1],
padding='SAME') # 卷积运算,strides=[1,1,1,1],strides[0]和strides[3]都是固定的,中间两个1表示步长为1,向右向下都往走1步
relu_conv1 = tf.nn.relu(tf.add(conv1_out, conv_b1))
'''---------第一层池化计算-----------------'''
pool_conv1 = tf.nn.max_pool(relu_conv1, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1],
padding="SAME") # ksize是窗口大小(2*2),步长为2
'''----------初始化第二次卷积核----------'''
conv_w2 = tf.Variable(tf.truncated_normal(shape=[5, 5, 32, 64], stddev=0.1),
dtype=tf.float32) # 滤波器,[5,5,32,64]分别表示使用5*5的采样大小,32表示32张灰度图,64表示用32个卷积核采用成64个的特征平面
conv_b2 = tf.Variable(tf.truncated_normal(shape=[64], stddev=0.1), dtype=tf.float32) # 32个平面就有32个偏置项
conv2_out = tf.nn.conv2d(input=pool_conv1, filter=conv_w2, strides=[1, 1, 1, 1],
padding='SAME') # 卷积运算,strides=[1,1,1,1],strides[0]和strides[3]都是固定的,中间两个1表示步长为1,向右向下都往走1步
relu_conv2 = tf.nn.relu(tf.add(conv2_out, conv_b2))
pool_conv2 = tf.nn.max_pool(relu_conv2, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1],
padding="SAME") # ksize是窗口大小(2*2),步长为2
'''
一张28*28的图片,经过第一层卷积之后,图像变成32张28*28的大小,第一次池化之后变成14*14大小
经过第二次卷积之后,图像变成64张14*14大小,第二次池化之后变成7*7大小
'''
# -------下面就是人工神经网络的应用了-------------
'''--------------第一层全连接层-------------'''
hidden_num1 = 100
hidden_num2 = 50
drouout_value = tf.placeholder(dtype=tf.float32)
fc_w1 = tf.Variable(tf.truncated_normal(shape=[7 * 7 * 64, hidden_num1], stddev=0.1), dtype=tf.float32)
fc_b1 = tf.Variable(tf.truncated_normal(shape=[hidden_num1]), dtype=tf.float32)
pool_conv2 = tf.reshape(pool_conv2, shape=[-1, 7 * 7 * 64]) # -1表示所有图片,相当于None
# --------------计算第一层(隐层)神经网络--------------
nn1 = tf.add(tf.matmul(pool_conv2, fc_w1), fc_b1)
out1 = tf.nn.dropout(tf.nn.relu(nn1), keep_prob=drouout_value) # 激活函数,并且加入dropout
'''--------------第二层全连接层-------------'''
fc_w2 = tf.Variable(tf.truncated_normal(shape=[hidden_num1, hidden_num2], stddev=0.1), dtype=tf.float32)
fc_b2 = tf.Variable(tf.truncated_normal(shape=[hidden_num2]), dtype=tf.float32)
# --------------计算第二层(隐层)神经网络--------------
nn2 = tf.add(tf.matmul(out1, fc_w2), fc_b2)
out2 = tf.nn.dropout(tf.nn.relu(nn2), keep_prob=drouout_value) # 激活函数,并且加入dropout
'''--------------第三层全连接层-------------'''
fc_w3 = tf.Variable(tf.truncated_normal(shape=[hidden_num2, 10], stddev=0.1), dtype=tf.float32)
fc_b3 = tf.Variable(tf.truncated_normal(shape=[10]), dtype=tf.float32)
# --------------计算第二层(隐层)神经网络--------------
nn3 = tf.add(tf.matmul(out2, fc_w3), fc_b3) #最后一层一般不做激活
# out3 = tf.nn.softmax(nn3) # 激活函数
# ----------------计算loss-------------------
loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits_v2(labels=y, logits=nn3))
step = tf.train.GradientDescentOptimizer(learning_rate=0.03).minimize(loss) # 梯度下降优化器
# ---------------准确率----------------------
acc_mat = tf.equal(tf.argmax(y, 1), tf.argmax(nn3, 1)) # 返回的是True和False
acc_ret = tf.reduce_sum(tf.cast(acc_mat, dtype=tf.float32))
init = tf.global_variables_initializer()
saver = tf.train.Saver()
'''
with tf.Session() as sess:
batch_size = 128
sess.run(init)
for i in range(10000):
batch_xs, batch_ys = mnist.train.next_batch(batch_size)
sess.run(step, feed_dict={x: batch_xs, y: batch_ys, drouout_value: 0.6})
print("训练第" + str(i) + "次")
if (i + 1) % 100 == 0:
curr_acc, curr_loss = sess.run([acc_ret, loss],
feed_dict={x: mnist.test.images[:1000], y: mnist.test.labels[:1000],
drouout_value: 1.0})
print("第" + str((i + 1) // 100) + "次:", "准确值:", curr_acc / 10, "%", "损失值:", curr_loss)
saver.save(sess,save_path="checkpoint_model/",global_step=10000) #保存训练模型
'''
def image_show(): # 把mnist数据集中的测试集部分转化成图片
for i in range(100):
im = mnist.test.images[i:(i + 1)] # 只取100张
label = mnist.test.labels[i:(i + 1)]
index = np.argmax(label, 1)[0] # 取标签
im = np.reshape(im, [28, 28]) # 原来是经过了one-hot变成了1*784,现在要变回28*28
cv.normalize(im, im, 0, 255, cv.NORM_MINMAX)
cv.imwrite("F:/mnist_test_image/" + str(index) + "_" + str(i) + ".png", np.uint8(im))
def test_and_use_checkpoint():
with tf.Session() as sess:
saver.restore(sess, save_path=tf.train.latest_checkpoint("checkpoint_model/")) # 使用保存的模型
'''------读测试图片的操作-------'''
path = "F:/mnist_test_image/" # 图片所在的目录
file = os.listdir(path) #放进数组中
predict=tf.argmax(nn3, 1) # 预测值
count=0
for f in file:
if os.path.isfile(os.path.join(path,f)): # 文件存在
splitext_f=os.path.splitext(f) # 获取文件全名,以便后面能分割扩展名
name,type=splitext_f # 返回两个值,一个是文件名,一个是扩展名
if type==".png":
input_data=cv.imread(os.path.join(path,f),0) #读取灰度图
input_x=np.reshape(input_data,newshape=[1,784])/255 #转成1行784列,归一化
predict_value=sess.run(predict,feed_dict={x:input_x,drouout_value:1.0})
print("预测值:",predict_value[0],"真实值:",name[0])
if str(predict_value[0])==name[0:1]:
count+=1
print("预测准确率为:%s"%(count/100))
if __name__ == "__main__":
test_and_use_checkpoint()
