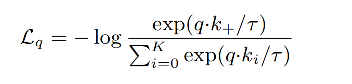一、有监督学习
有监督学习最大的特点就是数据集是带标签的,如有监督分类任务,就是给每张图都分配一个真实标签,表示这张图是 dog、cat 或者是 bird。
而标签的作用就是指导模型训练,告诉模型这是哪个类别
常见算法:分类、回归
二、半监督学习
在实际应用中,获得大量带高质量标签的数据是费时费力的,且有些稀缺样本是非常昂贵的
于是就出现了半监督学习,就是一部分数据带标签,一部分数据不带标签,通过对带标签数据的训练,然后预测出无标签数据的伪标签来进行有监督训练。
三、无监督学习
深度学习中无监督学习的分类:
- 生成式学习:由数据生成数据,使之在整体或者高级语义上与训练数据相近
- GAN
- VAE
- 对比式学习:不需要关注实例上繁琐的细节,只需要在抽象语义级别的特征空间上学会对数据的区分即可,因此模型以及其优化变得更加简单,且泛化能力更强。
无监督训练最大的特征就是数据没有标签,顾七学习的目标是通过这些无标签的样本来学习数据内在的特征和规律。
无监督最大的特点就是能从一堆动物中将狗分到一个类别中,但却不知道它们是狗
典型的算法就是聚类,聚类就是将相同的一类距离拉近,将不同类的数据距离拉远。
自监督学习:
自监督学习是一种特殊的无监督学习方法,利用辅助任务(pretask)从大规模的无监督数据中挖掘自身的监督信息,来自动生成标签或者特征,从而进行模型训练,其实主要是预训练,将训练好的模型进行迁移或微调后,能解决特定的任务。
自监督学习主要有如下三类:
- 基于上下文
- 基于时序
- 基于对比
3.1 对比式学习
对比学习是自监督学习/无监督学习中的一种形式
对比学习的核心:
- 不需要类别标签信息
- 需要代理任务(人为设置的一些规则,数据增强最常用)来定义那些样本是相似的,也就是提供了一个监督信号来训练模型
- 需要实现的就是将同类目标距离拉近,将不同类目标的距离拉远
有监督学习流程:
- 输入 x,通过模型计算输出 y
- 对模型输出 y 和真实label 计算损失
- 梯度反传指导模型训练
对比学习的范式:代理任务+目标函数
- 代理任务:解决没有标签的问题,即使用代理任务来定义对比学习的正负样本,对同一个样本 x,经过两个代理任务分别生成两个样本,一般都使用数据增强,如图片随机裁剪、颜色变换、高斯模糊等,生成的这两个样板就是一组正样本对儿
- 特征提取编码器 f ( . ) f(.) f(.):对这组样本对儿中的两个样本经过同一个编码器,得到两组特征
- MLP:MLP 的输出会用来计算孙函数
- 损失函数:使用 infoNCE loss,分子计算正样本对儿的距离,分母计算负样本对儿的距离,当正样本对儿距离越小,负样本对儿距离越大,损失越小