一、特征降维方法
- 提取主要特征,忽略次要特征【PCA降维】
- 合并相似特征【特征合并】
PCA主成分提取其实还是会忽略掉一些信息,有时候感觉聚类后的结果并不理想,所以如下采用特征合并的方式降维。
二、数据集介绍
- 用到的数据集:
各国发展水平统计信息↓
https://download.csdn.net/download/weixin_43721000/88480791
- 字段解释:
country : 国名
child_mort : 每1000个婴儿的5年死亡率
exports : 人均商品和服务出口,以人均国内生产总值的百分比给出
health : 人均卫生支出总额,以人均国内生产总值的百分比给出
imports : 人均商品和服务进口,以人均国内生产总值的百分比给出
Income : 人均净收入
Inflation : 国内生产总值年增长率的测算(通货膨胀率)
life_expec : 如果按照目前的死亡率模式,新生儿的平均寿命是多少年
total_fer : 如果目前的年龄生育率保持不变,每个妇女生育的孩子数量
gdpp : 人均国内生产总值,计算方法是国内生产总值除以总人口
- 任务类型:
对所有国家发展水平聚类,确定待援助国家,涵盖算法:K-Means、DBSCAN、Hierarchical
三、聚类问题及实现方法
- 该问题主要是根据各国自身特征确定一份待援助国家列表
- 具体做法是:
- 特征标准化
- 合并降维
- kmeans聚类
- 找出待援助国家
四、代码
import time
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
pd.options.display.float_format = '{:.2f}'.format
import warnings
warnings.filterwarnings('ignore')
from sklearn.cluster import KMeans
from sklearn.metrics import silhouette_score
from sklearn.preprocessing import MinMaxScaler, StandardScaler
from mpl_toolkits.mplot3d import Axes3D
import numpy as np
import plotly.express as px
import plotly
class ShowClusterDistribution(object):
@classmethod
def kmeans(cls, df: pd.DataFrame, data_columns: list, class_column: str, centroids: np.array):
'''
绘制聚类分布图
支持2维和3维数据
:param df: 特征缩放后的训练数据和标签组成的df
:param data_columns: 训练数据的列名数组
:param class_column: 标签列名
:param centroids: 质心点坐标
:return:
'''
centroid_color = ['black']
clusters_color = ['red', 'green', 'blue', 'orange', 'yellow']
clusters = set(df[class_column].tolist())
dimension = len(data_columns)
if dimension == 2:
for idx, cluster in enumerate(clusters):
df_class = df[df['Class'] == cluster]
x = np.array(df_class[data_columns[0]])
y = np.array(df_class[data_columns[1]])
plt.scatter(x, y, s=100, c=clusters_color[idx], label=f'Cluster{
idx + 1}')
plt.xlabel(data_columns[0])
plt.ylabel(data_columns[1])
plt.scatter(centroids[:, 0], centroids[:, 1], s=100, c=centroid_color, label='Centroids')
plt.title('Clusters Distribution')
plt.legend()
plt.show()
elif dimension == 3:
fig = plt.figure()
ax = Axes3D(fig, auto_add_to_figure=False)
fig.add_axes(ax)
ax.scatter(centroids[:, 0], centroids[:, 1], centroids[:, 2], marker="X", color=centroid_color)
for idx, cluster in enumerate(clusters):
df_class = df[df['Class'] == cluster]
x = np.array(df_class[data_columns[0]])
y = np.array(df_class[data_columns[1]])
z = np.array(df_class[data_columns[2]])
ax.scatter(x, y, z, c=clusters_color[idx])
plt.title('Clusters Distribution')
ax.set_xlabel(data_columns[0])
ax.set_ylabel(data_columns[1])
ax.set_zlabel(data_columns[2])
plt.show()
def show_elbow_and_silhouette_score(data_values):
'''
1.计算Elbow Method
2.计算Silhouette Score Method
3.绘图
:return:
'''
sse = {
}
sil = []
kmax = 10
fig = plt.subplots(nrows=1, ncols=2, figsize=(15, 5))
plt.subplot(1, 2, 1)
for k in range(1, 10):
kmeans = KMeans(n_clusters=k, max_iter=1000).fit(data_values)
sse[k] = kmeans.inertia_
sns.lineplot(x=list(sse.keys()), y=list(sse.values()))
plt.title('Elbow Method')
plt.xlabel("k : Number of cluster")
plt.ylabel("Sum of Squared Error")
plt.grid()
plt.subplot(1, 2, 2)
for k in range(2, kmax + 1):
kmeans = KMeans(n_clusters=k).fit(data_values)
labels = kmeans.labels_
sil.append(silhouette_score(data_values, labels, metric='euclidean'))
sns.lineplot(x=range(2, kmax + 1), y=sil)
plt.title('Silhouette Score Method')
plt.xlabel("k : Number of cluster")
plt.ylabel("Silhouette Score")
plt.grid()
plt.show()
if __name__ == '__main__':
data = pd.read_csv('./data/Country-data.csv')
print(data.head())
km_columns = ['child_mort', 'health', 'life_expec', 'total_fer', 'imports', 'exports', 'income', 'inflation', 'gdpp']
fig, ax = plt.subplots(nrows=3, ncols=3, figsize=(10, 5))
for i in range(len(km_columns)):
plt.subplot(3, 3, i + 1)
sns.histplot(data[km_columns[i]], color='#FF781F')
plt.show()
ss = StandardScaler(with_mean=0, with_std=1)
df = pd.DataFrame()
data_columns = ['Health', 'Trade', 'Finance']
class_column = 'Class'
health_array = ss.fit_transform(data[['child_mort', 'health', 'life_expec', 'total_fer']])
health_array[:, 0] = -health_array[:, 0]
health_array[:, 3] = -health_array[:, 3]
df[data_columns[0]] = health_array.sum(axis=1)
trade_arry = ss.fit_transform(data[['imports', 'exports']])
trade_arry[:, 0] = -trade_arry[:, 0]
df[data_columns[1]] = trade_arry.sum(axis=1)
finance_arry = ss.fit_transform(data[['income', 'inflation', 'gdpp']])
finance_arry[:, 1] = -finance_arry[:, 1]
df[data_columns[2]] = finance_arry.sum(axis=1)
df.insert(loc=0, value=list(data['country']), column='Country')
print(df.head())
mms = MinMaxScaler()
for data_column in data_columns:
df[data_column] = mms.fit_transform(df[[data_column]])
print(df.head())
data_values = df.drop(columns=['Country']).values
print(data_values)
show_elbow_and_silhouette_score(data_values)
model = KMeans(n_clusters=4, max_iter=1000)
model.fit(data_values)
cluster = model.cluster_centers_
centroids = np.array(cluster)
labels = model.labels_
df[class_column] = labels
ShowClusterDistribution.kmeans(df=df, data_columns=data_columns, class_column=class_column, centroids=centroids)
df['Class'].loc[df['Class'] == 0] = 'Class 1'
df['Class'].loc[df['Class'] == 1] = 'Class 2'
df['Class'].loc[df['Class'] == 2] = 'Class 3'
df['Class'].loc[df['Class'] == 3] = 'Class 4'
fig = px.choropleth(df[['Country', 'Class']],
locationmode='country names',
locations='Country',
title='Needed Help Per Country (World)',
color=df['Class'],
color_discrete_map={
'Class 1': 'Red',
'Class 2': 'Green',
'Class 3': 'Yellow',
'Class 4': 'Blue'
}
)
fig.update_geos(fitbounds="locations", visible=True)
fig.update_layout(legend_title_text='Labels', legend_title_side='top', title_pad_l=260, title_y=0.86)
fig.show(engine='kaleido')
plotly.offline.plot(fig)

|
|
图01,特征分布图
|
|
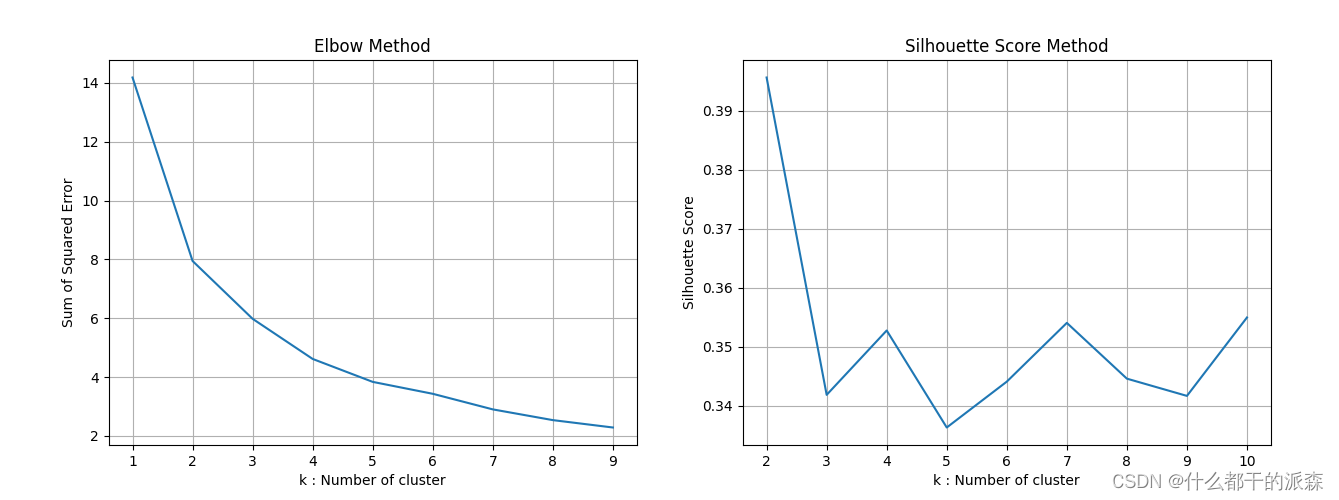
| 图02,Elbow Method 显示 K 值为 2、3、4、5 都可以,Silhouette Score Method 显示 K 值为 2、4、7、10 较合适,综合一下可以选择 2、4,但是因为聚类为 2 的话会产生较多的待援助国家,因此最终选择 K=4 |
|
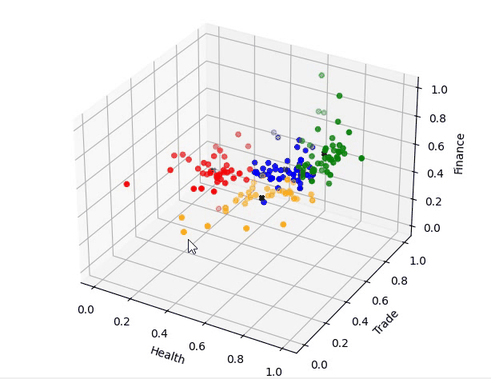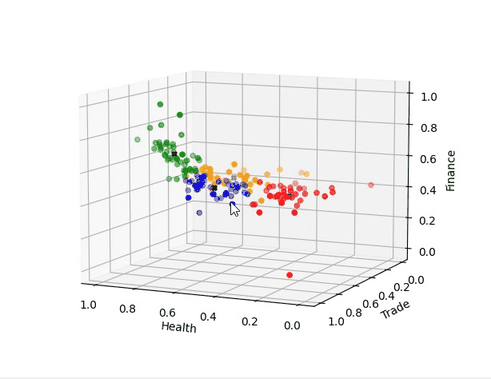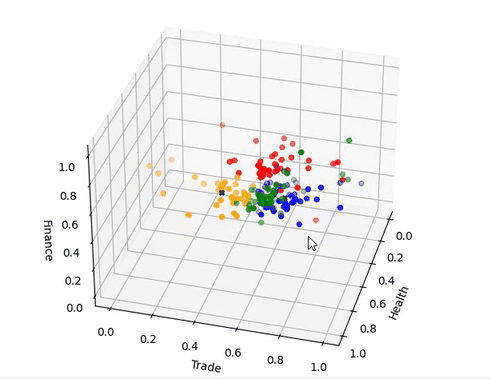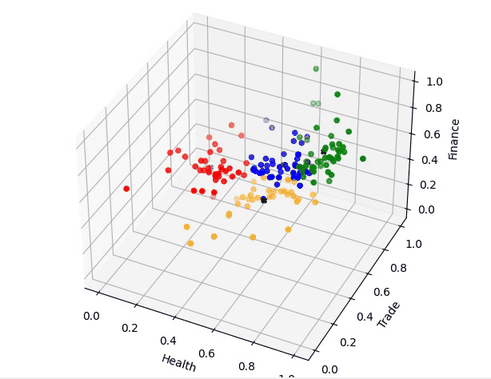
|
|
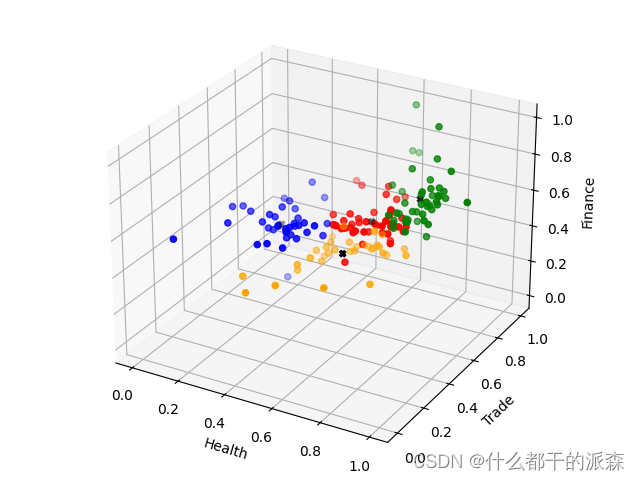
图03,聚类结果
|
图03,聚类结果
|

|
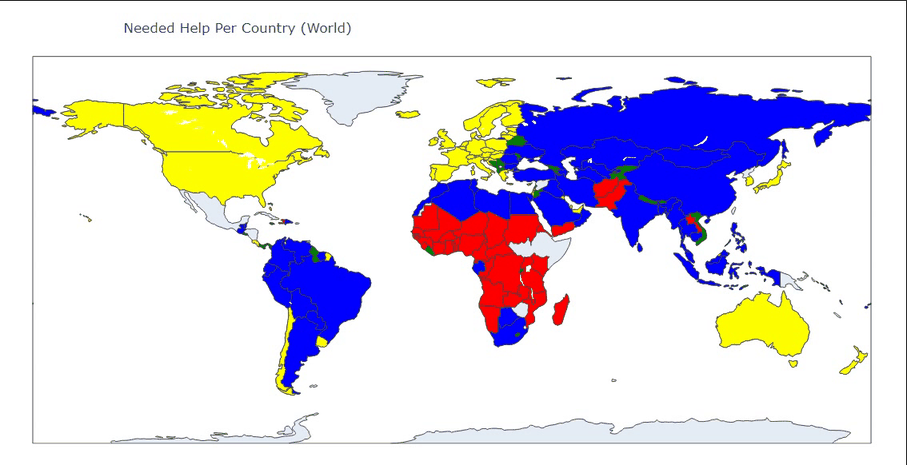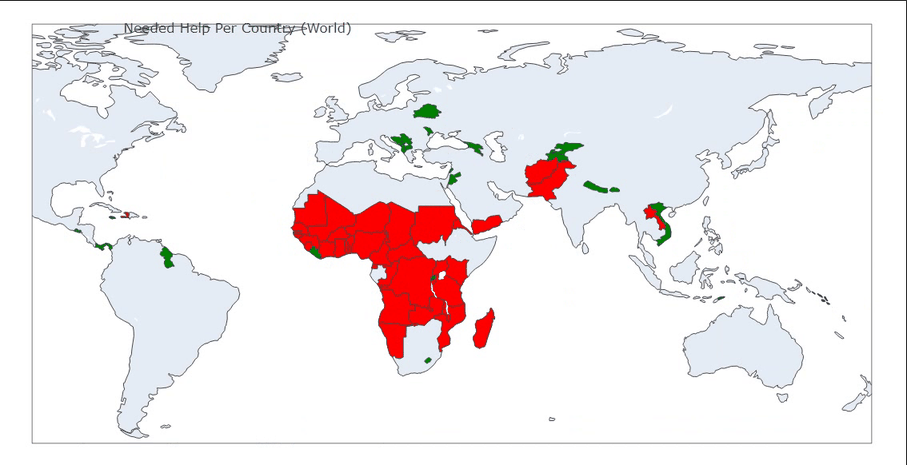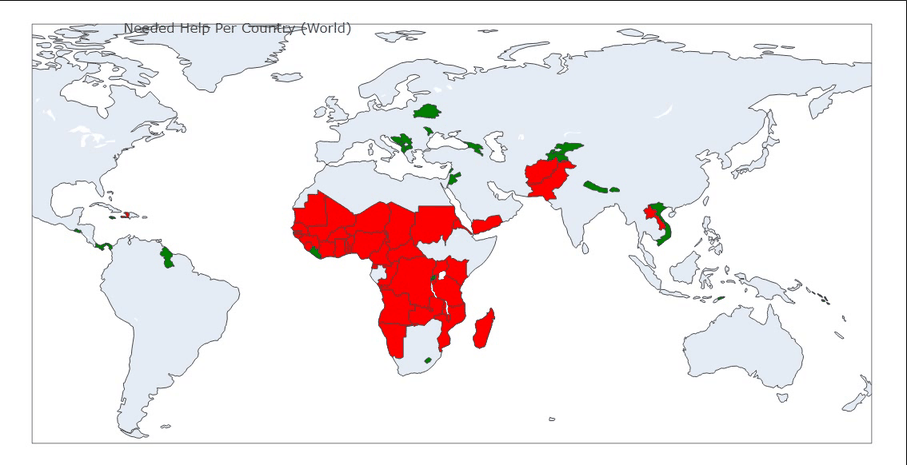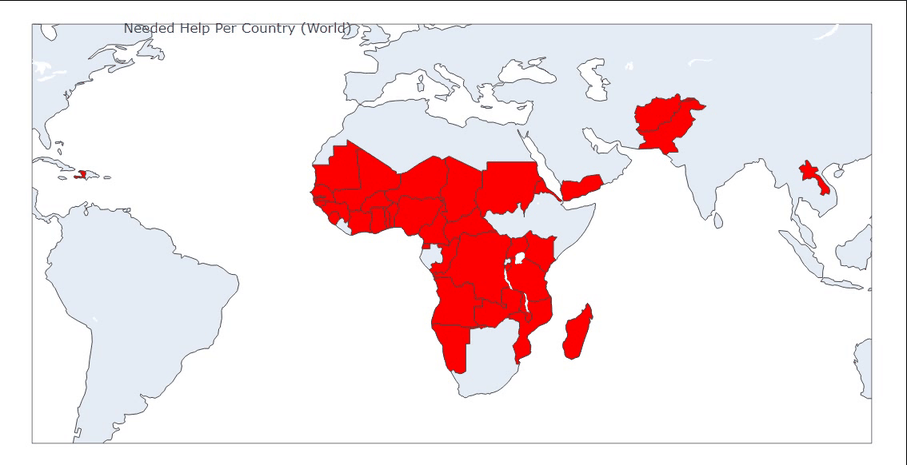
|
图04,地图分布映射,通过地图映射和数据特征基本可以确定待援助优先级为
红色>绿色>蓝色>黄色
|