CVPR2019 度量学习
Ranked List Loss for Deep Metric Learning
原文链接:https://arxiv.org/abs/1903.03238
度量学习在图像识别、检索等领域有着广泛应用。本文提出了一种新的方法,Ranked List Loss(RLL)。利用该损失函数可以小幅提升网络的准确性。话不多说,直接上图。
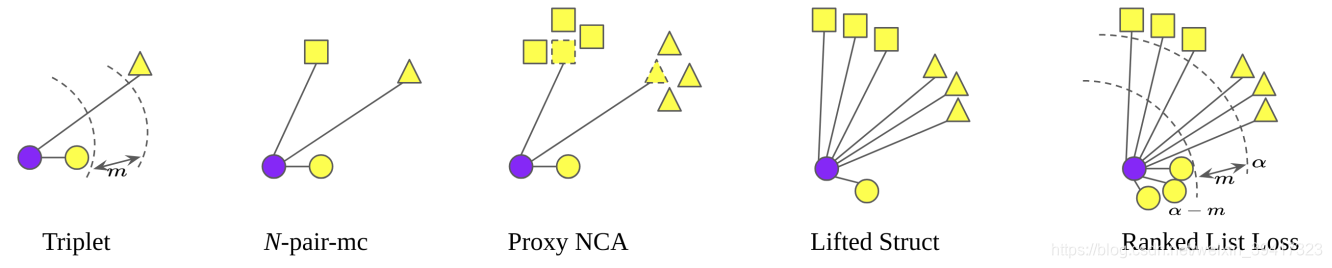
上图是几种常见的损失函数,最右侧的是本文算法。蓝色代表query,形状不同代表类别(标签)不同。按照顺序简介一下:
- 一个同类样本(positive)一个异类样本(negative)
- 每一类选取一个样本
- 一个positive,每一个negative类的平均
- 一个positive,所有的negative
- 所有的positive和negative
核心思想都是:让positive靠近,negative远离。
在此基础上,RLL还有一个特别之处,如下图:
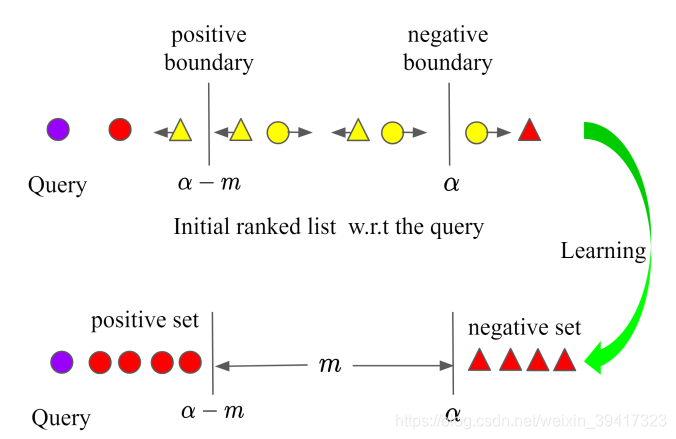
没有像其它算法那样,迫使positive的embeddings全部靠近于一点,而是使它们全部在以query的embedding为球心,以a-m为半径的超球面内。原因是,不希望模型过度自信。同时,让所有positive靠近于一点,也在一定程度上忽视或者破坏了positive的类内结构。通俗来说,好比一个大佬十分自信,而且他可能总是对的,但是如果错一次,往往非常打脸…
下面阐述一下算法流程:

很清晰了,如果懒得看论文,那就补充几点,方便看懂上述算法。
有些样本的embedding已经满足了图二的要求,所以没必要再进入loss中计算了,所以把它们删掉,于是pos set和neg set就分别变成了P * 和 N *。(但是我有一事不明,没必要删掉啊,如果满足图二的要求,那对应的loss就是0啊,也可能是我理解错了,欢迎大佬指教)。
T是另外一个超参数,用来给neg set中不同的样本设置权重。(也就是靠近query的neg的权重要大一些)。
附上算法中的公式:
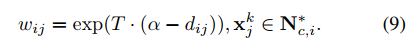
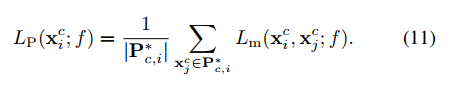
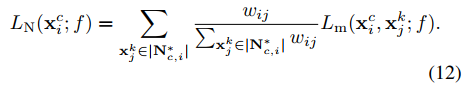
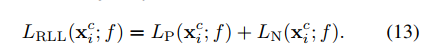
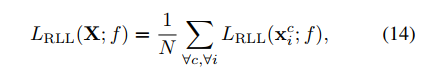
Lm:
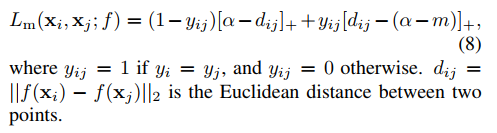
简而言之,就是batch中的每一个图片都作为query,然后分别计算pos set和neg set的损失,neg set中的样本要加权。然后LP和LN一视同仁,直接相加,得到一个query的loss。再把所有query的loss相加。
看到这里,大家也会发现,如果batchsize比较大,算法的运算量还是挺大的。
最后的实验分析证明,这个算法最有用的是不让类内距离过小。其它的比如给负样本加权,改进不大,个人认为是通过堆砌计算量而小幅(1%左右)提高准确率。
总之,用这个方法对自己的网络进一步小幅提升(不考虑计算量),还是不错的。
完
欢迎讨论,欢迎吐槽。
