##前情提要##
###一、神经网络介绍###
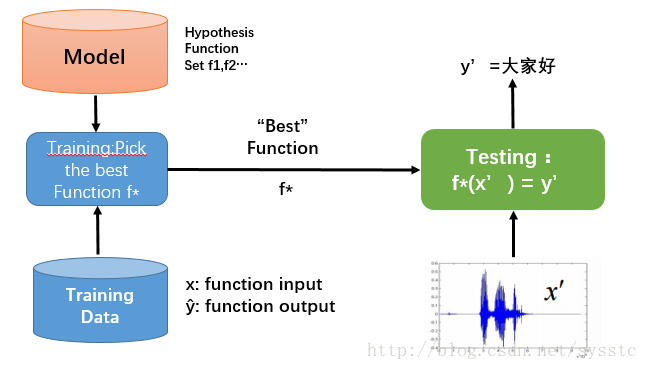
- 概念:Learning ≈ Looking for a Function
- 框架(Framework):
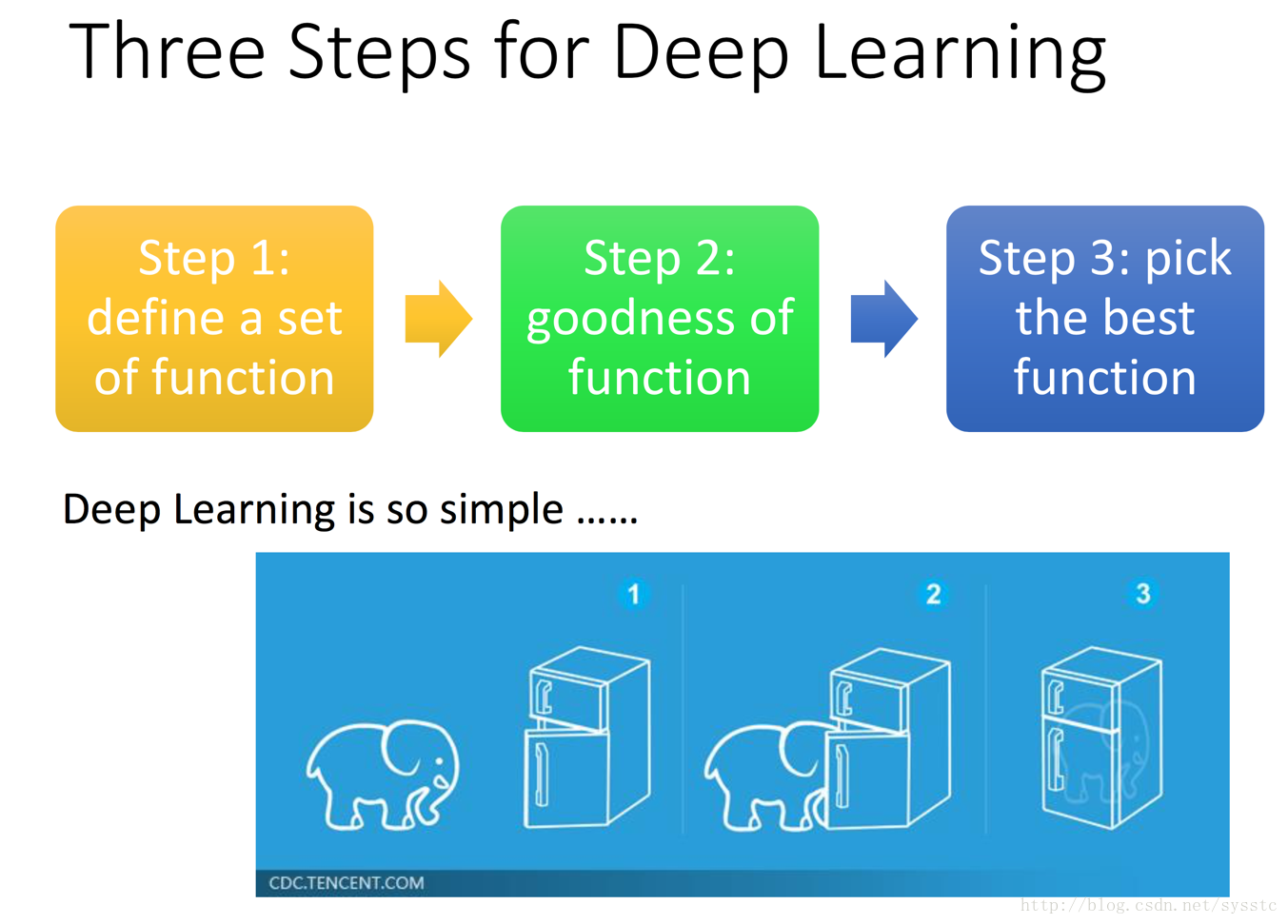
- What is Deep Learning?
深度学习其实就是一个定义方法、判断方法优劣、挑选最佳的方法的过程:
我们可以将nn定义成一个生产线(production line)
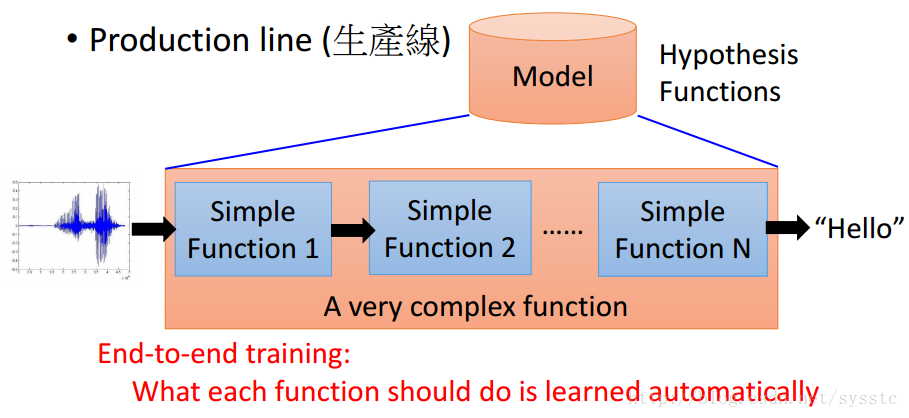
- 比起过去的语音识别技术,DeepLearning的所有function都是从数据中进行学习的。
- 深度学习通常指基于神经网络的方法。
###二、神经网络的简单理解:###
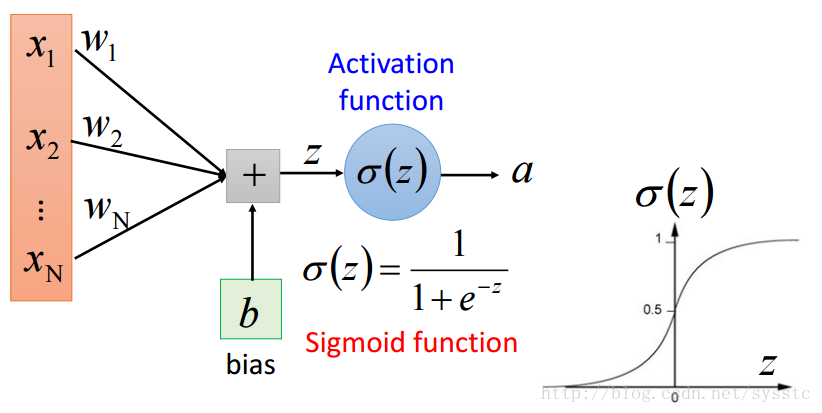
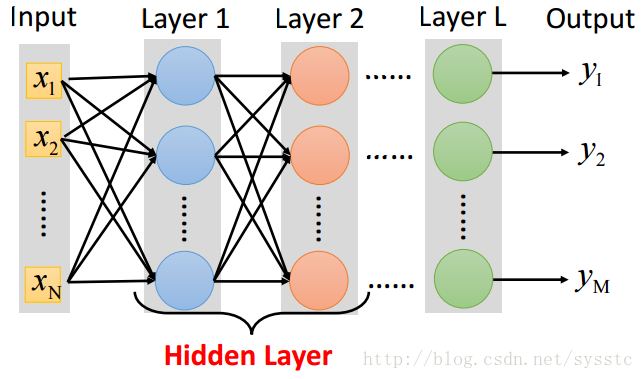
- 每一个神经元都可以看成一个简单的函数:
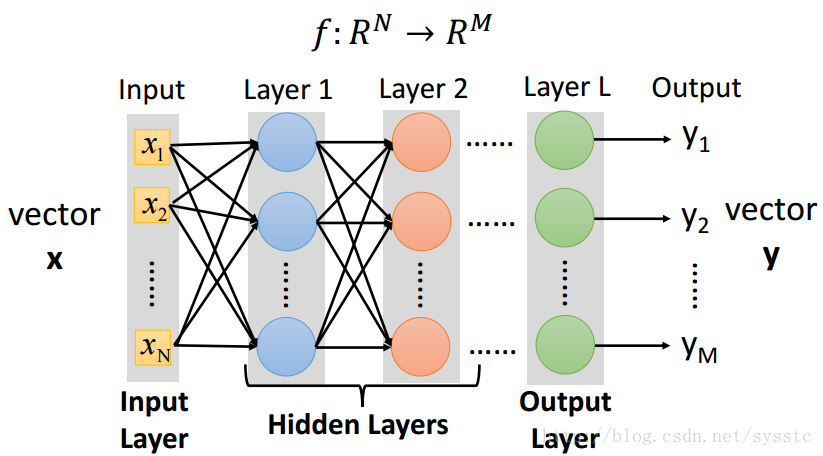
- 一个神经网络都是一个复杂的函数(从一个N维到M维的函数):
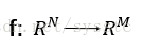
- 将神经元级联起来就可以组成一个神经网络,每一层都是production line上的一个简单函数。
- 为什么要深度神经网络:
- Universality Theorem:如果给定足够的neurons,任何一个RN指向RM的问题都能被解决。
- 多层神经网络的效果,比一层多个的神经元的神经网络的效果要好的多。
- Deeper:使用更少的参数就能达到与一层多个神经元的神经网络相同的效果。而更多参数也就意味着需要更多的training data。
- 有一些function用deep structure会更好
##Neural Network的基础概念##
目录
- 如何定义方法集
- 判断方法优劣
- 挑选最佳的方法

考虑的问题:
- 分类问题:
- Binary Classification(二分类问题):target只有两个,例如:yes/no等
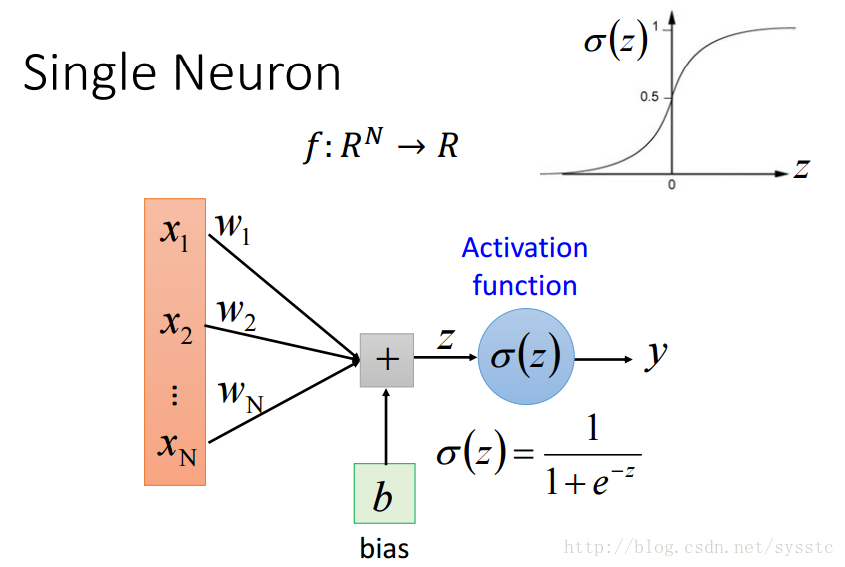
- Multi-class Classification(多分类问题):target有多个但是可以枚举,例如:手写数字识别等,注意:真的语言识别问题不是一个多分类问题,因为target是不可以枚举的
###如何定义方法集?###
- 我们想要的是什么函数:
- 对于一个分类问题:
- 我们想要的函数y = f(x),是可以将问题中的N维转化成target的M维。
- 输入x和输出y可以被表达成一个固定长度的向量,其中x是一个N维向量,y是一个M维向量。
- 对于一个分类问题:
- 单一神经元:
单一神经元只能用来判断二分类问题,并不能来判断多分类问题。 - 一层神经网络(一个hidden layer):
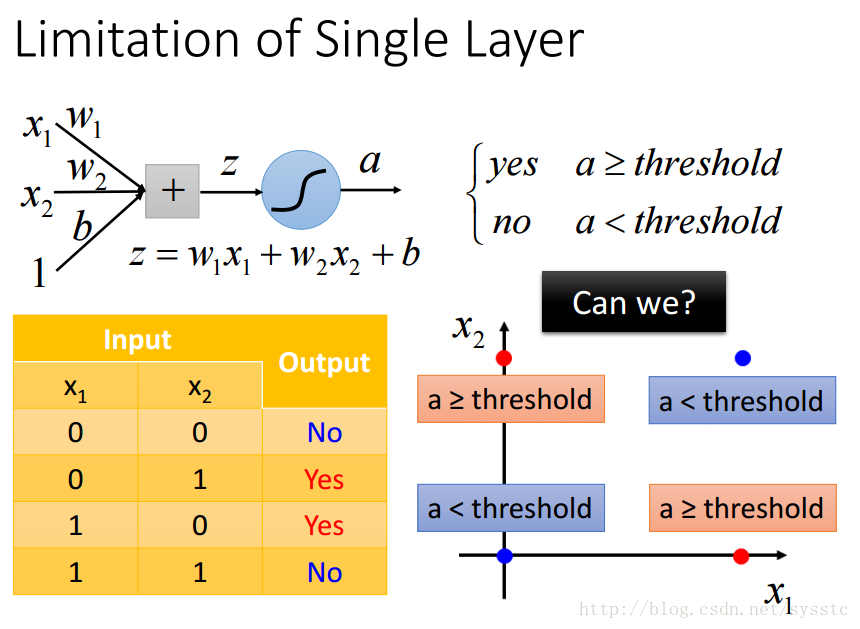
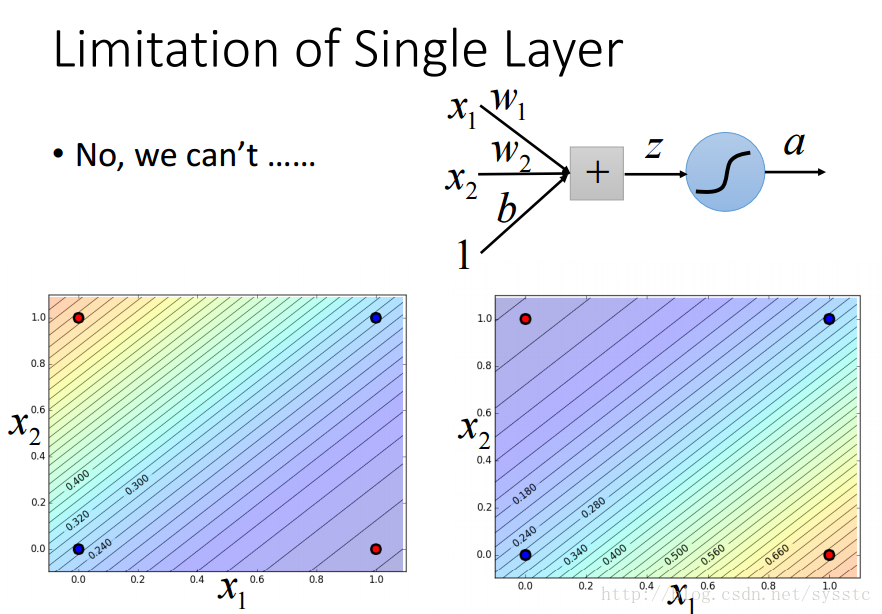
- 单一神经元的限制:
- 单一神经元不能解决以下问题:
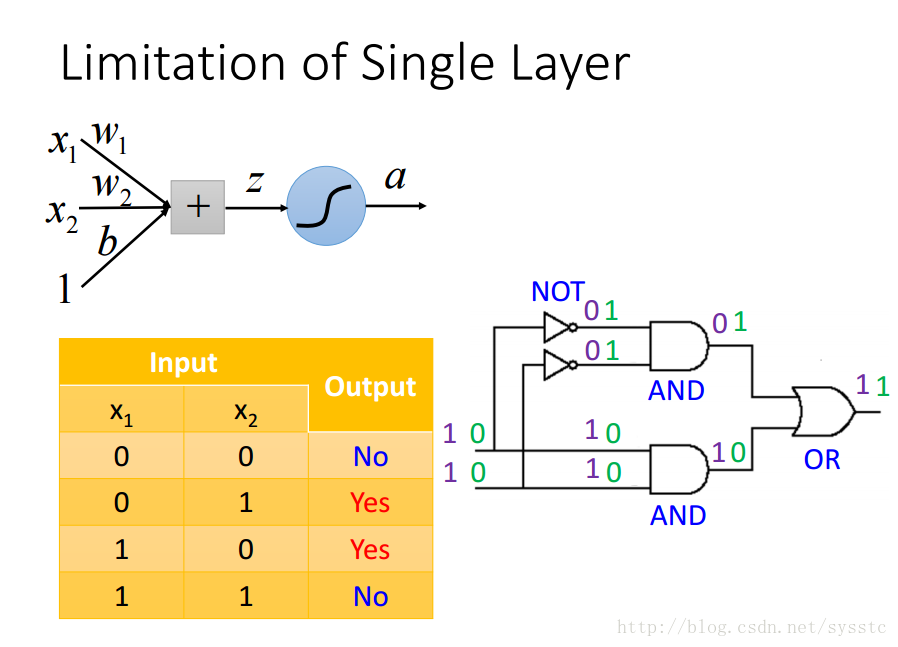
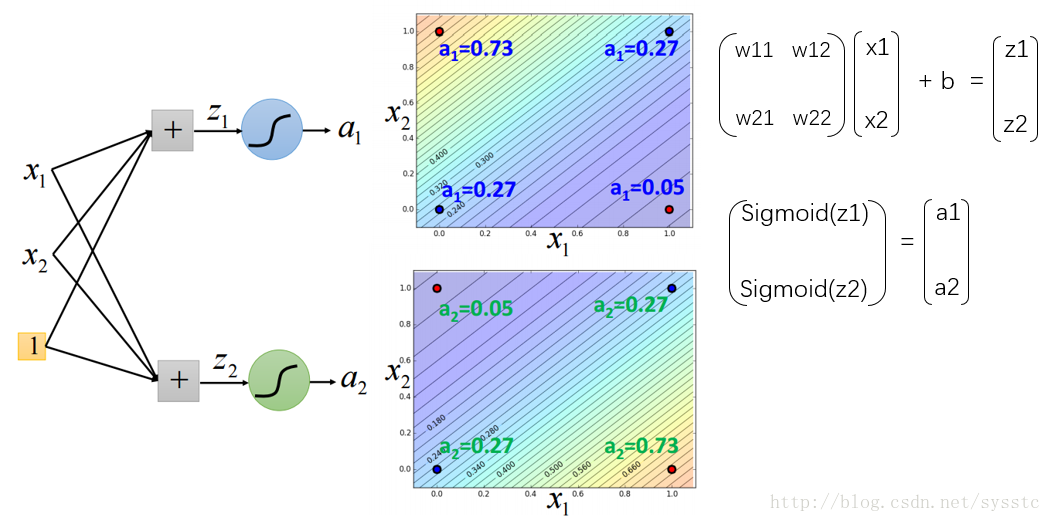
- 参照logic circuit解决这个问题:
在Hidden layer中加入两个hidden neurons:
这样我们可以通过以下计算方法得到第一层的输出,a1,a2:
输出层:
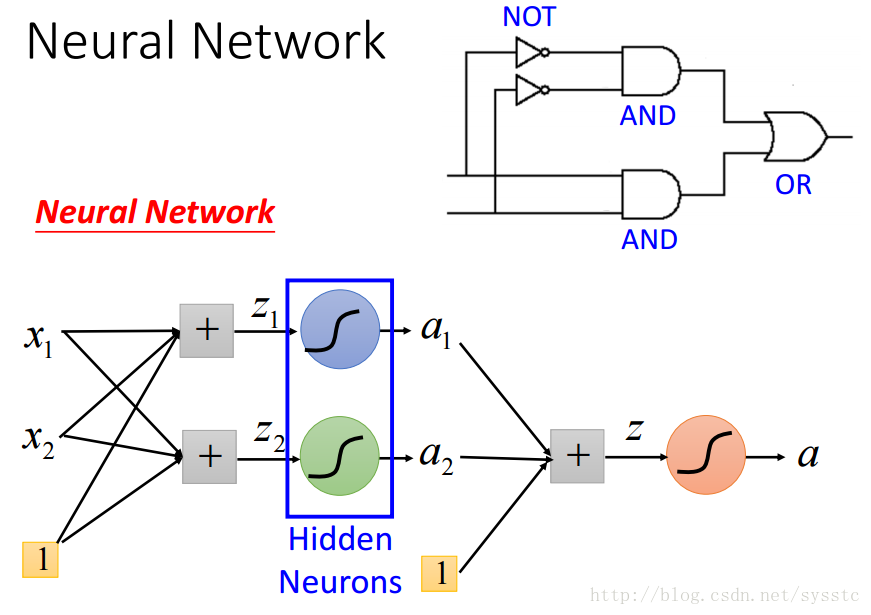
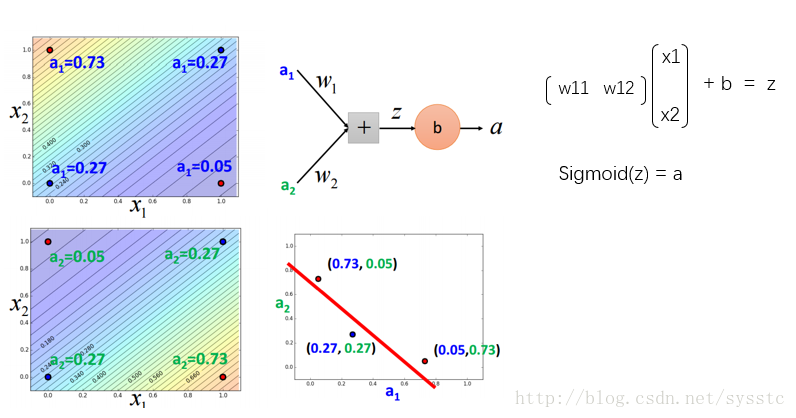
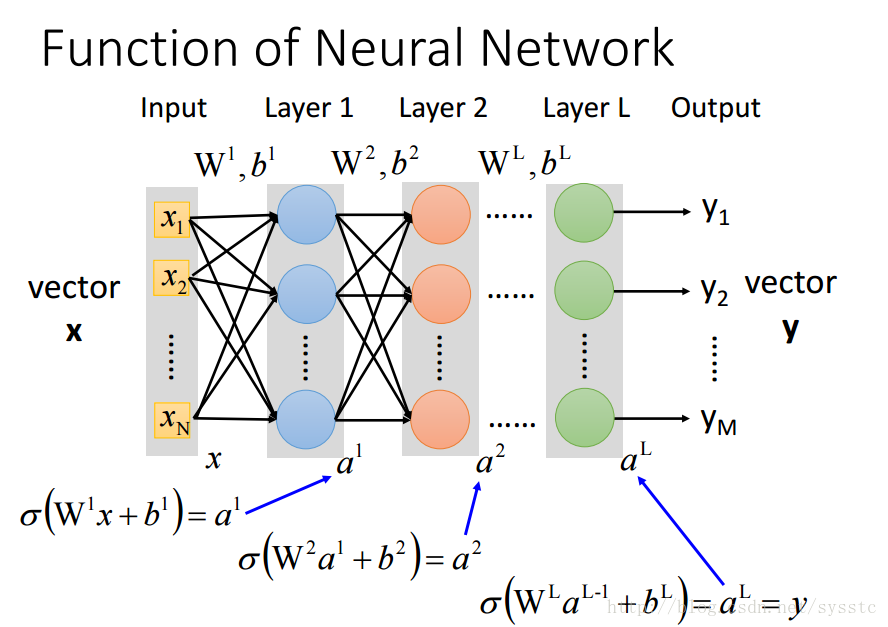
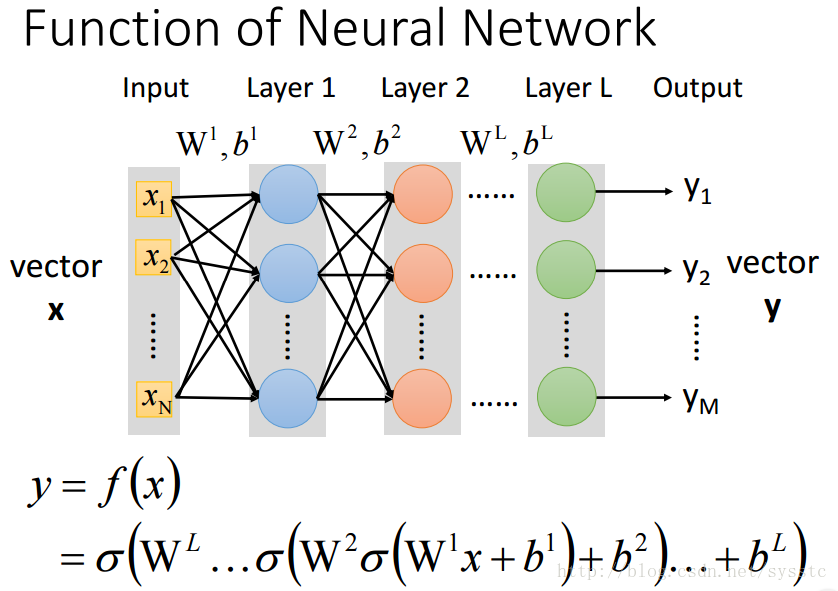
- Neural Network
- Neural Network就像是一个模型,如下图所示,是一个全连接前向传播网络,深度神经网络就是有好多隐藏层。
- 概念:
- 激活函数的输出a:
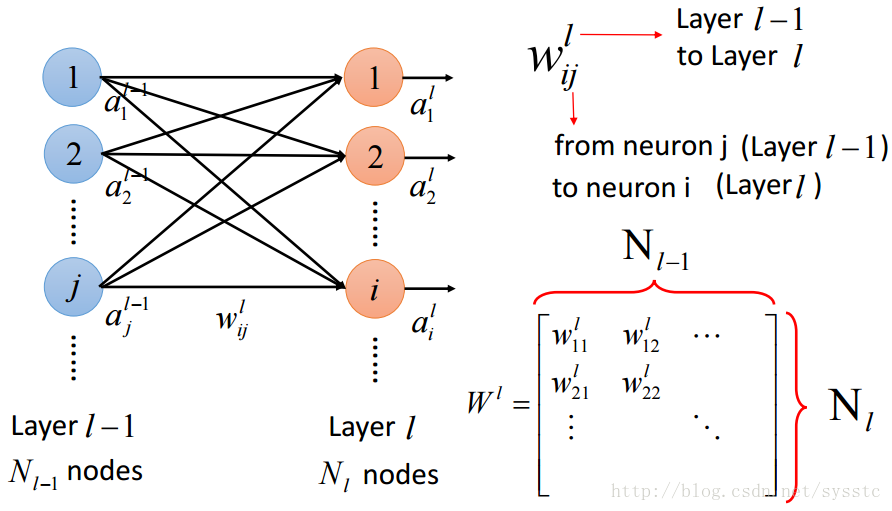
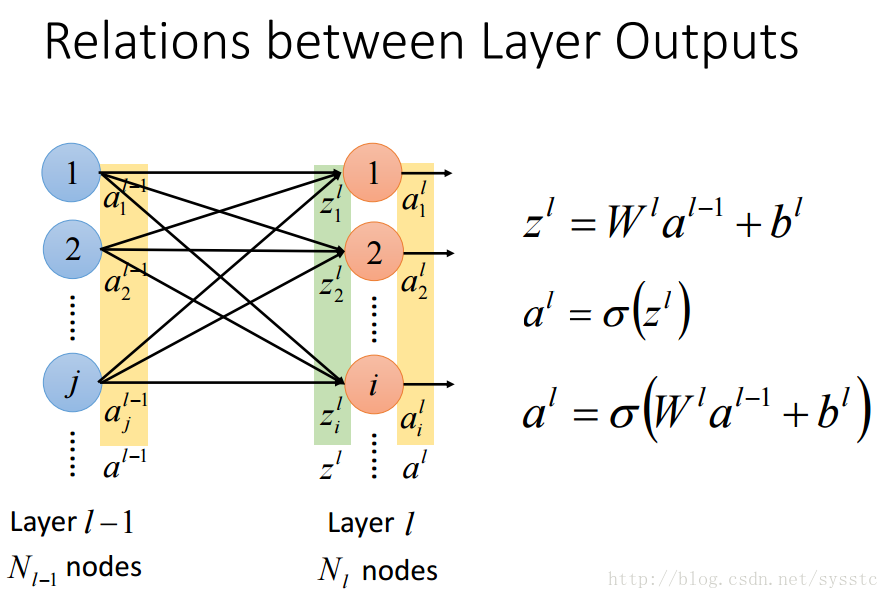
- 权重w:
这里要注意的是w的下标i,j与上标l,表示的是从第l-1层的神经元j指向第l层的神经元i
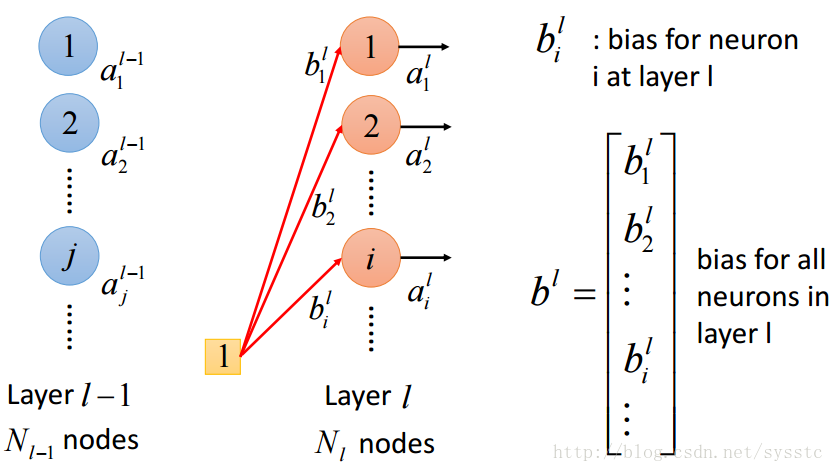
- 偏差:
不同神经元可能会有不同偏差:
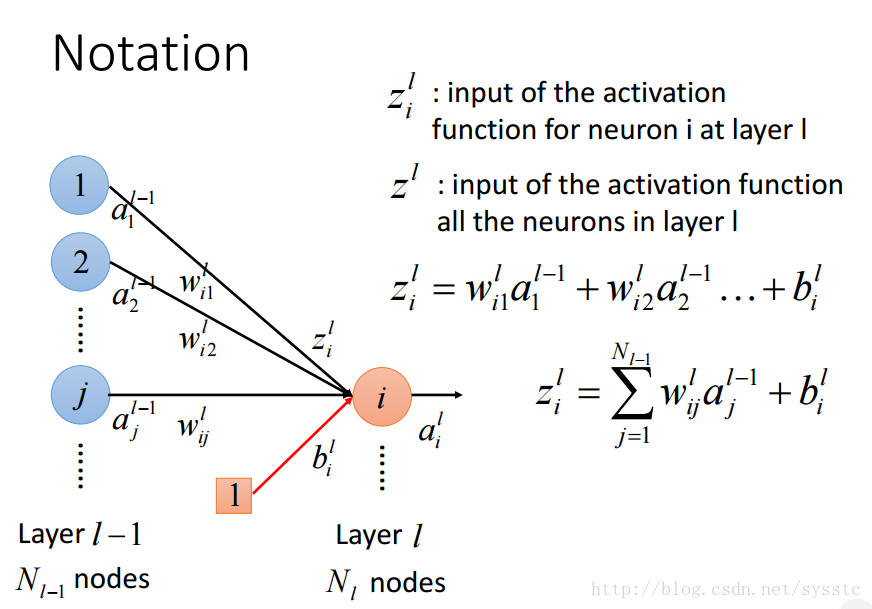
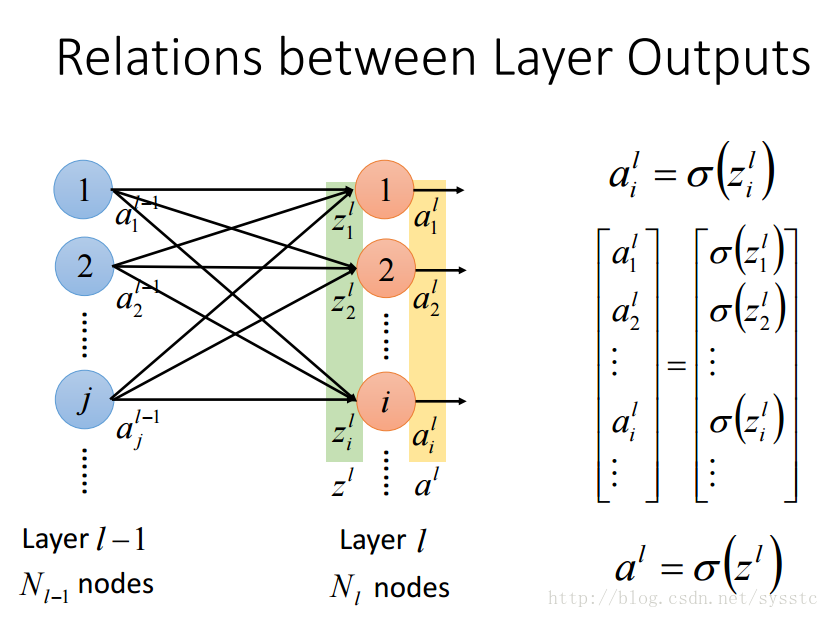
- 激活函数的输入z:
- 概念总结:
- 激活函数的输出a:
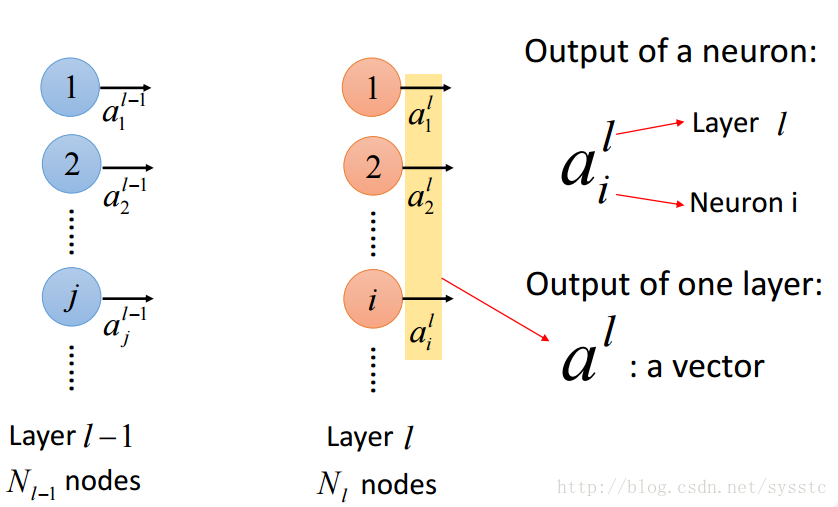

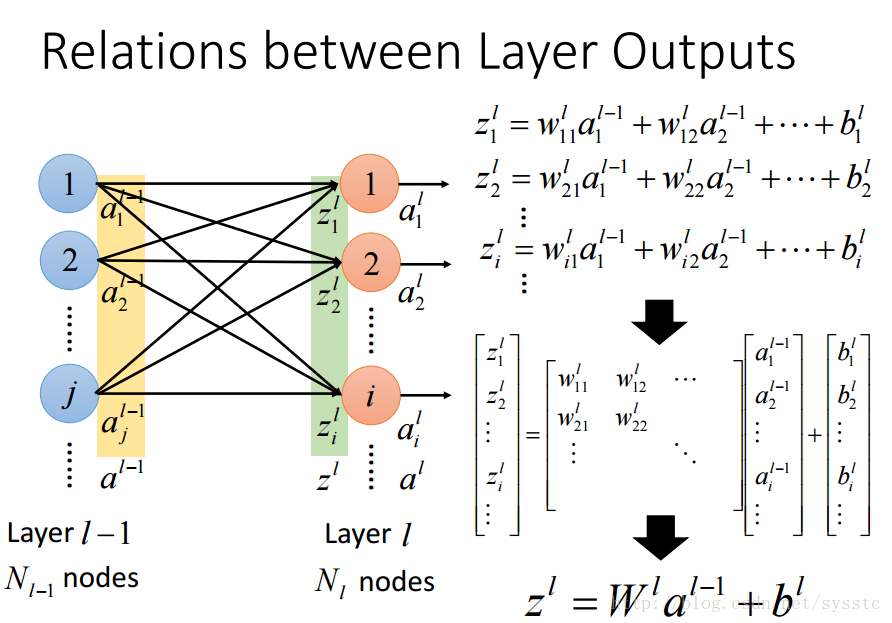
- 层输出之间的关系:
###判断方法优劣(Cost Function)### - Best Function = Best Parameters
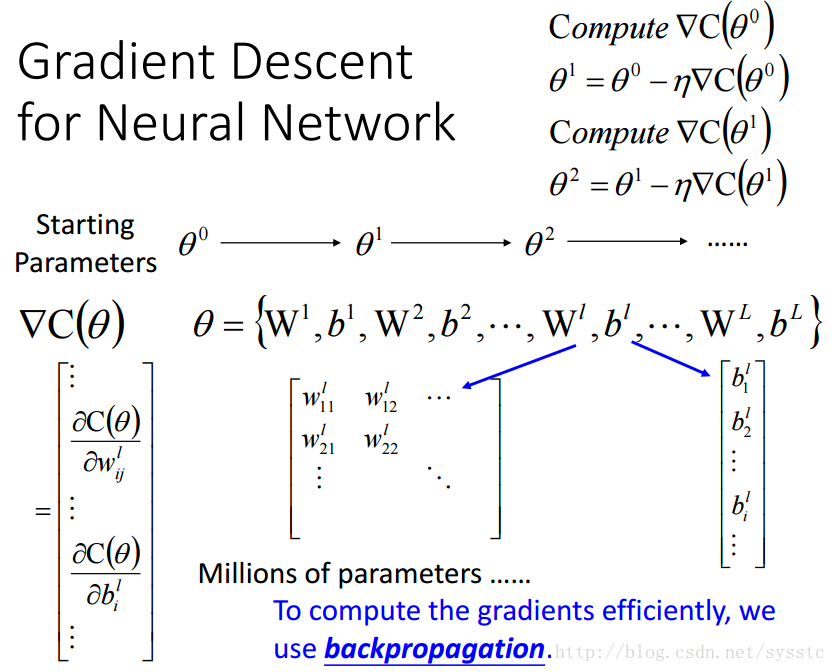
- Parameter指的就是权重W和偏差b,不同的偏差和权重会得到不同的function。我们用θ表示参数集:
- 我们通过Cost Function来判断方法优劣,C(θ)也叫成本函数/损失函数/误差函数。
###挑选最佳的方法(Gradient Descent)### - 问题描述:
- 函数C(θ):
- θ={θ1,θ2,…},不同的θ表示不同的参数集
- 我们令θ*为最好的参数集。
- 求解方法:让C(θ)对θ求偏导,并使其等于0。
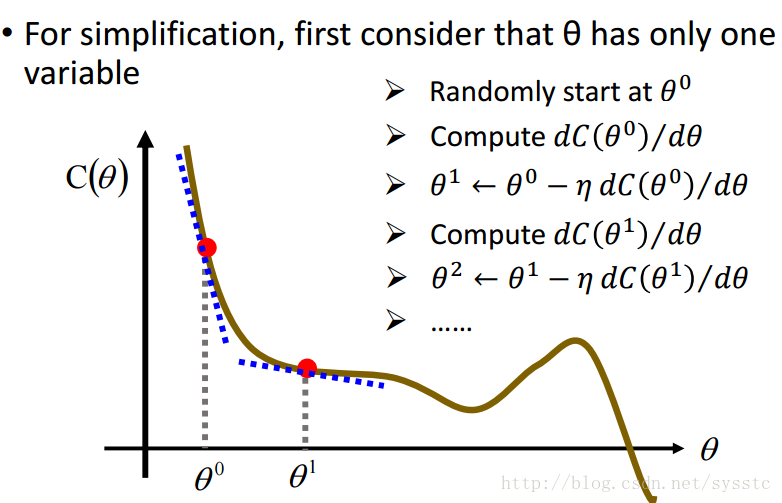
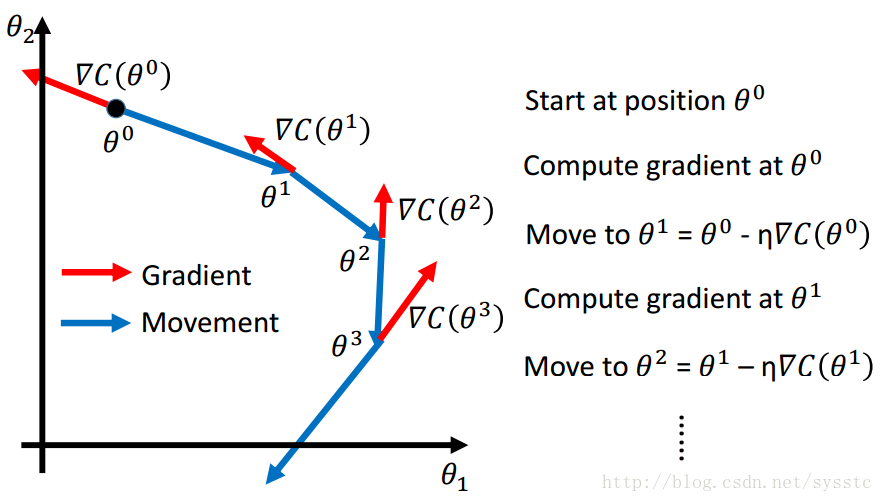
- Gradient Descent:
- 做法:
- 起始点为θ0,计算C(θ)在θ0这一点的偏导
- 求出θ1,θ1 = θ0 - learning_rate * [C(θ)在θ0处的偏导]
- 以此类推
- 举例:
小球滑下的方向就是梯度的反方向,而梯度的反方向就是我们要移动的方向:
- 做法:


- 梯度下降的推导过程:
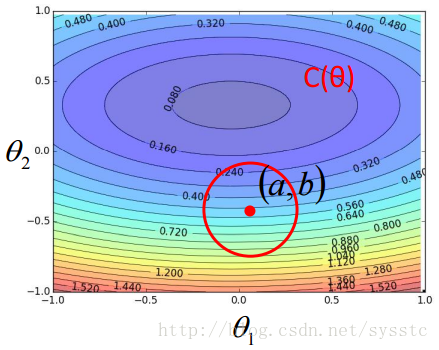
- 泰勒公式(Taylor Series):
因此只要下图上的红圈圈足够小,就能满足下面式子:
用s代替C(a,b),u 代替C(a,b)对θ1求偏导,v代替C(a,b)对θ2求偏导,因此:
C(θ) = s + u(θ1 - a) + v(θ2 - b) - **梯度下降的更新过程:**θ1和θ2是C(θ)在红圈圈里的最小值,根据上面推导出来的公式,我们就可以求出θ1和θ2的值如下:
对于神经网络的梯度下降算法,我们可以看到C(θ)对θ求偏导就是对权重和偏差求偏导,由于参数很多,因此我们可以使用backpropagation(反向传播算法)
- 泰勒公式(Taylor Series):

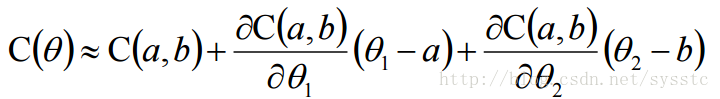

- 可能遇到的问题:local minima(局部最优)与saddle point(鞍点)
- 实例:
- 步骤:
- 参数初始化
- Learning Rate
- 随机梯度下降(SGD)与Mini-batch
- Recipe for Learning
-
参数初始化θ0:
- 建议:
1. 不要将所有参数的值都设成一样的
2. 随机设置θ0。 -
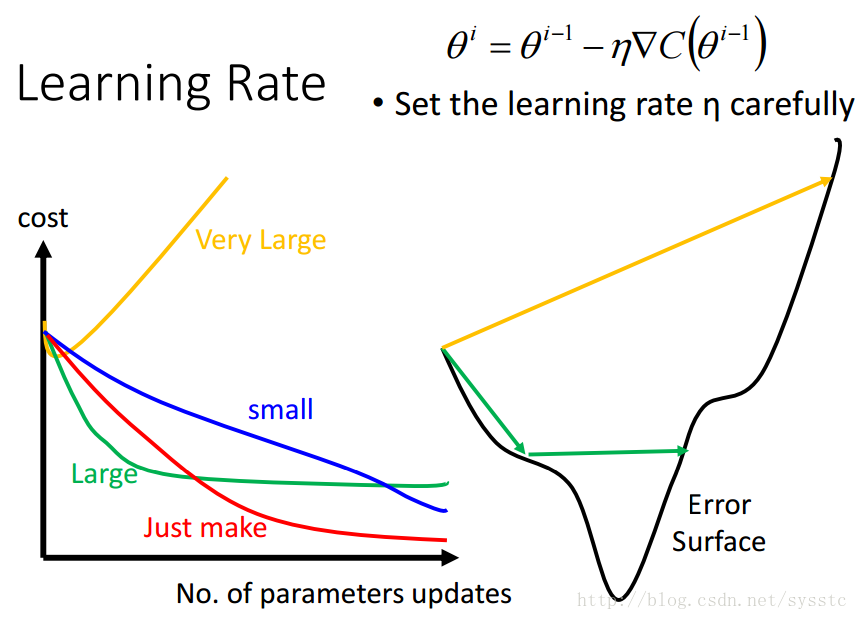
学习率:
- 学习率不能设置的太大,也不能设置的太小:
太小可能会导致效率过慢,要更新很多次才能找到minima;太大可能会导致震荡,也就是形成锯齿状。
- 学习率不能设置的太大,也不能设置的太小:
-
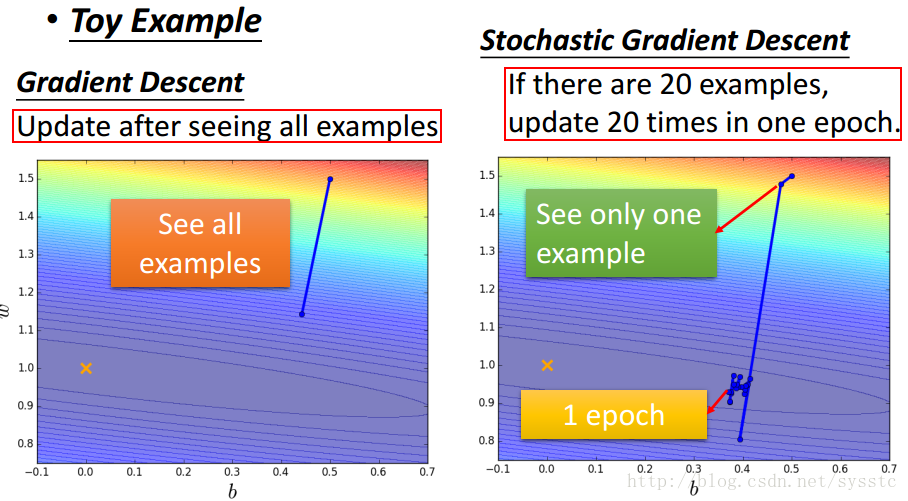
SGD与Mini-batch GD:
- SGD:训练过程如下:
- GD和SGD的区别:GD每次迭代都要用到全部的训练数据。SGD每次迭代只用到一个训练数据来更新参数。
当训练数据过大时,用GD可能造成内存不够用,那么就可以用SGD了,SGD其实可以算作是一种online-learning。另外SGD收敛会比GD快,但是对于代价函数求最小值还是GD做的比较好,不过SGD也够用了。 - Mini-batch Gradient Descent:Mini-batch Gradient Descent就是将training data中batch-size条数据做为一个batch B(记得要乱序shuffle your data),训练完这个batch B后取batch B中梯度的平均值作为更新梯度的值。
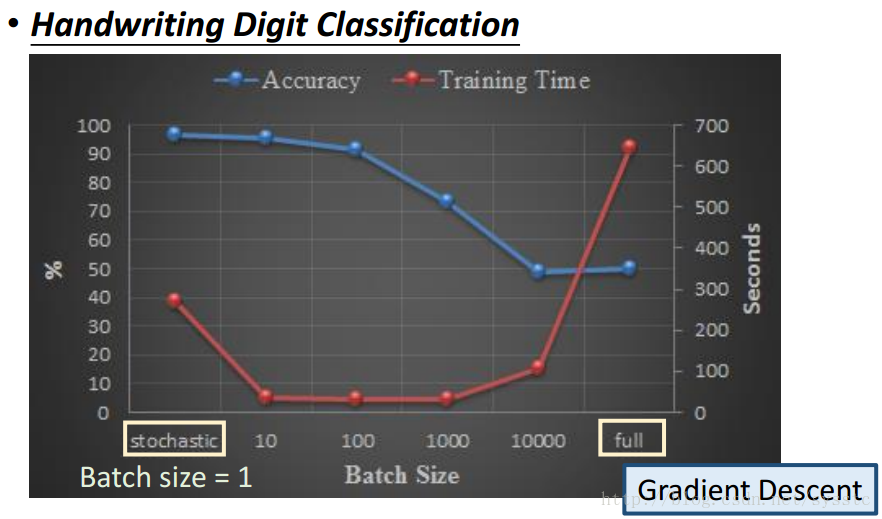
- Mini-batch GD、GD和SGD的区别如下:
下图是一个手写数字识别的例子,在这例子中,横坐标代表的是BatchSize(也就是更新一次用的training data的数量,当batch size = 1时表示的就是SGD,batch size=full时表示的就是GD)
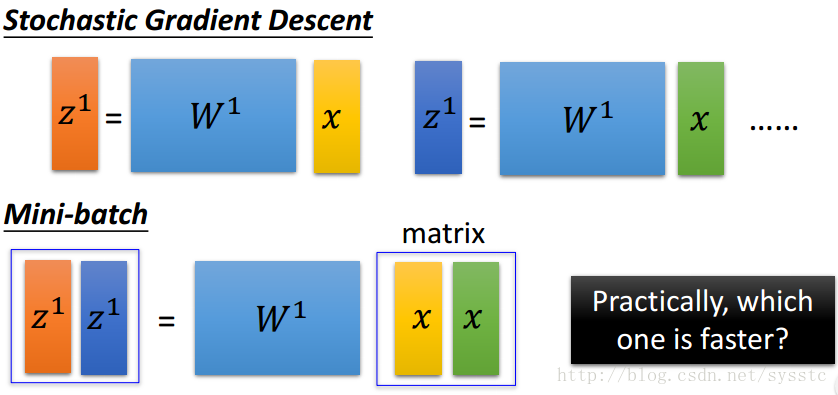
可以看到收敛速度上:Mini-batch>SGD>GD,原因如下:sgd是一个vector x乘以一个权重矩阵W得到vector z;而Mini-batch是一个matrix x(也就是batch-size的x vector的总和)乘以一个权重W,得到一个matrix z。从速度上来说sgd是要快于Mini-batch的。
- SGD:训练过程如下:
-
学习技巧:
- 如果没有在训练数据中得到好的结果:
- 程序有bug
- 没有找到good function(没有找到合适的参数,使得损失函数达到最小值)
- 比如遇到了local minima或saddle point
- 这时候就需要修改训练策略,比如修改学习率、batch-size、梯度下降函数
- Bad model:如:没有hidden layer或者是neural不够多。
- 如果在training data中表现很好,testing data上表现不好,那你可能是overfitting(过拟合)。
- overfitting的来源:
- 因为我们是在training data中找最好的参数,所以testing data中不一定能找到一个好的function。
- 解决overfitting,万灵丹就是增加training data。
- overfitting的来源:
- 如果没有在训练数据中得到好的结果: