1. 写在前面
如果是刚入深度学习的新手小白,可能有着只学习了一点深度学习的理论,也见识到了各种神经网络的强大而不能立马实现的烦恼,想学习TensorFlow,pytorch等出色强大的深度学习框架,又看到那代码晦涩难懂而有些想知难而退,这时候,我觉得有必要掌握一下Keras了,这是个啥? Keras是高级神经网络API,因为Keras短小精悍,非常适合快速原型制作和神经网络的搭建。在很短的时间内,就能够建立一个模型,以实现出色的结果,让神经网络的搭建像积木一样简单,更重要的一点学习深度学习网络,能快速实现,有满满的成就感,不仅可以增加对知识的理解,更可以给自己提供源源不断的学习动力。基于这些,想把自己学习Keras的经历整理一下,因为我也是小白学起,正好边学边整理。 最近又正好看了《将夜》,发现昊天世界的修炼等级名称比较有趣(初识,感知,不惑,洞玄,知命),所以为了增加趣味性,把Keras学习系列的名字和修炼级别关联起来了,因为我们学习本身就是一场修行。
深度学习框架经过更新很快,TensorFlow,Pytorch等传播盛行,但短小精悍的Keras在未来仍会占据一席之地,并长期占据下去
今天开始学习Keras,算是对Keras初识吧,今天主要是学习如何用Keras搭建神经网络模型并如何使用模型(教你快速搭建LeNet5,ResNet网络等)等,最后通过今天的学习简单的搭建一个小模型,完成一个简单的2分类任务感受一下,今天的实战任务不太强势,因为想先整理一下Keras的基础知识。
知识大纲:
- Keras的建立和使用(模型定义,模型配置,模型训练,模型预测评估及保存整套流程先走一边)
- Keras的模块细节(重点层次的介绍, 网络配置,预处理)
- 用Keras搭建神经网络实现简单的二分类
对于Keras,还需要知道,目前Keras已经更新到了2.3.0, 因为Keras是神经网络API,所以目前需要借助于那些框架作为后端: TensorFlow,theano等都支持Keras了。使用的时候,得先安装这些框架中的一种。
pip install tensorflow
pip install keras
# 更新numpy到最新版本
pip install -U numpy
学习过程中,如果有不懂的知识点,要记得参考官方文档:
- 中文文档:https://keras.io/zh/
- 官方文档:https://keras.io/
OK, let’s go!
2. Keras建立及使用流程
2.1 定义模型
首先我们要搭建神经网络的时候,要会定义模型,就好比搭积木,我们光有积木可不行,得在心中有一个最后搭建成什么样子的一个模型出来(比如我们想搭个房子,得有一个这样的房子目标,这样搭建完了之后我们才能用,这个房子就类似于模型的定义的东西。)
Keras定义模型由两种方式: 序列模型Sequential和Model, 差异在于不同的拓扑结构。下面具体来看看:(注意下面用到的各种层不懂没事,后面会介绍,相当于积木的各个模块,Keras已经实现好了,拿过来用就行了,先看看是怎么定义模型的)
-
序列模型Sequential
序列模型各层之间是依次顺序的线性关系,模型结构通过一个列表来制定或者采用.add的方式堆叠上去。意思就是说,我每个模块类似于往上直接堆叠,后面的输入就是前面的输出,不能有其他的结构了。这种方式非常简单,只需要把神经网络块摞起来就行。但是缺点就是如果神经网络结构不遵循线性关系,这种方式不能用。下面体会一下Keras的强大吧。 看看如何用Sequential搭建比较经典的网络LeNet5LeNet 提出于 1986 年,是最早用于数字识别的 CNN 网络,输入尺寸是 32 * 32。它输入的是灰度的图像,整个的网络结构是:输入层→C1 卷积层→S2 池化层→C3 卷积层→S4 池化层→C5 卷积层→F6 全连接层→Output 全连接层,对应的 Output 输出类别数为 10。 结构是这个样子:

先用列表的方式:
from keras.models import Sequential from keras.layers import Dense, Flatten from keras.layers import Conv2D, MaxPooling2D layers = [ # 第一层卷积层: 6个卷积核, 大小为5*5, relu激活函数 Conv2D(6, kernel_size=(5, 5), activation='relu', input_shape=(28, 28, 1)), # 第二层是最大池化层 MaxPooling2D(pool_size=(2,2), # 第三层卷积层: 16个卷积核, 大小5*5, relu激活函数 Conv2D(16, kernel_size=(5, 5), activation='relu'), # 第四层最大池化层 MaxPooling2D(pool_size=(2, 2)), # 第五层将参数扁平化, 在Lenet5中称为卷积,实际上这一层是一维向量,和全连接一样 Flatten(), Dense(120, activation='relu'), # 全连接层,输出节点个数为84个 Dense(84, activation='relu'), # 输出层 用softmax激活函数计算分类概率 Dense(10, activation='softmax') ] ## 建立模型 model = Sequential(layers)还可以逐层添加网络结构:
model = Sequential() # 第一层卷积层: 6个卷积核, 大小为5*5, relu激活函数 model.add(Conv2D(6, kernel_size=(5, 5), activation='relu', input_shape=(28, 28, 1))) # 第二层是最大池化层 model.add(MaxPooling2D(pool_size=(2,2))) # 第三层卷积层: 16个卷积核, 大小5*5, relu激活函数 model.add(Conv2D(16, kernel_size=(5, 5), activation='relu')) # 第四层最大池化层 model.add(MaxPooling2D(pool_size=(2, 2))) # 第五层将参数扁平化, 在Lenet5中称为卷积,实际上这一层是一维向量,和全连接一样 model.add(Flatten()) model.add(Dense(120, activation='relu')) # 全连接层,输出节点个数为84个 model.add(Dense(84, activation='relu')) # 输出层 用softmax激活函数计算分类概率 model.add(Dense(10, activation='softmax'))是不是有种堆积木的感觉呢?可以用model.summary()看一下模型结构:

-
通用模型Model
序贯模型的好处是简单操作,真的和搭积木一样一层层的往上搭就行,但是神经网络的结构只能是线性的才行,没法搭建出复杂的神经网络,而通用模型可以设计非常复杂、任意拓扑结构的神经网络,例如有向无环网络、共享层网络等。相比于序列模型只能依次线性逐层添加,通用模型能够比较灵活地构造网络结构,设定各层级的关系。下面看看如何用Model搭建一个挺复杂的网络,我从论文里面随便截了个图:
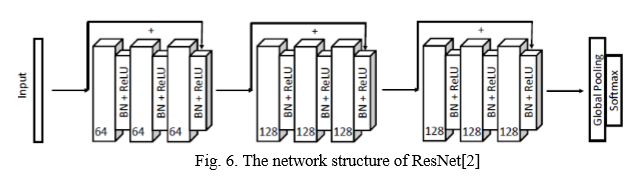
这个看起来挺复杂吧,万一你想实现呢? 有了Keras,一切皆有可能。# 确定好输入,注意指定输入形状 x = Input(shape=(input_shape)) # 这个input_shape得自己根据情况指定 # 卷积层的搭建 # 第一个卷积层模块 conv_x = Conv2D(filters=64, kernel_size=(8,1), padding='same')(x) conv_x = BatchNormalization()(conv_x) conv_x = Activation('relu')(conv_x) conv_y = Conv2D(filters=64, kernel_size=(5,1), padding='same')(conv_X) conv_y = BatchNormalization()(conv_y) conv_y = Activation('relu')(conv_y) conv_z = Conv2D(filters=64, kernel_size=(3, 1), padding='same')(conv_y) conv_z = BatchNormalization()(conv_z) # 跳远连接 is_expand_channels = not (input_shape[-1] == 64) # 得保证维度 if is_expand_channels: shortcut_y = Conv2D(filters=64, kernel_size=(1, 1), padding='same')(x) shortcut_y = BatchNormalization()(shortcut_y) else: shortcut_y = BatchNormalization()(x) y = Add()([shortcut_y, conv_z]) # 跳远连接 y = Activation('relu')(y) """上面实现了第一个卷积层模块了,第二个,第三个卷积层模块和上面基本一样,就是参数改改就OK,下面跳过去了,太多了要不然,作为例子,不用那么多,直接就是最后池化,然后输出""" full = GlobalAveragePooling2D()(y) out = Dense(class_num, activation='softmax')(full) # 建立模型 ResNet = Model(inputs=x, outputs=out)
2.2 定义模型的相关配置(model.compile)
模型定义好了,相当于积木已经搭建完成,下面就是训练之前,要对模型进行一下配置,选择优化器和损失函数。
Model.compile(optimizer, loss, metrics=[], loss_weights=None, sample_weight_mode=None)
参数简单看一下:

拿手写数字识别的例子:
model.compile(loss=keras.metrics.categorical_crossentropy, optimizer=keras.optimizers.Adam(), metrics=['accuracy'])
更多配置信息见下面的细节部分。
2.3 模型的训练(model.fit)
把相关配置说好了之后,下面就可以进行模型的训练了。
Model.fit(x, y, batch_size=32, nb_epoch=10, verbose=1, callbacks=[], validation_split=0.0, validation_data=None, shuffle=True, class_weight=None, sample_weight=None)
参数看一下:

还是拿手写数字识别的例子:
"""训练"""
model.fit(train_x, train_y, batch_size=128, epochs=20, verbose=1, validation_data=(test_x, test_y))
2.4 模型预测和评估(model.predict和model.evaluate)
模型训练好了之后,就可以进行预测和评估了
Model.predict(self, x, batch_size=32, verbose=0), 返回预测值的numpy array
Model.evaluate(x, y, batch_size=32, verbose=1, sample_weight=None)
举例:
"""对结果进行评估"""
score = model.evaluate(test_x, test_y)
print('误差: %.4lf' % score[0])
print('准确率: ', score[1])
2.5 模型的保存(model.save)与重新加载(load_model)
训练完了之后,一般需要保存模型,毕竟训练一遍不容易,总不能每次新打开都训练吧,所以我们最好是把模型给保存起来,下一次预测时候直接调过来用就可以了。
- 模型的保存
Model.save(self, filepath, overwrite=True, include_optimizer=True)
返回一个HDF5文件。包含:模型的结构(以便重构该模型)、模型的权重、训练配置(损失函数,优化器等)、优化器的状态(以便于从上次训练中断的地方开始)
model.save('my_model.h5')
- 模型的加载:
keras.models.load_model(filepath, custom_objects=None, compile=True)
from keras.models import load_model
model = load_model('my_model.h5')
哈哈,上面就是用Keras搭建神经网络的一整套流程了,简单总结一下,用Keras搭建神经网络,步骤如下:
- 首先需要定义模型,这个有两种定义方式,序列模型方式Sequential简单易操作,但搭建的模型结构同样简单,线性的才可以。 通用模型Model方式也不是那么复杂,并且可以定义强大结构的神经网络,小建议就是后者了。
- 有了model,下面就是进行配置,model.compile(),这里面会指定损失函数,指定优化器,评估标准等(有关模型的超参数在这里设置)
- 配置好模型,就可以model.fit()训练,这里面数据集,迭代次数,batch_size等(有关训练的参数在这里设置)
- 训练好模型,就可以进行预测和评估的任务了model.predict(), model.evaluate()
- 最后,别忘了model.save()保存模型
- 当有新的预测要做时,只需要kerars.models.load_model()即可
是不是比较简单啊,是不是按捺不住体内的洪荒之力,想把之前学习过的网络结构统统先实现一遍再说? 先别慌,上面流程中直接用到了一些模块,比如Conv2D, MaxPooling2D,Dense,Flatten等。
下面得对这些重点层做一些讲解,对这些模块了解了,才能更好的实现神经网络。
3. Keras的细节介绍
3.1 重点层次介绍
Keras的层很多,这里只对上面几个简单介绍一下,具体的还得参考官方文档。
-
二维卷积层Conv2D
二维卷积层,即对图像的空域卷积。该层对二维输入进行滑动窗卷积,当使用该层作为第一层时,应提供input_shape参数。例如input_shape = (128,128,3)代表128*128的彩色RGB图像(data_format=‘channels_last’).Conv2D(filters, kernel_size, activation=None) 创建, 其中 filters 代表卷积核的数量,kernel_size 代表卷积核的宽度和长度,activation 代表激活函数。如果创建的二维卷积层是第一个卷积层,需要提供 input_shape 参数
卷积的根本目的是从输入图片中提取特征。
-
最大池化层MaxPooling2D
空间池化(也叫亚采样或下采样)降低了每个特征映射的维度,但是保留了最重要的信息。空间池化可以有很多种形式:最大(Max),平均(Average),求和(Sum)等等。
看下面示意图: 最大池化就是选取最大的数,而平均池化就是计算平均数作为最后结果AveragePooling2D。

MaxPooling2D(pool_size=(2, 2)) 进行创建,其中 pool_size 代表下采样因子,比如 pool_size=(2,2) 的时候相当于将原来 22 的矩阵变成一个点,即用 22 矩阵中的最大值代替,输出的图像在长度和宽度上均为原图的一半
池化的功能是逐步减少输入表征的空间尺寸。特别地,池化
- 使输入表征(特征维度)更小而易操作
- 减少网络中的参数与计算数量,从而遏制过拟合
- 增强网络对输入图像中的小变形、扭曲、平移的鲁棒性(输入里的微小扭曲不会改变池化输出——因为我们在局部邻域已经取了最大值/平均值)。
- 帮助我们获得不因尺寸而改变的等效图片表征。这非常有用,因为这样我们就可以探测到图片里的物体,不论那个物体在哪。
-
Flatten 层
Flatten层用来将输入“压平”,即把多维的输入一维化,常用在从卷积层到全连接层的过渡。Flatten不影响batch的大小。model = Sequential() model.add(Convolution2D(64, 3, 3, border_mode='same', input_shape=(3, 32, 32))) # now: model.output_shape == (None, 64, 32, 32) model.add(Flatten()) # now: model.output_shape == (None, 65536)=64*32*32,压平了 -
Dense层
全连接层(对上一层的神经元进行全部连接,实现特征的非线性组合)
Dense就是常用的全连接层,所实现的运算是output = activation(dot(input, kernel)+bias)。其中activation是逐元素计算的激活函数,kernel是本层的权值矩阵,bias为偏置向量,只有当use_bias=True才会添加。# as first layer in a sequential model: model = Sequential() model.add(Dense(32, input_shape=(16,))) #input_shape=(16,)等价 于input_dim=16 # now the model will take as input arrays of shape (*, 16) ,输入维 度=16 # and output arrays of shape (*, 32) ,输出维度=32“全连接”表示上一层的每一个神经元,都和下一层的每一个神经元是相互连接的。
加入全连接层也是学习特征之间非线性组合的有效办法。卷积层和池化层提取出来的特征很好,但是如果考虑这些特征之间的组合,就更好了。 -
BatchNormalization层
该层在每个batch上将前一层的激活值重新规范化,即使得其输出数据的均值接近0,其标准差接近1由于在训练神经网络的过程中,每一层的 params是不断更新的,由于params的更新会导致下一层输入的分布情况发生改变,所以这就要求我们进行权重初始化,减小学习率。这个现象就叫做internal covariate shift。虽然可以通过whitening来加速收敛,但是需要的计算资源会很大。而Batch Normalizationn的思想则是对于每一组batch,在网络的每一层中,分feature对输入进行normalization,对各个feature分别normalization,即对网络中每一层的单个神经元输入,计算均值和方差后,再进行normalization。对于CNN来说normalize “Wx+b”而非 “x”,也可以忽略掉b,即normalize “Wx”,而计算均值和方差的时候,是在feature map的基础上(原来是每一个feature)
这些层都在keras.layers里面,层太多,没法一一介绍,只能用的时候查阅官方文档,不过,看到一篇博客,把所有的层写成了导图的方式,所以借用了一下,方便以后查阅,算是对所有层做一个总结吧:
3.2 keras网络配置
这一块直接使用参考博客里面的一个图作为整理
其中回调函数callbacks应该是keras的精髓~
3.3 keras预处理功能
3.4 模型可视化
-
model.summary(): prints the details of your layers in a table with the sizes of its inputs/outputs(在表中打印各层的详细信息及其输入/输出的大小)
-
plot_model(): plots your graph in a nice layout. You can even save it as “.png” using SVG() if you’d like to share it on social media. It is saved in “File” then “Open…” in the upper bar of the notebook.(画出结构图)
plot_model(happyModel, to_file='HappyModel.png') SVG(model_to_dot(happyModel).create(prog='dot', format='svg'))
3.5 模型的节点信息提取
可以进行模型的迁移训练
# 节点信息提取
config = model.get_config() # 把model中的信息,solver.prototxt和train.prototxt信息提取出来
model = Model.from_config(config) # 还回去
# or, for Sequential:
model = Sequential.from_config(config) # 重构一个新的Model模型,用去其他训练,fine-tuning比较好用
关于更多的细节信息,可以参考Sequential与Model模型、keras基本结构功能(一)
4. 用Keras搭建神经网络实现简单的二分类
这个任务没有什么特别的意义,就是简单的用一下Keras搭建网络,就当消化一下上面的知识吧:
import numpy as np
from keras.models import Sequential
from keras.layers import Dense, Activation
# 随机产生数据
data = np.random.random((1000, 100))
labels = np.random.randint(2, size=(1000, 1))
# 创建模型
model= Sequential()
model.add(Dense(32, activation='relu', input_dim=100))
# Dense(32) is a fully-connected layer with 32 hidden units.
model.add(Dense(1, activation='sigmoid'))
model.compile(optimizer='rmsprop',
loss='binary_crossentropy',
metrics=['accuracy'])
# 模型训练
model.fit(data, labels, epochs =10, batch_size=32)
结果如下:

这里多说一句,如果把上面最后一层的sigmoid换成softmax,Dense的个数换成2的时候,会报“Error when checking target: expected dense_37 to have shape (None, 2) but got array with shape (200, 1)”的一种错误, 这是因为softmax使用的时候,需要把labels用keras.utils.to_categorical进行独热编码之后才可以。
由于是随机产生的数据集,可能效果并不是那么好,但是你能看到在训练阶段正确率在提高,损失会降低。
这个例子是不是可以说明,想要实现一个神经网络,用Keras可以秒搭。 可以自己玩玩别的网络。
5. 总结
今天是Keras的初识境,主要是认识了一下Keras是个什么东西,究竟可以实现什么样的功能。下面简单的回顾一下,首先知道了Keras是个神经网络的高度API,用它可以像搭积木一样的实现神经网络模型。 然后学习了如何用Keras定义和使用神经网络模型。 然后就是学习了各种层的简介(具体看官方文档),最后用Keras实现了简单的二分类的项目。 这个项目没有什么太大的意义,只是为了消化一下知识,算是个小热身吧。
在Keras的感知境,将会通过今天的这些知识,用上面的两种方式搭建AlexNet神经网络做手写数字识别了,据说这个是深度学习界的Hello World级别,所以这个可不能不会。 手写数字识别任务能基本上把今天学习的所有知识过一遍,这样就相当于真正的实现了一下,所以暂且放到感知境吧,恭喜,学习了今天的知识,离破镜就不远了。
参考:
