说明:这篇文章正如标题所说,主要看分析
如果嫌弃文章太长,可以直接通过最后面的小结来选看
快速排序
- 算法思想
快速排序可能是现实应用中最多的一种,但是没有一种排序算法能适应所有的情况,在最糟糕的情况下,快速排序性能就比较差了。但是对于大多数情况下,对于大量的随机数据的排序,快速排序算法的效率还是非常高的。(前提是将快速排序算法实现的小细节实现到位,快速排序的特点是自己编写是容易写错)
它的基本思想是:假设待排序的序列L[1....n],首先选取一个主元pivot,然后将待排序的元素分割成两部分,左边的部分L[1,k-1]小于pivot,右边的部分L[k + 1]大于pivot(其实这是一个很重要的问题:是严格小于还是小于等于,是严格大于还是大于等于)考虑如何具体的实现,后面会说明怎样考虑)。pivot就是放在最终正确的位置k上,这就是一趟排序的过程。然后递归的对两个子序列重复上述的过程,直到只有一个元素或者为空(这两种情况都是有可能发生的,例如考虑{1,2,3,4,5}选取元素3之后,划分为两个子集{1,2},{4,5}继续选取主元2之后划分成{1}和空集,选取主元4之后,划分成{5}和空集)
如图所示:

挑选一个主元,将原来的元素分成两部分。再递归的解决做部分和右部分。最后结果伪码描述:

需要注意的是,主元的选取关乎子集的划分情况进而影响算法的时间复杂度,因此先考虑时间复杂度
Q:主元怎么选?元素怎么分?
首先考虑一下什么是快速排序算法的最好情况?
每次主元正好取到中间,会将元素一分为二。
关于时间复杂度的分析?分析博文
简单说一下就是:
最好的情况下:主元的选取正好能够将划分成左右子集个数相等。
//时间复杂度分析
T(n)≤2T(n/2) +O(n),T(1)=0
T(n)≤2(2T(n/4)+n/2) +n=4T(n/4)+O(2n)
T(n)≤4(2T(n/8)+n/4) +2n=8T(n/8)+O(3n)
……
T(n)≤nT(1)+O((log2n)×n)= O(nlogn)
最差的情况是:主元的选取将子集划分成空集和个数为N-1的子集
//时间复杂度分析
T(n) = O(n) + T(n-1) //其中的O(n)指的是,主元选取之后遍历元素来划分子集。
= O(n) + O(n-1) + T(n-2)
= O(n) + O(n-1) + ... +O(1)
= O(n^2)
然后考虑主元的选择和子集的划分
- 主元选择:
这里只说明了三种情况(你也可以自己通过其他的方法选取主元,尽量能够将子集等分为主,时间复杂度低)
1.选取A[0]
2.随机选取
3.选取3点的中位数
第一种情况,选取最左边的元素。
考虑:数组是完全有序的(好像数据结构书中就是取最左端的元素)

刚开始有N个元素,先选主元A[0],扫描一遍全体以完成子集的划分。时间复杂度为O(N)
然后有N-1个元素,先选主元A[1],扫描一遍全体,完成自己的划分,时间复杂度为O(N-1)
…
这种情况下整个算法的时间复杂度是O(N^2)级别,对于排序算法来说非常糟糕。
数组本身就是有序的,还需要花费O(N-1)级别的时间。
第二种情况,随机取?但是rand()函数也存在一定的开销
第三种情况,取头、中、尾的中位数。

3步的if语句,保证了头、中、尾的次序
此时直接就将中位数返回吗?
并不是。子集划分的时候center在中间,并不需要考虑left和right两个元素。因此交换swap(center,right-1),
此时只需要考虑left+1和right-2之间的元素
- 子集的划分
- 简单的描述一下子集划分的过程:

(在调用完Median3之后)
i->left+1和j->right-2存放指针,主元6‘藏在右边(right-1)’
首先比较i指针指向的元素和主元的大小,发现8>6错误(因为左边存放的是小于主元的元素),此时i就指向这个位置错误的元素,
然后考虑j指针指向的元素7>6,正确,j–左移,j指向2,于是位置错误,此时j就指向这个位置错误的元素
两边发现i和j指向的元素的位置都错误的时候,交换i和j指向的元素交换,然后进行下一轮的比较。

i右移,找到错误位置的元素,
j左移,找到错误位置的元素,
元素交换
…

在这里的时候,5和9交换之后,i++寻找错误位置的元素,i->0正确,i->3正确,会继续i++,此时i ->9发现位置发生错误停下移动,进而移动j,寻找位置错误的元素。
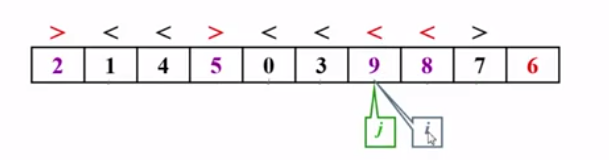
考虑j,j–,左移,此时j->3,发现位置错误停下移动,这个时候应该结束了,是程序的边界i<j这趟划分结束
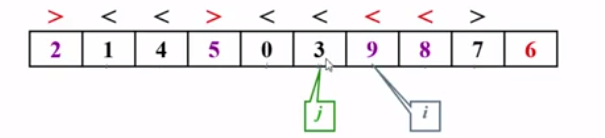
划分结束之后,按着算法的思想,哪里是主元正确的位置呢?有算法的思想知,主元大于左边所有的元素,故主元被放在一趟划分结束之后i的位置(此时i的位置是错误的,i指向第一个比主元大的元素)即将主元与此元素交换,
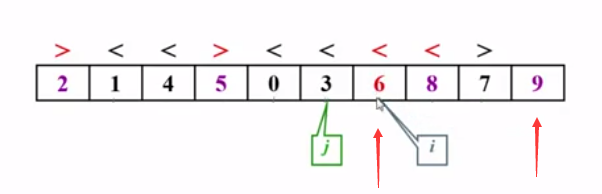
可知此时,此时完成了主元位置的存放和元素的划分
-
为什么快速排序快?
因为每一次元素的划分之后,主元会被放置在最终的正确的位置上,这是一个很重要的原因。
至此,看上去子集的划分看起来并不是很难。 -
接下来考虑几个有趣的问题

-
(1)如果有元素正好等于主元?(这就是考虑到严格的小于还是小于等于)
1.停下来交换?(子集的划分会出现小于等于的情况)
极端情况下,所有元素相等,假设都为1,这个时候会发生什么呢?
首先采取3点取中,得到主元pivot = 1,且主元被藏到右端,i和j指向的元素不断的发生交换。。。。。

会很多无为的交换。但是有一点好处,就是数组被基本等分,在递归的时候会减少时间复杂度NlogN级别。
2.不理它,继续移动指针?(左边严格的小于,右边的大于等于)
此时会发生什么呢?
i不断地右移,此时j指针根本没有机会移动。
避免了很多无用的交换,坏处是主元被移动到端点,时间复杂度高N^2级别。
因此,若考虑时间复杂度(因为时间复杂度是评估效率的很重要的原因)的情况,宁愿选择停下来交换。
- (2)小规模数据的处理
用递归处理:会占用额外的系统堆栈的空间,并且会反复的入栈和出栈操作,每次入栈和出栈很多东西。
小规模的数据可能不如插入排序快。
因此

用递归的时候会占用额外的系统的堆栈的空间(什么情况下在做算法题的时候肯能会挤爆系统分配给长须的堆栈空间导致程序异常),并且会有很多的进展和出栈的操作
使用阈值cutoff来解决 - 算法实现
既然是递归的实现,就需要知道从哪里开始哪里结束,(最右端的下标和最左端的下标)

- 代码实现
1.对Cutoff的5种不同取值:50、100、200、300、400,分别实现快速排序算法:
2.对pivot的3种不同选择办法:直接选A[0]、用随机函数、三元选中值,分别实现快速排序算法:
如何考虑各种情况下的最坏时间复杂度O(N^2)?
对于这几种实现,总能找到最坏的情况,使得时间复杂度为O(N^2);
1.对于主元直接选取A[0]很显然,元素有序或者逆序。
2.用随机函数取主元,若每次都取到最边上的值,使得集合的划分有一个元素个数为0;
3.三元选中值;如果选取的中值正好是最边上的值,使得集合的划分有一个元素个数为0;
总结: 这个一定要看看看看
-
主元的选取最为主要的目的是为了子集的划分平衡,进而减少时间复杂度。不同的主元的选取方法都会存在着最坏的情况。既然都会存在着最坏的情况,主元的选取就是尽量减少最坏情况发生的概率。
-
子集的划分是为了对划分划分的自己继续递归,其需要考虑的因素是面对相等的元素应该如何处理是停下来继续交换还是不理它继续移动指针,这会影响算法的时间复杂度,若为了降低时间复杂度,就采用停下来交换(集体看上面的分析吧)
-
此外,有些初学者,可能会纠结子集的划分是 case1:左边严格小于+右边大于等于还是case2:左边小于等于+右边大于等于,(个人觉着从时间复杂度的分许来看,这个并不是重点,主要是遇到相等的元素如何处理)。
具体来看,如果是case1:考虑极端的情况待排序的元素相同,此时子集的划分就是主元将所有的元素划分成空集和N-1个元素的子集,这时候时间复杂度就是O(N^2),
如果是case2:遇到元素相等就交换和遇到元素不处理指针继续前进都会造成这种情况。 -
小规模数据的处理,这里有很多的讲究,首先是是否需要在小规模数据的处理中使用插入排序(或者说为什么插入排序在小规模的数据中效率高)?如果在小规模的数据处理中使用插入排序,那么多大规模是小?这个都是需要好好考虑的问题?
水平有限,如果出现一些错误,希望指正!一起进步。
