1.过拟合(overfitting)
1)定义
过拟合:如果有很多特征变量,则训练出来的假设函数模型会对训练样本拟合的很好,但是对于新加入的数据,假设函数模型不能拟合的很好,又称为High Variance。
欠拟合:则是假设函数不能对训练样本进行很好的拟合,又称为High Bias。
2)如何处理过拟合:
1>减少特征变量的数量(但是这样也减小了数据的信息)
手动减小特征变量数量
利用算法自动减小特征变量数量
2>正则化算法
正则化算法主要是保留所有特征变量,但是对所有参数加上权重限制每个参数的贡献度。
当有许多特征,而且每个特征对预测结果的贡献度都不大时,效果最好。

2.使用正规化算法时的损失函数(cost function)
1)加入正则化项
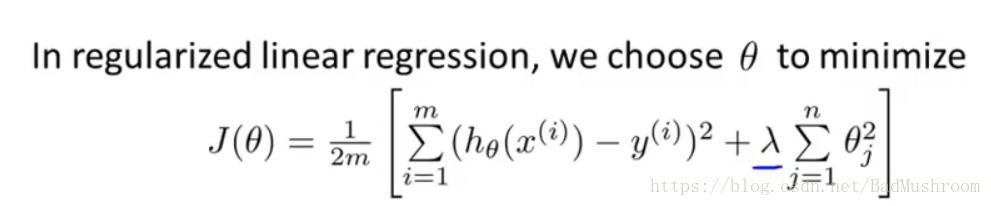
选择好正规化参数λ:
λ过大,则对于参数的惩罚就会增大,使得参数接近0,使得假设函数模型变得过于简单,就会出现欠拟合问题。
λ过小,则对于参数的惩罚就会影响不大,原模型复杂,使得假设函数模型变得过于复杂,就会出现过拟合问题。
注:θ0不在正规化项计算中,不惩罚θ0。
在接下来的课程中将会介绍一些算法用于正则化参数。
3.使用正规化算法避免过拟合在线性回归中的应用
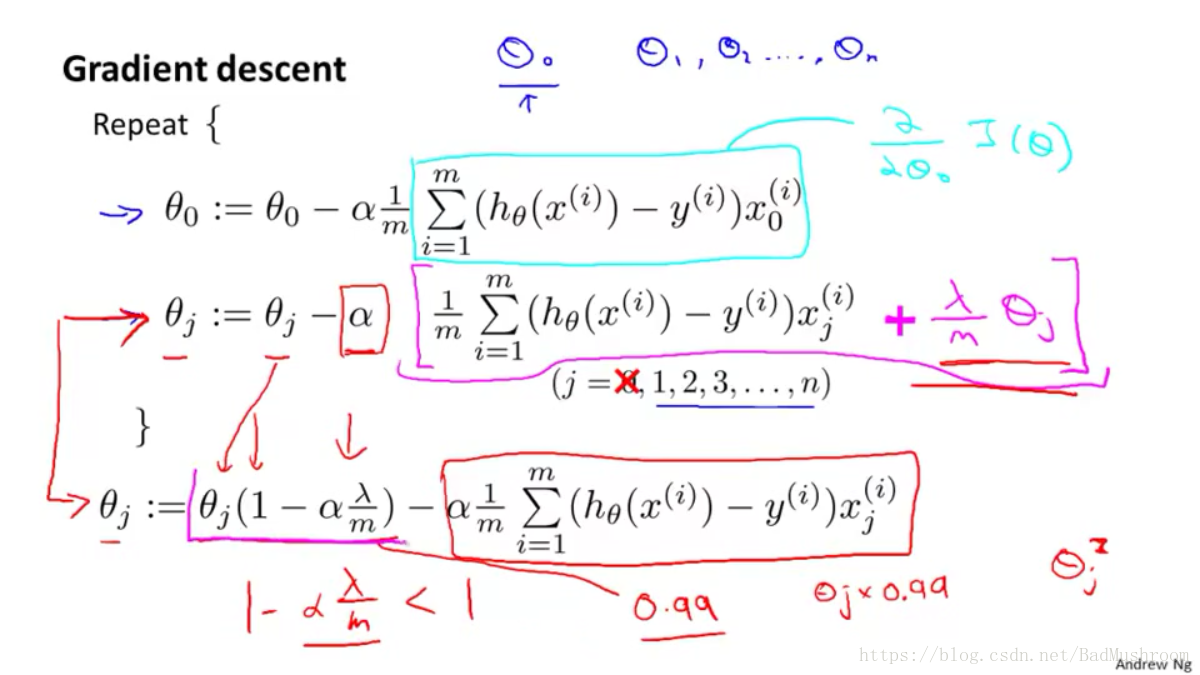
1)梯度下降法
2)正规方程法
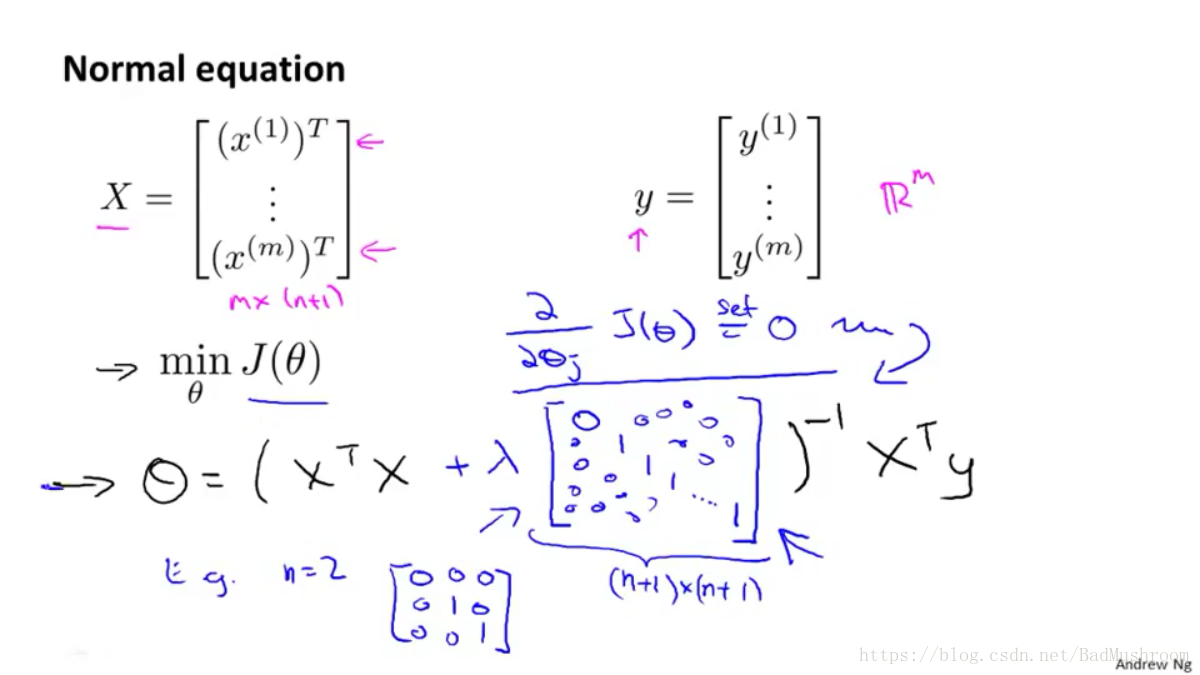

不可逆情况
当不使用正则化项时,利用正规方程解算线性回归模型时,且当m≤n时,就会出现XTX不可逆的问题,所以此时不能利用正规方程进行求解。但是当加入了正则化项时,就不存在这个问题。

4.使用正规化算法避免过拟合在逻辑回归中的应用
1)梯度下降法

2)高级优化算法
