Bayesian Optimization 贝叶斯优化在无需求导的情况下,求一个黑盒函数的全局最优解的一系列设计策略。(Wikipedia)
最优解问题
最简单的,获得最优解的方法,就是网格搜索Grid Search了。
如果网格搜索开销稍微有点大,可以尝试随机搜索Random Search。
如果是凸函数Convex Function,我们可以用Gradient Descent。大量的机器学习算法,都用了这个。如线性回归,逻辑回归等。
如果,这个黑盒函数的开销非常大,又不是凸函数,我们则考虑贝叶斯优化。
贝叶斯优化概念
贝叶斯优化我们把这个黑盒函数叫做目标函数Objective Function。因为目标函数的开销大,我们要给他找一个近似函数,这个函数叫代理函数Surrogate Function。代理函数会计算出一条平均值曲线和对应的标准差(Standard Deviation)。有个代理函数,我们就可以找到一下个探索点。这个过程,用一个获取函数Acquisition Function里实现。
贝叶斯优化,是在一个特定的搜索空间search space展开的。
整个过程如下:
- 在搜索空间中,选几个初始点X
- 用目标函数计算初始点X对应的解y
- 更新代理函数
- 通过acquisition function获得下一个样本点。
- Goto 2
中英文流程图如下:
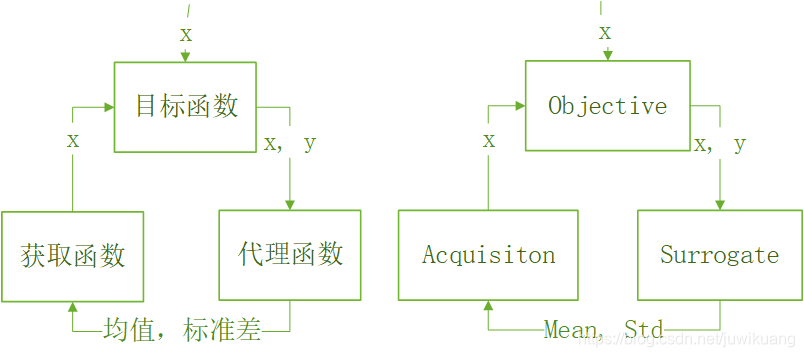
代理函数,一般就是用Gussian Process。
Acquisition Function的选择比较多。常见的有:
- Probability of Improvement (PI).
- Expected Improvement (EI).
- Upper/Lower Confidence Bound (LCB/UCB).
这里我们用 UCB.
,是权重,调节平均值和标准差的重要程度。这是一个 exploitation vs exploration的问题。平均值为exploitation,标准差为exploration。
代码
首先,我们定义搜索空间为[0,1],目标函数为:
def objective(x):
return ((x-0.47)**2 * math.sin(3 * x))
如下图
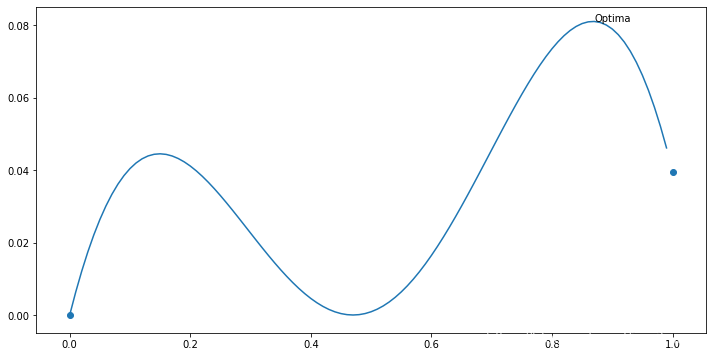
这里,我故意弄了两个局部最优,这样,就不能用Gradient Decent求解了。
代理函数,直接用了sklearn里面的Gussian Process
surrogate = GaussianProcessRegressor()
Acquisition 函数,用了UCB。beta这里就不研究了。
#uppper confidence bound
#beta = 1
def acquisition(X, surrogate):
yhat, std = surrogate.predict(X, return_std=True)
yhat=yhat.flatten()
upper=yhat+std
max_at=np.argmax(upper)
return X[max_at]
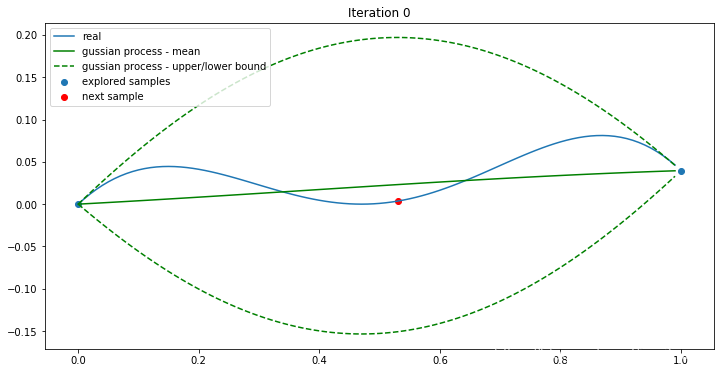
初始的时候,样本选择了搜索空间的两个极值。即[0,1]。这时,代理函数是一条直线,std中间大,两边小。acquisition 函数选择了0.55(上面那条虚线的最大值,投影到目标函数)作为下一个探索点。
这时,我们有了三个样本点了。代理函数和下一个样本点(next sample)如下:
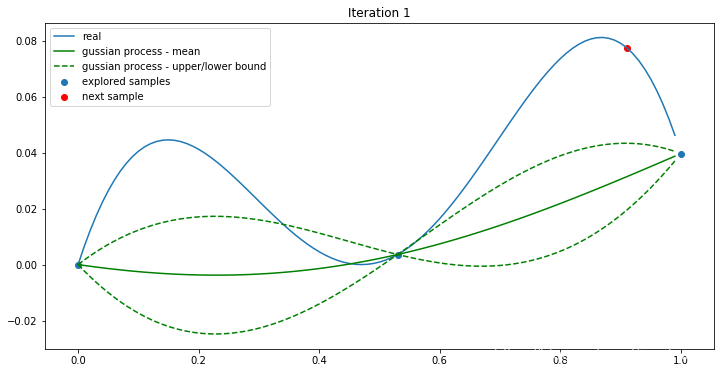
继续迭代:
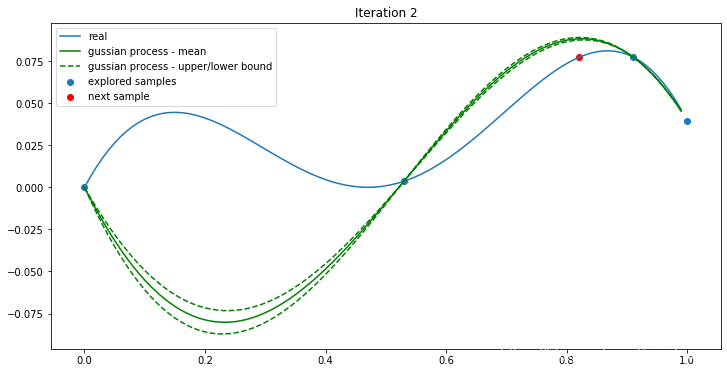
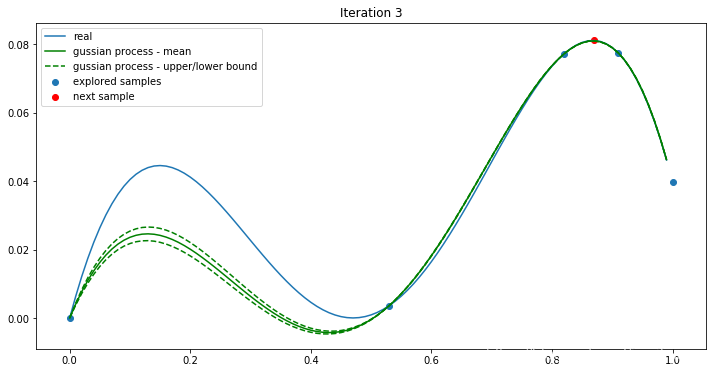
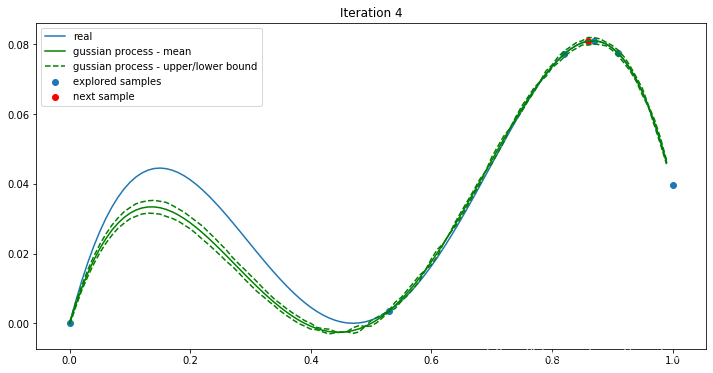
经过四次迭代,我们找到了最大值0.0811051。
用Hyperopt解Bayesian Optimization
Hyperopt只能求最小值,我们在目标函数前面加个负号就行了。
from hyperopt import fmin, tpe, hp
best = fmin(
fn=lambda x:-objective(x),
space=hp.uniform('x', 0, 1),
algo=tpe.suggest,
max_evals=100)
print(best)
一百次迭代以后的最大值是0.08111392201180685
源代码地址:
https://github.com/juwikuang/machine_learning_step_by_step/blob/master/bayesian_optimization.ipynb
项目地址:
