随着人们的社交活动、消费习惯、工作内容也逐渐由线下转移到线上,从互联网上海量文本中自动挖掘出人们对各类事务的需求、喜好、观点、态度等,具有广阔的应用场景和很高的商业价值。
在自然语言处理领域,情感分析是一种从文本中自动抽取该文本中表达的对某些实体(比如产品、服务、话题、事件等)的情感、观点、态度的技术。情感分析主要分为三个级别【1】:(1)句子级别的情感分析(Sentiment Analysis),(2)属性级别的情感分析(Aspect—based Sen-timentAnalysisABSA), (3)文档级别的情感分析(Document-level SentimentAnalysis)。
句子级别的情感分析是一种判断带有情感倾向的句子的情感倾向是积极、消极还是中立的技术。
属性级情感分析是一种自动从原始文本中抽取出实体在不同属性的情感信息的技术。属性级情感分析对评论文本进行比句子级别的情感分析更细粒度的打分,对目标实体的属性进行抽取、并对不同属性分别进行情感分析。
文档级情感分析是一种从多属性多情感的文本中,根据不同属性的情感评分,对实体目标进行综合打分的技术。
属性级情感分析和其他两种情感分析技术的区别在于,属性级情感分析预测
的是实体的不同属性分别对应的情感极性,而不是模糊地分析句子或文档级别的总体极性。
1 数据分析及处理
本次使用的代码来自https://github.com/12190143/Deep-Learning-for-Aspect-Level-Sentiment-Classification-Baselines。在此对Jie Zhou, Jimmy Huang, Qin Chen, Tingting Wang, Qinmin Vivian Hu, and Liang He等作者表示感谢。
1.1 数据分析
本次使用了两个数据集restaurant14和laptop14,两者都为全英文的数据集,前者有2500左右的样本,后者为2000左右,通过大致的统计分析,发现Positive类标签在数据集中占有较大的比重。
从内容上看,属性级情感分析可以看成一个“三类”问题:Positive、Negative和Neutral,即判断某语句是中性的、积极的或消极的。因此,各种分类方法可以用于属性级情感分析。
然而,与文档级和语句级的情感分类不同,属性级情感分析同时考虑了情感信息和目标信息(情感一般都会有一个目标)。如前所述,目标通常是一个实体或实体特征。出于简洁性,实体和实体特征通常都称为属性(aspect)。给定一个句子和目标特征,属性级情感分析情感分类可以推断出句子在目标特征的情感极性倾向。例如,句子「the screen is very clear but the battery life is too short.」中,如果目标特征是「screen」,则情感是积极的,如果目标特征是「battery life」,则情感是消极的【1】。
1.2 数据处理
通过对数据集的分析,根据其特殊性,进行了一些预处理。
1.2.1预处理
数据决定了模型的上限,在实际应用中对数据进行清洗是非常必要的。常用的清洗数据的方法有:去掉停用词、去掉URL、去掉HTML标签、去掉特殊符号、去掉表情符号、去掉长重复字、将缩写补全、去掉单字、提取词干等等。
在约4500条符合规范的样本中,每条样本都有三行第一行为正文,正文部分中会有格式为“ T T T”的Term的位置信息。第二行为Term,第三行则为标签信息。于是对样本进行了处理,将Term替换入正文,得到完整文本信息,随后进行特殊符号替换,大小写转换等处理。
1.2.2建立数据集
因为样本邮件多为完整的句段,故需要对样本文本建立可将文本和数字相互对应的词典。
在字典部分,分别构建了单词对应数字和数字对应单词的两个字典;在词嵌入部分,使用Word2Vec算法,根据词和数字的对应关系,构建了词嵌入矩阵。
最后,将文本转换为文本向量,将构建的多种文本向量以及情感分别存放,再将所有数据合并,获得最后输入模型的待选输入。
2 使用的方法
2.1 LSTM和GRU
2.1.1 LSTM
长短期记忆(Long short-term memory, LSTM)是一种特殊的RNN,主要是为了解决长序列训练过程中的梯度消失和梯度爆炸问题。简单来说,就是相比普通的RNN,多了一个门(gate)机制和细胞记忆单元(cell-state)用来存储,所以LSTM能够在更长的序列中有更好的表现。
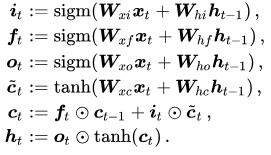

相较之下AT-LSTM模型中加入了Aspect Embedding,与经过LSTM模型训练后的神经元【2】。类似的,ATAE-LSTM的改进就不在此赘述了。
2.1.2 BiLSTM
虽然LSTM解决了RNN会发生梯度消失或者梯度爆炸的问题,但是LSTM只能学习当前词之前的信息,不能利用当前词之后的信息,由于一个词的语义不仅与之前的历史信息有关,还与当前词之后的信息也有着密切关系, BiLSTM 代替LSTM既解决了梯度消失或者梯度爆炸的问题,又能充分考虑当前词的上下文信息。
BiLSTM结合了序列起点移动的一个循环神经网络和令一个从序列末尾向序列起点移动的循环神经网络。而作为循环神经网络的一种拓展,LSTM 自然也可以结合一个逆向的序列,组成双向长短时记忆网络Bi-LSTM。
2.1.3 GRU
GRU (Gate Recurrent Unit)是LSTM网络的一种效果很好的变体,它较LSTM网络的结构更加简单,而且效果也很好。
在LSTM中引入了三个门函数:输入门、遗忘门和输出门来控制输入值、记忆值和输出值。而在GRU模型中只有两个门:分别是更新门和重置门。这两个门控向量决定了哪些信息最终能作为门控循环单元的输出。这两个门控机制的特殊之处在于,它们能够保存长期序列中的信息,且不会随时间而清除或因为与预测不相关而移除。同样地,将双向BiLSTM中的LSTM替换成GRU结构,则组成了BiGRU,就不在此赘述了。
2. 2 其他方法
2.2.1 CNN
CNN本质上是一个多层感知机,其被广为使用的原因关键在于它所采用的局部感受野和共享权值的方式,一方面减少了的权值的数量使得网络易于优化,另一方面降低了过拟合的风险。其是神经网络中的一种,它的权值共享网络结构使之更类似于生物神经网络,降低了网络模型的复杂度,减少了权值的数量。CNN还有一个重要思想就是池化,池化层通常接在卷积层后面,引入它的目的就是为了简化卷积层的输出【3】。
2.2.2 MemNet和IAN
与LSTM不同,这种方法在推断某个方面的情感属性时明确捕获每个上下文词的重要性。这样的重要性程度和文本表示是用多个计算层计算的。restaurants14和Laptop14上的实验表明,该方法明显优于 LSTM架构。此外,该方法也很快。比LSTM 快 15 倍,且模型更稳定,在分析极性情感时更鲁棒【4】。

3 数据分析
3.1 所采用的模型
分别对restaurants14和Laptop14构造生成的数据集采用以下几种方法进行分类处理:
Ⅰ: LSTM、AT-LSTM和BiLSTM等
Ⅱ: GRU、AT-GRU和BiGRU等
Ⅲ: CNN
Ⅳ: RAM
Ⅴ: MemNet
Ⅵ: IAN
3.2 实验数据分析
3.2.1 restaurants14数据集训练结果
表1:restaurants14数据集分类准确率
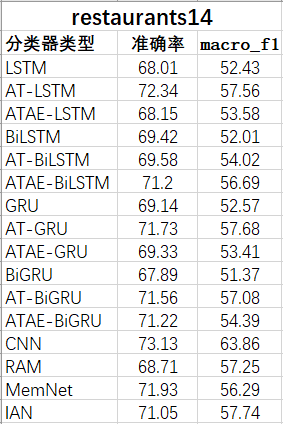 图1:restaurants14数据集分类准确率对比图
图1:restaurants14数据集分类准确率对比图
 3.2.2 Laptop14数据集训练结果
3.2.2 Laptop14数据集训练结果
表2:Laptop14数据集分类准确率
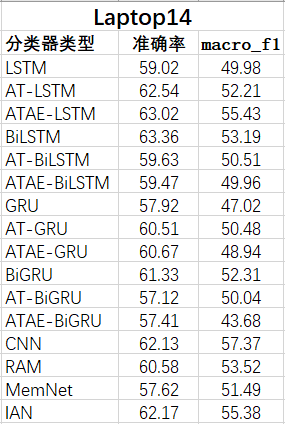
图2:Laptop14数据集分类准确率对比图

4 总结
4.1 数据集获取
由于在上一次实验中发现词袋模型有着或多或少的缺陷,相比之下词嵌入往往有更加优越的表现,故本次实验主要采用了词嵌入的方法。词嵌入的算法很多,其中Word2Vec是比较常用的一种算法。
该模型主要有两种具体的方法,一是在固定窗空间中,通过窗口中上下文的词语来预测目标词语的方法,称为连续词袋模型(continuous bag—of-words model,CBOW), 也就是说,看到一个上下文,希望大概能猜出这个词和它的意思;另一种方法则刚好相反,通过目标词来预测周围邻近词语的模型,称为skip—gram模型,也就是说,给出一个词,希望预测可能出现的上下文的词【5】。
4.2 模型选取
在该次实验中,使用了LSTM、GRU及其变体和CNN、MemNet等模型进行多种尝试,并进行了对比。可以在添加更深更复杂的网络、融合多个模型的预测结果和调整训练的超参数这几个方面做出改进。
4.3 模型训练
在训练中,我只对训练集进行了简单的处理,但本次数据集的特点是Positive类标签数量明显多于其他,导致了样本比例的失调,这对模型训练不利,导致了模型对Positive类有了一种不健康的选择倾向。
4.3 总体
通过对实验结果的分析,在restaurant14数据集上:由于基于attention的算法加入了aspect-embedding以及注意力模型,表现较好;但由于数据集的特性问题,restaurant的情感较为表层,而ATAE算法偏向于挖掘更深层的信息,因此将一些与情感无关的词判断为更深层的潜在情感,降低了准确率。
在Laptop14数据集上,因为该数据集有更多隐式表达情感的样本,故ATAE算法拥有了比基于attention的算法较为出色的表现。
参考文献
[1] Lakhwani K . Deep Learning for Sentiment Analysis. 2018.
[2] Wang Y , Huang M , Zhu X , et al. Atten-tion-based LSTM for Aspect-level Sentiment Classification[C]// Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing. 2016.
[3] 李洋, 董红斌. 基于CNN和BiLSTM网络特征融合的文本情感分析[J]. 计算机应用, 2018, 38(11):6.
[4] Tang D , Qin B , Liu T . Aspect Level Sen-timent Classification with Deep Memory Net-work[C]// 2016.
[5] 吴禀雅, 魏苗. 从深度学习回顾自然语言处理词嵌入方法[J]. 电脑知识与技术, 2016, 12(036):184-185.