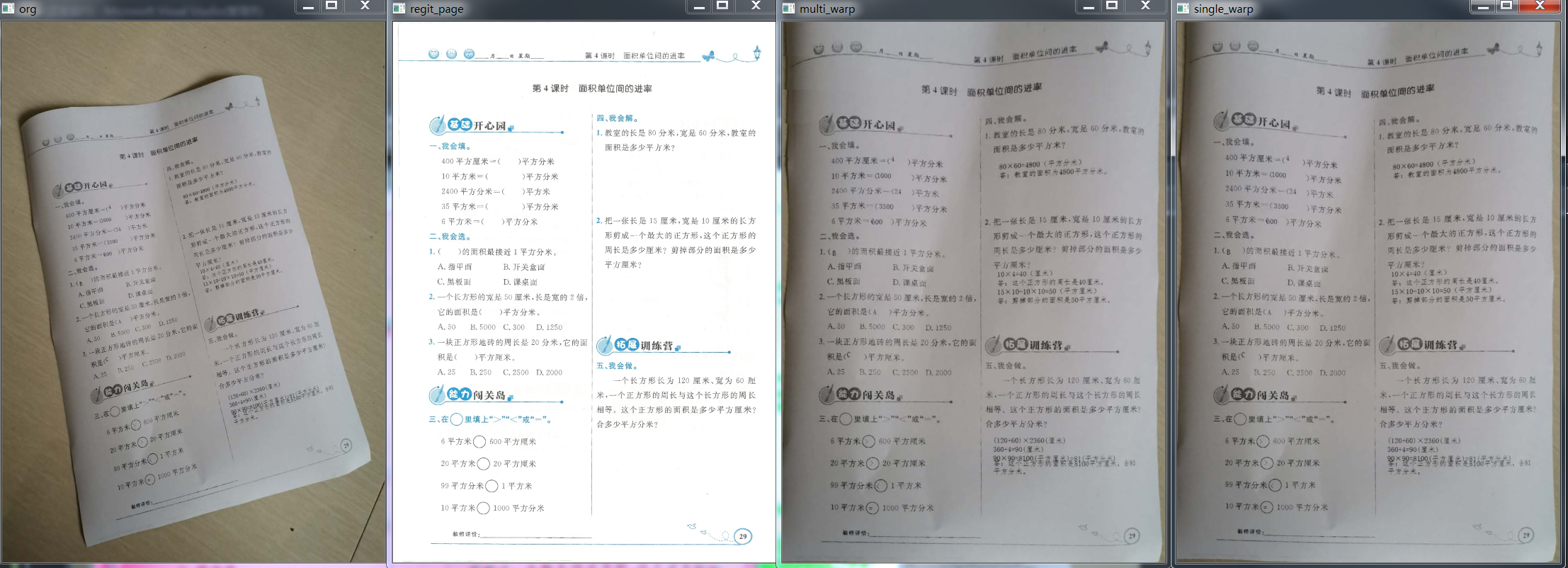
近年来,AI教育被提上日程。衍生很多应用。
题型识别,口算题自动批改,搜题等等,都有成品出现,也圈了很多用户。
落实到教学上,介入更多的人工标注信息,作业本自动批改也是一大块蛋糕。其中自然有页面检索,页面对齐,答题区域提取,OCR,批改逻辑等等技术,细节很多,做好不易。
前文提及了"as-projective-as-possible image stitching with moving DLT",个人推荐应用到页面对齐上,可以优化对齐质量,为后续操作打好基础。最直接的理由,页面虽是平面,实际手机拍照中,没有扫描版压平,总是展示为近似平面,单一的homography处理这个问题误差大,多homography精度较高。
这个问题在页面检索之后,也就是用户上传一张图片,已经检索到对应的注册页面的情况下(如下图),我们得考虑页面对齐,达成标注信息与用户答题信息关联。

 ho
ho
有了页面对,借助特征点匹配技术,放宽映射误差,利用单映射矩阵筛选;
同时也可以辅助“GMS:grid-based motion statistics for fast ultra-robust feature correspondence” 技术来快速筛选候选特征点对, https://github.com/JiawangBian/GMS-Feature-Matcher。

有了特征点对,最简单就是直接拟合单一的homo,然后直接映射矫正,我们可以看到页面有扭曲,单一的homography视目标为严格平面,所以误差自然会大一些。多homo则是把页面划分成诸多小个格子,每个格子有自己的homo,局部格子比整体页面更将接近平面假设,故而获得更低的误差。理论上格子可以细化成1x1像素,代价是需要拟合WXH那么多homo,拟合的精度依赖特征点对的精度,当某一片特征点对很稀疏,且距离其最近的特征点对误差比较大时,此时获取的homo也误差大。这也是实际中无法完美调整的最根本理由。我们无法根据带误差的特征点来拟合精确的homo阵,实现完美映射。
我们只能说多homo方法较单homo更具普适性。
如下图(左:256个homo阵,右:1个homo阵) 绿影越多就是误差越大(示意图:把注册图,与warp图放在不同通道组合而成)

下图给出结果
检验下形变网格,有局部变化,但精度还是不够,理由如前,特征点对误差所致

附:
啰嗦几句,Homo相关的知识,搜索有一大堆,在有很多错误匹配点的时候,需要ransca来获取最大匹配集。之后利用最小二乘法获得。
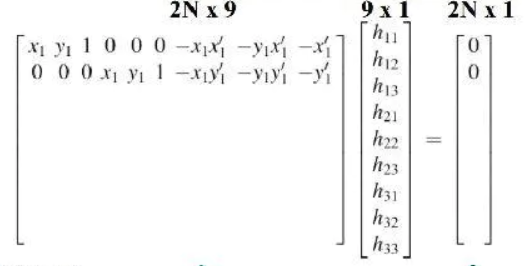
上述记做
Ah = b
常规的利用SVD分解A来获得,SVD的好处可以允许少量错误点,还可以较为准确获得,但速度很慢,如果我们能比较严格筛选获得inlies的点,我们可以利用h33 = 1这个约束来快速求取,特别是需要求解很多Homo的情况,很有必要这么处理。
令
b = [0, 0, 0, 0, 0, 0, 0, 0, 1 ]t
At A h = At b
h = inv(At A) * At b
At A 只是9 x 9 的正定对称阵,上式可以利用cholskey分解快速获取(实现得好,上述解法比SVD快几十倍)
MLTD的核心就是为每个匹配点对分配一个权重,比如利用特点离格子中心的欧式距离来构造,然后让 A = w * A(带上权重),之后还是上述求解即可。
显而易见,这样处理,格子周围的特征点最大程度的影响这个格子的形变,实现了局部形变,同时如果有个特征点错误,也极大的影响着其周边格子的精度。