摘 要:为了通过影评数据反应电影《流浪地球》的口碑以及其造成热度,并核实网络水军恶意对其刷差评现象是否存在,本文利用猫眼PC端接口,通过控制时间参数,动态爬取了,《流浪地球》在2019年3月5日之前的52万余条影评数据。对这些数据进行预处理操作,特征处理,可视化分析后,引入了卷积神经网络与循环神经网络对影评内容进行了更深一步的情感分析,对今后的的数据分析预测学习有一定的指导意义。
Abstract: In this paper, in order to reflect the popularity of the movie "Wandering Earth" and its heat, and to verify whether the phenomenon of malicious brushing of the film by the network Navy exists, this paper uses the cat's eye PC interface to dynamically crawl over 520,000 reviews of "Wandering Earth" before March 5, 2019 by controlling the time parameters. After pretreatment, feature processing and visual analysis of these data, convolution neural network and cyclic neural network are introduced to conduct a deeper emotional analysis of the content of film review, which has certain guiding significance for future data analysis and prediction learning.
https://github.com/MirstT/Emotional-Analysis-of-The-Wandering-Earth.git
0 引 言
《流浪地球》作为今年春节档期的唯一一部的投入了巨大资金的科幻题材电影,在一众贺岁电影中脱颖出,凭借其充满诚意的内容打动了观众,在影评口碑发酵后,流浪地球的排片率稳步上升,票房也屡创新高,根据猫眼实时电影票房数据显示,截至2019年3月5日,其票房成绩已达45.57亿,暂列中国电影票房总榜第二名,成为今年春节档电影的最大赢家,而在其荣耀的背后却是电影市场的暗流涌动。

1□研究问题
《流浪地球》影评数据分析的获取与分析
1.1 问题背景
流浪地球首日排片率低,票房成绩不佳。随着上映后第一批观众的良好口碑发酵,几大电影售票平台与评分平台纷纷对该电影给予巨大的好评,对其后续票房走势的爆炸产生了重要的推动影响。

其结果就是,随着排片率上升,观影人数增加,票房激增,在电影获得巨大成功的同时,网传出现水军恶意刷流浪地球差评,豆瓣电影评分一降再降,网友群起而攻之,集中对豆瓣电影不公平的网络评论及评分回应“网络暴力”,豆瓣app评分大量差评,一度降至最低分。
1.2 问题描述
为了动态了解流浪地球影评数据对其票房影响,以及后续差评水军的检测,需要收集不同时间段的大量影评数据作为数据支持并动态追踪,通过影评数据反映出上述事件的爆发点,而另一方面由于许多影评网站已经做了大量的反爬虫机制。豆瓣网从2017年10月开始全面禁止爬取数据。在非登录状态下仅仅可以爬取200条短评,登录状态下仅可以爬取500条数据。白天一分钟最多可爬40次,晚上60次,超过次数就会封IP地址不利于大量数据的获取。
同时可利用影评网站自带的打分系统,形成带感情色彩的影评数据,结合相关算法训练出能够识别出影评情感的模型,可用于推测没有评分数据的影评的情感倾向。
2 解决方法
2.1问题分析
为了大量稳定的获取影评数据,放弃豆瓣影评数据,改用更易爬取且数据量更大的猫眼影评接口,爬取包含:网名,所在城市,评分,评论内容,已经评分时间的评论人信息。
对数据预处理后,通过可视化图标观察影评数据与城市的关系,观众对应电影的情感以及情感走势与时间的关系,日投票量中的投票占比,同时对影评关键词进行监控,以发现数据和上述事件之间的关系。
利用Pyecharts 并结合Echarts 对影评数据进行可视化分析,利用Wordcloud 提取影评中的关键词,同时利用Tensorflow中的Tensorboard对模型构建过程进行可视化。
同时,对抽取的影评数据进行进一步处理后,影评内容对应的评分(0.5-5.0十个档位的评分可作为情感分析的重要参考),结合卷积神经网络和递归神经网络对影评数据进行进一步的情感分析并建立模型。
2.2算法分析
鉴于神经网络模型通过学习和训练后,能有效地模拟人脑的学习方式,对大量的输入文本信息进行高效的分析,并对文本中的情感进行判断,非常适合用于文本情感分析的研究中,可将爬取得到的影评数据进一步拆分为 训练集,测试集,验证集,并规范格式后分别利用CNN与LSTM或GRU对影评内容进行情感分析,并建立预测模型。
CNN 处理文本的时候,输入就是一个为矩阵的句子,就像原先图像像素的输入一样,不过是单通道的。矩阵的每一行对应一个单词的 Token,通常是一个单词,但它可以是一个字符。也就是说,每行是表示单词的向量表示。通常,这些向量是词嵌入向量(低维表示),如 word2vec 或 GloVe,但它们也可以是将单词索引为词汇表的 one-hot 向量。
下面就是使用CNN抽取文本信息的原理,“wait for the video and do not rent it” 是我们需要处理的数据。我们将其处理为图像格式的数据,如图中所示,每一行就表示一个词的词向量,完成“图像”的构造后,就需要对其进行卷积。这里使用的卷积核比较特别,其大小是(step,Embedding_Size)在完成卷积后可得到对应的特征图,这里需要注意的是,并不是一次卷积,比如对这个“图像”进行卷积的时候(假设文本长度都为50),我们采用(2,100),(3, 100), (4,100)的卷积和进行卷积后分别得到(49, 1, 126), (48, 1, 126), (47, 1, 126)的特征图。然后采用max_pool采样,依次采样为(1,1,126), (1, 1, 126), (1, 1, 126),然后进行拼接最后添加分类层。

而RNN 会受到短时记忆的影响。如果一条序列足够长,那它们将很难将信息从较早的时间步传送到后面的时间步。 因此,如果你正在尝试处理一段文本进行预测,RNN 可能从一开始就会遗漏重要信息。
在反向传播期间,RNN 会面临梯度消失的问题。 梯度是用于更新神经网络的权重值,消失的梯度问题是当梯度随着时间的推移传播时梯度下降,如果梯度值变得非常小,就不会继续学习。

LSTM是一种特殊的RNN类型,一般的RNN结构如下图所示,是一种将以往学习的结果应用到当前学习的模型,但是这种一般的RNN存在着许多的弊端。举个例子,如果我们要预测“the clouds are in the sky”的最后一个单词,因为只在这一个句子的语境中进行预测,那么将很容易地预测出是这个单词是sky。在这样的场景中,相关的信息和预测的词位置之间的间隔是非常小的,RNN 可以学会使用先前的信息,这相对于CNN无疑更利于文本分析。

GRU作为LSTM的一种变体,将忘记门和输入门合成了一个单一的更新门。同样还混合了细胞状态和隐藏状态,加诸其他一些改动。最终的模型比标准的 LSTM 模型要简单,也是非常流行的变体。

3.实验研究
3.1 环境与数据集介绍
3.1.1 软硬件环境
操作系统:Windows 10 Insider Preview 17758.1 (rs5_release) x64 ;开发平台: PyCharm 2018.1.4 (Professional Edition);第三方库:pyecharts,jieba,wordcloud, tensorflow,json,requests;额外补充:Echarts中国地图包。
处理器: Intel( R) Core(TM) [email protected];内存:16GB。
3.1.2数据集爬取
猫眼对接口没有做反爬限制,可以通过控制该接口的start Time 的值以json数据的形式来获取不同时段的所有影评信息:
http://m.maoyan.com/mmdb/comments/movie/248906.json?_v_=yes&offset=0&startTime

即利用Get_Data.py模仿手机客户端(iPhone ios11)获取猫眼PC网站json数据,设置好statTime开始与结束时间后,然后改变 startTime 字段的值来获取更多评论信息,把 offset 置为 0,把每页评论数据中最后一次评论时间作为新的 startTime 去重新请求,即可开启爬虫获取数据,获取所有54万条数据大概用时10小时左右。
3.1.4数据集
通过爬虫程序获取的数据存入csv文件中,其中包含了评论人在内的网名,地域,评论内容,评分,及时间的 524460条影评数据。

3.2数据预处理介绍
在Get_Data.py中,通过json关键字获取内容,对文本进行初步清洗后存入csv文件,去重,排空。
紧接着,在Analyze_Data.py中,利用remove_None()函数对评论人的地域名称和 Echarts中的城市名称进行模糊匹配,一一对应,同时将评论时间的格式转换为标准日期格式,便于日期排序。
通过lambda表达式借助judgeTime()函数,将19年2月4号之前的影评数据全部汇总到19年2月4号,并删除19年3月5号之后的影评数据(最新数据是19年3月6号的数据)。
import requests # 爬虫库
import json # 评论网站(猫眼)json数据解析 http://m.maoyan.com/mmdb/comments/movie/248906.json?_v_=yes&offset=0&startTime=2019-02-05%2020:28:22
import time # 程序内部时间控制
import datetime # 获取时间
import pandas as pd
# 请求评论api接口
def requestApi(url):
headers = {
'accept': '*/*',
'user-agent': 'Mozilla/5.0 (iPhone; CPU iPhone OS 11_0 like Mac OS X) AppleWebKit/604.1.38 (KHTML, like Gecko) Version/11.0 Mobile/15A372 Safari/604.1',
} # 模仿手机客户端(iPhone ios11 Safari)获取网站json数据
try:
r = requests.get(url, headers=headers)
r.raise_for_status()
return r.text
except requests.HTTPError as e: # 异常抛出
print(e)
except requests.RequestException as e:
print(e)
except:
print("获取数据出错")
# 解析接口返回数据
def getData(html):
json_data = json.loads(html)['cmts']
comments = []
# 解析数据并存入数组
try:
for item in json_data:
comment = []
comment.append(item['nickName']) # 用户名
comment.append(item['cityName'] if 'cityName' in item else '') # 所在城市(如果有则记录该数据,否则不记录)
comment.append(item['content'].strip().replace('\n', '')) # 删除评论中的换行
comment.append(item['score']) # 评分星级
comment.append(item['startTime']) # 评论上交时间
comments.append(comment)
return comments
except Exception as e:
print(comment)
print(e)
# 保存数据,写入excel
def saveData(comments):
filename = './input/Comments_new.csv'
# 将评论数据以csv文件格式保存在当前文件夹下
dataObject = pd.DataFrame(comments)
dataObject.to_csv(filename, mode='a', encoding="utf_8_sig", index=False, sep=',', header=False)
# 使用utf_8_sig对字节进行有序编码,防止在系统中用某些软件直接浏览浏览时出现乱码问题,影响阅读;
# 爬虫主函数
def main():
start = datetime.datetime.now()
# 当前时间
# start_time = datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S')
# 开始抓取时间
start_time = '2019-03-06 00:00:00'
# 流浪地球电影上映前的所有评论
end_time = '2018-01-01 00:00:00'
init_time = start_time # 记录程序开始运行的时间
print('开始获取数据!', init_time)
while start_time > end_time:
url = 'http://m.maoyan.com/mmdb/comments/movie/248906.json?_v_=yes&offset=0&startTime=' + start_time.replace(
' ', '%20') # 改变 startTime 字段的值来获取更多评论信息,把 offset 置为 0,把每页评论数据中最后一次评论时间作为新的 startTime 去重新请求
html = None
print(url)
try:
html = requestApi(url)
except Exception as e: # 如果有异常,暂停一会再爬
time.sleep(1) # 暂停一秒
html = requestApi(url)
# else: #开启慢速爬虫,防止封禁ip地址
# time.sleep(0.5)
comments = getData(html)
# print(url)
start_time = comments[14][4] # 获取每页中最后一条评论时间,每页有15条评论
# print(start_time)
# 最后一条评论时间减一秒,避免爬取重复数据
start_time = datetime.datetime.strptime(start_time, '%Y-%m-%d %H:%M:%S') + datetime.timedelta(seconds=-1)
end = datetime.datetime.now()
print(start_time)
saveData(comments)
print('获取数据完成!')
print('程序运行用时:', start - end)
if __name__ == '__main__':
main()3.3特征处理介绍
在Analyze_Data.py文件中对预处理的文件进行可视化分析,利用Pyecharts 并结合Echarts 对影评数据进行可视化分析,绘制观众地域图,观众地域排行榜单(前20),观众评论数量与日期的关系,观众情感曲线,观众评论数量与时间的关系图,观众评论走势与时间的关系:



根据全国观众地域分布图以及观众地域排行榜单(图9,10,11)发现提交影评的观众地域分布正常,没有异常情况,地域影评数据符合正常情况下的人口密度分布(春节期间,上海市人口流失严重,,,,,)。


根据《流浪地球》观众评论数量与日期和时间的关系图(图12,13)观众评论时间正常分布,大部分影评都是在深夜发布,同时观众评论爆发的7,8,9,10号也是流浪地球最为火爆的日期,同时观众评论数量会随着周末有一定的波动性,这也与电影票房曲线吻合。



根据三幅观众评论走势与时间的关系图,折线图,河流图,横向柱状图(图14,15,16)发现,观众的主要评论都是4.5星与5星,绝大多数观众都对这部电影给予了满分或者接近满分的好评,各种影评比例占比基本没有变化,网传的水军恶意刷差评影响获取并不是特别大,同时影评数量的波动也体现了春节档电影票房的走势。

但是,结合观众差评评论走势与时间的关系(图17)在差评评论中,最低分0.5分(红色)的占比却明显的高于2,1.5,1分的占比,甚至高于这些分数的总和,由此可以说明,对于这部电影,还是有许多网友在评论的时候是抱有偏见的,想打差评的人在恶意差评拉低电影评分,由于数据量在整体比例中所占比例不高,对整体评分的也没有造成影响。

最后的结合观众打分画出的观众情感曲线图(图18)也充分印证了上述的说明,大部分人对于这部电影都是给与满分肯定的,想打差评的人也都是是一边倒的给与了最低分0.5分。

最后,利用Wordcloud 绘制词云以提取影评中的关键词(停用词存了在了./input/stopwords.txt中,排除了部分无用词汇的干扰),根据图片显示,观众认为这是“一部里程碑式的优秀国产科幻片”“特效十足”“非常好看”,大大的“好看”也充分为其票房爆炸提供了有力的保证。
# 16124278 王浩 流浪地球 Analyze_Data
# -*- coding: UTF-8 -*-
import pandas as pd
from collections import Counter # 计数器
from pyecharts import Geo, Bar, Page, Style, ThemeRiver, Line # 数据可视化图表
from pyecharts.datasets.coordinates import search_coordinates_by_keyword # 关键字匹配(地名)
import jieba # 结巴分词
import jieba.analyse
import matplotlib.pyplot as plt # 绘图
from wordcloud import WordCloud, STOPWORDS, ImageColorGenerator # 词云
import datetime # 日期
startTime_tag = datetime.datetime.strptime('2019-02-04', '%Y-%m-%d') # 将2019.2.4号之前的数据汇总到2.4 统一标识为电影上映前影评数据
# 提前自定义pyecharts渲染图格式
style_map = Style(
title_color="#fff",
title_pos="center",
width=1900,
height=950,
background_color='#404a59'
)
style_others = Style(
title_pos='center',
width=1900,
height=950
)
style_size = Style(
width=1900,
height=950
)
# 读取csv文件数据
def read_csv(filename, titles):
print("正在读取csv文件数据......")
comments = pd.read_csv(filename, names=titles, encoding='utf_8_sig') # 指定读取格式utf_8_sig
return comments
# 数据城市名称与热力地图名称匹配(模糊匹配到热力图中的地址名称:例如 上海 = 上海市 舟山 = 舟山市)
def remove_None(areas, values):
None_areas = [] # 储存无效区域
i = 0 # 计数器
while (i != len(areas)):
# 取前两个字符作模糊查询
if search_coordinates_by_keyword(areas[i][:2]) == {}: # 匹配失败,删除这条数据
None_areas.append(areas[i])
areas.remove(areas[i])
values.remove(values[i])
else:
# 将模糊查询结果替代原地名
areas[i] = search_coordinates_by_keyword(areas[i][:2]).popitem()[0]
i = i + 1 # 计数器加一
if len(None_areas) == 0:
print('区域名称已全部匹配完成!')
else:
print('无效区域:', None_areas)
return areas, values
# 观众地域图
def draw_map(comments):
print("正在处理观众地域图......")
try:
page = Page() # 页面储存器
attr = comments['cityName'].fillna("zero_token") # 将不包含城市数据的数据置为空标志
data = Counter(attr).most_common(300) # 计数并选取数据最多的300个城市
data.reverse() # 反转数据,为了热力图有更好的显示效果(数据量大的城市在最上方)
data.remove(data[data.index([(i, x) for i, x in (data) if i == 'zero_token'][0])]) # 删除没有城市名称的空标志数据
geo = Geo("《流浪地球》全国观众地域分布点", "数据来源:猫眼电影 数据分析:16124278-王浩", **style_map.init_style) # 初始一张热力图并设置外观
# attr, value = geo.cast(data)
attr, value = remove_None(geo.cast(data)[0], geo.cast(data)[1]) # 地图名称模糊匹配
geo.add("", attr, value, visual_range=[0, 4000], maptype='china', visual_text_color="#fff", symbol_size=10,
is_visualmap=True, is_legend_show=False,
tooltip_formatter='{b}',
label_emphasis_textsize=15,
label_emphasis_pos='right') # 加入数据并设置热力图风格参数-点图
page.add(geo) # 添加到渲染队列
geo = Geo("《流浪地球》全国观众地域分布域", "数据来源:猫眼电影 数据分析:16124278-王浩", **style_map.init_style) # 初始一张热力图并设置外观
geo.add("", attr, value, type="heatmap", is_visualmap=True,
visual_range=[0, 4000], visual_text_color='#fff',
is_legend_show=False) # 加入数据并设置热力图风格参数-区域图
page.add(geo) # 添加到渲染队列
geo = Geo("《流浪地球》全国观众地域分布点域", "数据来源:猫眼电影 数据分析:16124278-王浩", **style_map.init_style) # 初始一张热力图并设置外观
geo.add("", attr, value, visual_range=[0, 4000], maptype='china', visual_text_color="#fff", symbol_size=10,
is_visualmap=True, is_legend_show=False,
tooltip_formatter='{b}',
label_emphasis_textsize=15,
label_emphasis_pos='right')
geo.add("", attr, value, type="heatmap", is_visualmap=True,
visual_range=[0, 4000], visual_text_color='#fff',
is_legend_show=False) # 加入数据并设置热力图风格参数-区域图
page.add(geo) # 添加到渲染队列
page.render("./output/观众地域分布-地理坐标图.html") # 渲染热力图
print("全国观众地域分布已完成!!!")
except Exception as e: # 异常抛出
print(e)
# 观众地域排行榜单(前20)
def draw_bar(comments):
print("正在处理观众地域排行榜单......")
data_top20 = Counter(comments['cityName']).most_common(20) # 筛选出数据量前二十的城市
bar = Bar('《流浪地球》观众地域排行榜单', '数据来源:猫眼电影 数据分析:16124278-王浩', **style_others.init_style) # 初始化柱状图
attr, value = bar.cast(data_top20) # 传值
bar.add('', attr, value, is_visualmap=True, visual_range=[0, 16000], visual_text_color='black', is_more_utils=True,
is_label_show=True) # 加入数据与其它参数
bar.render('./output/观众地域排行榜单-柱状图.html') # 渲染
print("观众地域排行榜单已完成!!!")
# lambda表达式内置函数
# 将startTime_tag之前的数据汇总到startTime_tag
def judgeTime(time, startTime_tag):
if time < startTime_tag:
return startTime_tag
else:
return time
# 观众评论数量与日期的关系
def draw_DateBar(comments):
print("正在处理观众评论数量与日期的关系......")
time = pd.to_datetime(comments['startTime']) # 获取评论时间并转换为标准日期格式
time = time.apply(lambda x: judgeTime(x, startTime_tag)) # 将2019.2.4号之前的数据汇总到2.4 统一标识为电影上映前影评数据
timeData = []
for t in time:
if pd.isnull(t) == False: # 获取评论日期(删除具体时间)并记录
t = str(t) # 转换为字符串以便分割
date = t.split(' ')[0]
timeData.append(date)
data = Counter(timeData).most_common() # 记录相应日期对应的评论数
data = sorted(data, key=lambda data: data[0]) # 使用lambda表达式对数据按日期进行排序
bar = Bar('《流浪地球》观众评论数量与日期的关系', '数据来源:猫眼电影 数据分析:16124278-王浩', **style_others.init_style) # 初始化柱状图
attr, value = bar.cast(data) # 传值
bar.add('', attr, value, is_visualmap=True, visual_range=[0, 43000], visual_text_color='black', is_more_utils=True,
is_label_show=True) # 加入数据和其它参数
bar.render('./output/观众评论日期-柱状图.html') # 渲染
print("观众评论数量与日期的关系已完成!!!")
# 观众情感曲线
def draw_sentiment_pic(comments):
print("正在处理观众情感曲线......")
score = comments['score'].dropna() # 获取观众评分
data = Counter(score).most_common() # 记录相应评分对应的的评论数
data = sorted(data, key=lambda data: data[0]) # 使用lambda表达式对数据按评分进行排序
line = Line('《流浪地球》观众情感曲线', '数据来源:猫眼电影 数据分析:16124278-王浩', **style_others.init_style) # 初始化
attr, value = line.cast(data) # 传值
for i, v in enumerate(attr): # 将分数修改为整数便于渲染图上的展示
attr[i] = v * 2
line.add("", attr, value, is_smooth=True, is_more_utils=True, yaxis_max=380000, xaxis_max=10) # 加入数据和其它参数
line.render("./output/观众情感分析-曲线图.html") # 渲染
print("观众情感曲线已完成!!!")
# 观众评论数量与时间的关系图
def draw_TimeBar(comments):
print("正在处理观众评论数量与时间的关系......")
time = comments['startTime'].dropna() # 获取评论时间
timeData = []
for t in time:
if pd.isnull(t) == False: # 获取评论时间(当天小时)并记录
time = t.split(' ')[1]
hour = time.split(':')[0]
timeData.append(int(hour)) # 转化为整数便于排序
data = Counter(timeData).most_common() # 记录相应时间对应的的评论数
data = sorted(data, key=lambda data: data[0]) # 使用lambda表达式对数据按时间进行排序
bar = Bar('《流浪地球》观众评论数量与时间的关系', '数据来源:猫眼电影 数据分析:16124278-王浩', **style_others.init_style) # 初始化柱状图
attr, value = bar.cast(data) # 传值
bar.add('', attr, value, is_visualmap=True, visual_range=[0, 40000], visual_text_color='black', is_more_utils=True,
is_label_show=True) # 加入数据和其它参数
bar.render('./output/观众评论时间-柱状图.html') # 渲染
print("观众评论数量与时间的关系已完成!!!")
# 观众评论走势与时间的关系
def draw_score(comments):
print("正在处理观众评论走势与时间的关系......")
page = Page() # 页面储存器
score, date, value, score_list = [], [], [], []
result = {} # 存储评分结果
d = comments[['score', 'startTime']].dropna() # 获取评论时间
d['startTime'] = d['startTime'].apply(lambda x: pd.to_datetime(x.split(' ')[0])) # 获取评论日期(删除具体时间)并记录
d['startTime'] = d['startTime'].apply(lambda x: judgeTime(x, startTime_tag)) # 将2019.2.4号之前的数据汇总到2.4 统一标识为电影上映前影评数据
for indexs in d.index: # 一种遍历df行的方法(下面还有第二种,iterrows)
score_list.append(tuple(d.loc[indexs].values[:])) # 评分与日期连接 转换为tuple然后统计相同元素个数
print("有效评分总数量为:", len(score_list), " 条")
for i in set(list(score_list)):
result[i] = score_list.count(i) # dict类型,统计相同日期相同评分对应数
info = []
for key in result:
score = key[0] # 取分数
date = key[1] # 日期
value = result[key] # 数量
info.append([score, date, value])
info_new = pd.DataFrame(info) # 将字典转换成为数据框
info_new.columns = ['score', 'date', 'votes']
info_new.sort_values('date', inplace=True) # 按日期升序排列df,便于找最早date和最晚data,方便后面插值
# 以下代码用于插入空缺的数据,每个日期的评分类型应该有10种,依次遍历判断是否存在,若不存在则往新的df中插入新数值
mark = 0
creat_df = pd.DataFrame(columns=['score', 'date', 'votes']) # 创建空的dataframe
for i in list(info_new['date']):
location = info_new[(info_new.date == i) & (info_new.score == 5.0)].index.tolist()
if location == []:
creat_df.loc[mark] = [5.0, i, 0]
mark += 1
location = info_new[(info_new.date == i) & (info_new.score == 4.5)].index.tolist()
if location == []:
creat_df.loc[mark] = [4.5, i, 0]
mark += 1
location = info_new[(info_new.date == i) & (info_new.score == 4.0)].index.tolist()
if location == []:
creat_df.loc[mark] = [4.0, i, 0]
mark += 1
location = info_new[(info_new.date == i) & (info_new.score == 3.5)].index.tolist()
if location == []:
creat_df.loc[mark] = [3.5, i, 0]
mark += 1
location = info_new[(info_new.date == i) & (info_new.score == 3.0)].index.tolist()
if location == []:
creat_df.loc[mark] = [3.0, i, 0]
mark += 1
location = info_new[(info_new.date == i) & (info_new.score == 2.5)].index.tolist()
if location == []:
creat_df.loc[mark] = [2.5, i, 0]
mark += 1
location = info_new[(info_new.date == i) & (info_new.score == 2.0)].index.tolist()
if location == []:
creat_df.loc[mark] = [2.0, i, 0]
mark += 1
location = info_new[(info_new.date == i) & (info_new.score == 1.5)].index.tolist()
if location == []:
creat_df.loc[mark] = [1.5, i, 0]
mark += 1
location = info_new[(info_new.date == i) & (info_new.score == 1.0)].index.tolist()
if location == []:
creat_df.loc[mark] = [1.0, i, 0]
mark += 1
location = info_new[(info_new.date == i) & (info_new.score == 0.5)].index.tolist()
if location == []:
creat_df.loc[mark] = [0.5, i, 0]
mark += 1
info_new = info_new.append(creat_df.drop_duplicates(), ignore_index=True)
score_list = [] # 重置score_list
info_new = info_new[~(info_new['score'] == 0.0)] # 剔除无评分的数据
info_new.sort_values('date', inplace=True) # 按日期升序排列df,便于找最早date和最晚data,方便后面插值
for index, row in info_new.iterrows(): # 第二种遍历df的方法
score_list.append([row['date'], row['votes'], row['score']])
tr = ThemeRiver('《流浪地球》观众评论走势与时间的关系-河流图', '数据来源:猫眼电影 数据分析:16124278-王浩', **style_size.init_style) # 河流图初始化
tr.add([5.0, 4.5, 4.0, 3.5, 3.0, 2.5, 2.0, 1.5, 1.0, 0.5], score_list, is_label_show=True,
is_more_utils=True) # 设置参数
page.add_chart(tr) # 加入渲染队列
attr, v1, v2, v3, v4, v5, v6, v7, v8, v9, v10 = [], [], [], [], [], [], [], [], [], [], []
attr = list(sorted(set(info_new['date'])))
bar = Bar('《流浪地球》观众评论走势与时间的关系-横向柱状图', '数据来源:猫眼电影 数据分析:16124278-王浩', **style_others.init_style) # 初始化图表
for i in attr:
v1.append(int(info_new[(info_new['date'] == i) & (info_new['score'] == 5.0)]['votes']))
v2.append(int(info_new[(info_new['date'] == i) & (info_new['score'] == 4.5)]['votes']))
v3.append(int(info_new[(info_new['date'] == i) & (info_new['score'] == 4.0)]['votes']))
v4.append(int(info_new[(info_new['date'] == i) & (info_new['score'] == 3.5)]['votes']))
v5.append(int(info_new[(info_new['date'] == i) & (info_new['score'] == 3.0)]['votes']))
v6.append(int(info_new[(info_new['date'] == i) & (info_new['score'] == 2.5)]['votes']))
v7.append(int(info_new[(info_new['date'] == i) & (info_new['score'] == 2.0)]['votes']))
v8.append(int(info_new[(info_new['date'] == i) & (info_new['score'] == 1.5)]['votes']))
v9.append(int(info_new[(info_new['date'] == i) & (info_new['score'] == 1.0)]['votes']))
v10.append(int(info_new[(info_new['date'] == i) & (info_new['score'] == 0.5)]['votes']))
bar.add(5.0, attr, v1, is_stack=True)
bar.add(4.5, attr, v2, is_stack=True)
bar.add(4.0, attr, v3, is_stack=True)
bar.add(3.5, attr, v4, is_stack=True)
bar.add(3.0, attr, v5, is_stack=True)
bar.add(2.5, attr, v6, is_stack=True)
bar.add(2.0, attr, v7, is_stack=True)
bar.add(1.5, attr, v8, is_stack=True)
bar.add(1.0, attr, v9, is_stack=True)
bar.add(0.5, attr, v10, is_stack=True, is_convert=True, is_more_utils=True, xaxis_max=45000)
page.add_chart(bar)
line = Line('《流浪地球》观众评论走势与时间的关系', '数据来源:猫眼电影 数据分析:16124278-王浩', **style_others.init_style) # 初始化图表
line.add(5.0, attr, v1, is_stack=True, mark_line=["average"])
line.add(4.5, attr, v2, is_stack=True, mark_line=["average"])
line.add(4.0, attr, v3, is_stack=True, mark_line=["average"])
line.add(3.5, attr, v4, is_stack=True, mark_line=["average"])
line.add(3.0, attr, v5, is_stack=True, mark_line=["average"])
line.add(2.5, attr, v6, is_stack=True, mark_line=["average"])
line.add(2.0, attr, v7, is_stack=True, mark_line=["average"])
line.add(1.5, attr, v8, is_stack=True, mark_line=["average"])
line.add(1.0, attr, v9, is_stack=True, mark_line=["average"])
line.add(0.5, attr, v10, is_stack=True, is_convert=False, mark_line=["average"], is_more_utils=True,
yaxis_max=45000)
page.add_chart(line)
page.render("./output/观众评论与日投票-走势图.html") # 渲染
print("观众评论走势与时间的关系已完成!!!")
# 绘制词云
def draw_wordCloud(comments):
print("数据量较大,正在分词中,请耐心等待......")
data = comments['content'] # 获取评论内容
comment_data = []
for item in data:
if pd.isnull(item) == False:
comment_data.append(item)
comment_after_split = jieba.cut(str(comment_data), cut_all=False) # jieba分词
words = ' '.join(comment_after_split) # 连接分词
backgroud_Image = plt.imread('./input/worldcloud_sample.jpg') # 设置词云背景图
# 自定义停用词
stopwords = STOPWORDS.copy()
with open('./input/stopwords.txt', 'r', encoding='utf-8') as f: # 打开文件读取停用词
for i in f.readlines():
stopwords.add(i.strip('\n'))
f.close()
# 字体路径
wc = WordCloud(width=1024, height=768, background_color='white',
mask=backgroud_Image, font_path="C:\simhei.ttf",
stopwords=stopwords, max_font_size=500,
random_state=80) # 设置词云参数
wc.generate_from_text(words) # 传入关键词
img_colors = ImageColorGenerator(backgroud_Image) # 取背景图色彩
wc.recolor(color_func=img_colors) # 给词云上色美化
# plt.figure(figsize=(10, 8))
plt.imshow(wc) # 设置参数
plt.axis('off') # 关闭坐标轴显示
plt.savefig('./output/WordCloud.png', dpi=300) # 保存高清打印图片
plt.show() # 展示
if __name__ == "__main__":
start_time = datetime.datetime.now()
filename = "./input/Comments.csv"
titles = ['nickName', 'cityName', 'content', 'score', 'startTime']
comments = read_csv(filename, titles)
draw_map(comments)
draw_bar(comments)
draw_DateBar(comments)
draw_TimeBar(comments)
draw_score(comments)
draw_sentiment_pic(comments)
draw_wordCloud(comments)
end_time = datetime.datetime.now()
print("全部完成!!!")
print('程序运行用时(秒):', (end_time - start_time).seconds)
4情感分析介绍
4.1数据处理(深一步)
通过Comments_Group.py,对爬虫获取的54万条再做进一步的预处理,后删除掉2万余条数据,再除去影评内容空格,换行,制表符等会对后面模型数据导入产生影响的符号后,根据评分将评论数据分为中评好评和差评(judgeRank(score)),10000条数据用做测试集,10000条数据用作验证集,剩余的503046条有效数据用作训练集输出,并根据影评内容常用字典(5000字)便于文字id化。

在模型开始训练,对数据id进行id化,利用comments_loader.py中的build_vocab()根据影评数据提取影评中的常用5000字构建词汇表,然后根据["好评", "中评", "差评 "]制作分类目录,建立一个类别和id的字典;一句词汇表建立词汇目录,为每一条影评中的每个字建立一个id,将每一条影评数据id化。
4.2 CNN与LSTM,RGU模型建立
CNN模型以及参数储存在Cnn_Model.py中,LSTM模型GRU模型和参数统一储存在Rnn_Model.py中,均基于tesorflow构建网络。
考虑到做文本情感分析,本文中采用的CNN模型为一层卷积层加最大池化层以及一层全连接层的配置,后面接dropout避免过拟合以及relu激活,采用交叉熵作为损失函数,AdamOptimizer作为优化器更新整个网络。

同样的,LSTM模型与GRU模型由各自的lstm核与gru和构建,双层组装,基于时序分析,利用dynamic_rnn()取最后一个时序输出作为结果输出后,同样接dropout避免过拟合以及relu激活,采用交叉熵作为损失函数,AdamOptimizer作为优化器更新整个网络分别完成LSTM模型与GRU模型的构建。

4.3 模型训练(以LSTM模型为例)
在Run_Rnn.py中根据预先设置好的参数初始化LSTM模型后,(训练产生的模型输出至./checkpoints,日志记录输出的参数记录保存至./tesorboard)开始训练。
配置TensorBoard和Saver保存可视化参数,载入训练集与验证集,利用添加的process_file()函数对载入的数据进行归一化处理使数据得以输入,即使用keras提供的 pad_sequences来将文本pad为固定长度,取每句影评后max_length个字,取不到的地方则置为0,并将将标签转换为one-hot编码表示。
设置实时数据显示后,开始模型训练,该模型在验证集上的准确率到达98%以上或者超过600轮未提升,则提前结束训练。
4.4 模型验证(以CNN和GRU模型为例)
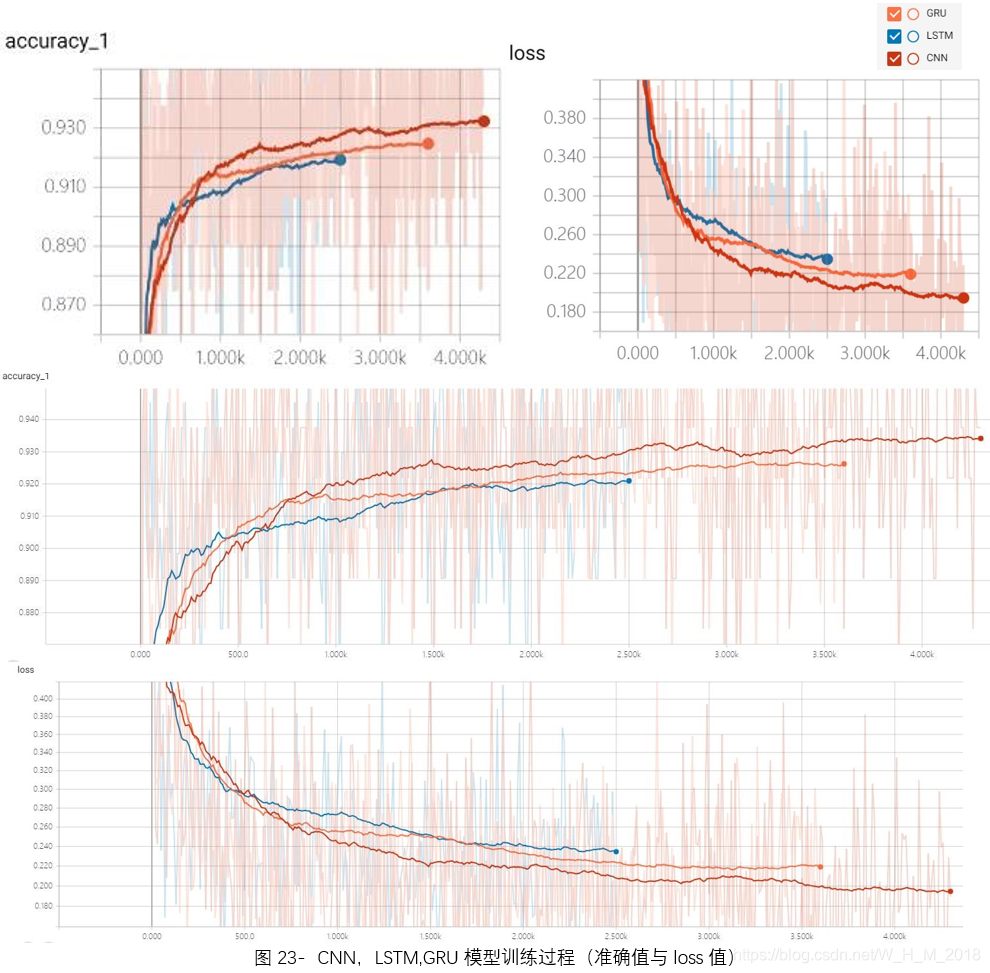
CNN模型与LSTM,GRU模型在最终测试集的准确率相差不大,在参数调优并长时间训练之后,在验证集最高的准确率也仅仅在93%左右,测试集则徘徊在92%左右,召回率,F1均值也相差无几,这三个模型均在好评准确率很高,而在中评和差评和处的准确率较低,从混淆矩阵的输出结果也可以看出,训练出的模型对中差评力不从心。


4.5 实验结果分析
三个模型的最终效果接近,尤其是本应好于CNN的LSTM与GRU模型在部分测试中甚至不敌CNN,这是由于,影评单条数据量不大,文字内容普遍在20字左右,很难让拥有记忆性的LSTM和GRU模型的优势发挥出来,如果文本内容时整篇文章形式的长文本,LSTM和GRU应该会有更好的表现。
中差评效果不好是因为数据样本太少,尽管总数据很大,但,其中,中差评数量占比极低,样本的不充裕导致模型的“偏科”。
